ФПТМ
ЧАбд
ЩЯвЛЦЊЮвУЧжївЊЬжТлСЫ,TCPКЭUDPавщЕФЧјБ№,БОЮФЮвУЧРДЬНЬжМЦЫуЛњЭјТчжаЕФгІгУВу
- гђУћЯЕЭГDNSЁЊЁЊДггђУћНтЮіГіIPЕижЗ
- ЭђЮЌЭјКЭHTTPавщ
- ЕчзггЪМўЕФДЋЫЭЙ§ГЬ,SMTPавщКЭPOP3авщ,IMAPавщЪЙгУЕФГЁКЯ
- ЖЏЬЌжїЛњХфжУавщDHCPЕФЬиЕу
- ЭјТчЙмРэЕФШ§ИізщГЩВПЗж
- ЯЕЭГЕїгУКЭгІгУБрГЬНгПкЕФЛљБОИХФю
- P2PЮФМўЯЕЭГ
DNS
гђУћ,гђУћЕФГіЯжНтОіСЫЮвУЧВЛгУУПЪБУППЬЖММЧТМЭјеОЕФIPЕижЗ,вЊВЛШЛЯждкЭјеОетУДЖр,ЖМШЅгУIPЕижЗЗУЮЪ,ЬЋПМбщШЫЕФМЧвфСІСЫ,гкЪЧашвЊвЛИіЁАРрЫЦгкЕчЛАВОЕФЁБЖЋЮїЁЊЁЊгђУћ,ПЩвдИљОнУћзжРДВщПДIPЕижЗ
DNSдкШеГЃЩњЛюжаЕФживЊад,ОЭЪЧУПИіШЫЩЯЭј,ЖМашвЊЫќ,ЕЋЪЧЭЌЪБ,етЖдЫќРДНВвВЪЧЗЧГЃДѓЕФЬєеНЁЃвЛЕЉЫќГіСЫЙЪеЯ,ећИіЛЅСЊЭјЖМНЋЬБЛОЁЃСэЭт,ЩЯЭјЕФШЫЗжВМдкШЋЪРНчИїЕи,ШчЙћДѓМвЖМШЅЭЌвЛИіЕиЗНЗУЮЪФГвЛЬЈЗўЮёЦї,ЪБбгНЋЛсЗЧГЃДѓЁЃвђДЫ:DNSЗўЮёЦївЛЖЈвЊЩшжУГЩИпПЩгУ,ИпВЂЗЂКЭЗжВМЪНЕФ
БШШч,ЯТУцетеХЪїзДЕФВуДЮНсЙЙ
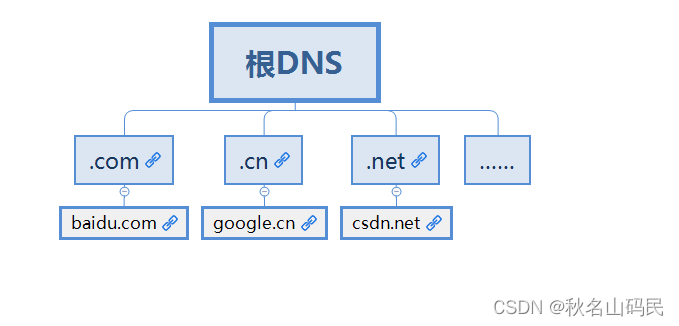
- Иљ DNS ЗўЮёЦї :ЗЕЛиЖЅМЖгђ DNS ЗўЮёЦїЕФ IP ЕижЗЖЅМЖгђ
- DNS ЗўЮёЦї:ЗЕЛиШЈЭў DNS ЗўЮёЦїЕФ IP ЕижЗ
- ШЈЭў DNS ЗўЮёЦї :ЗЕЛиЯргІжїЛњЕФ IP ЕижЗ
DNSНтЮіЙ§ГЬ
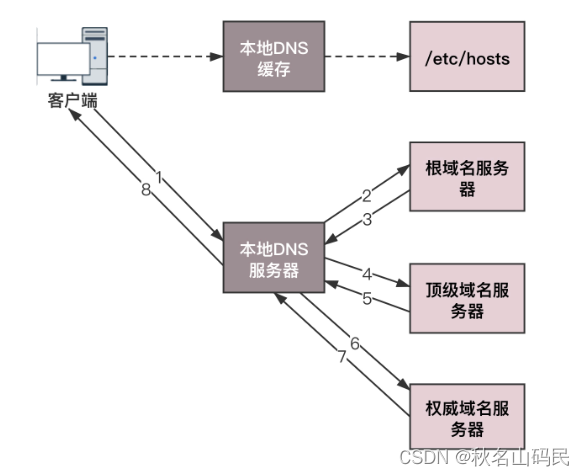
- ЕчФдПЭЛЇЖЫЛсЗЂГівЛИі DNS ЧыЧѓ,ЮЪ www.163.com ЕФ IP ЪЧЩЖАЁ,ВЂЗЂИјБОЕигђУћЗўЮёЦї (БОЕи DNS)ЁЃФЧБОЕигђУћЗўЮёЦї (БОЕи DNS) ЪЧЪВУДФи?ШчЙћЪЧЭЈЙ§ DHCP ХфжУ,БОЕи DNS гЩФуЕФЭјТчЗўЮёЩЬ(ISP),ШчЕчаХЁЂвЦЖЏЕШздЖЏЗжХф,ЫќЭЈГЃОЭдкФуЭјТчЗўЮёЩЬЕФФГИіЛњЗПЁЃ
- БОЕи DNS ЪеЕНРДздПЭЛЇЖЫЕФЧыЧѓЁЃФуПЩвдЯыЯѓетЬЈЗўЮёЦїЩЯЛКДцСЫвЛеХгђУћгыжЎЖдгІ IP ЕижЗЕФДѓБэИёЁЃШчЙћФмевЕН www.163.com,ЫќОЭжБНгЗЕЛи IP ЕижЗЁЃШчЙћУЛга,БОЕи DNS ЛсШЅЮЪЫќЕФИљгђУћЗўЮёЦї:ЁАРЯДѓ,ФмИцЫпЮв www.163.com ЕФ IP ЕижЗТ№?ЁБИљгђУћЗўЮёЦїЪЧзюИпВуДЮЕФ,ШЋЧђЙВга 13 ЬзЁЃЫќВЛжБНггУгкгђУћНтЮі,ЕЋФмжИУївЛЬѕЕРТЗЁЃ
- Иљ DNS ЪеЕНРДздБОЕи DNS ЕФЧыЧѓ,ЗЂЯжКѓзКЪЧ .com,ЫЕ:ЁАХЖ,www.163.com АЁ,етИігђУћЪЧгЩ.com ЧјгђЙмРэ,ЮвИјФуЫќЕФЖЅМЖгђУћЗўЮёЦїЕФЕижЗ,ФуШЅЮЪЮЪЫќАЩЁЃЁБ
- БОЕи DNS зЊЯђЮЪЖЅМЖгђУћЗўЮёЦї:ЁАРЯЖў,ФуФмИцЫпЮв www.163.com ЕФ IP ЕижЗТ№?ЁБЖЅМЖгђУћЗўЮёЦїОЭЪЧДѓУћЖІЖІЕФБШШч .comЁЂ.netЁЂ .org етаЉвЛМЖгђУћ,ЫќИКд№ЙмРэЖўМЖгђУћ,БШШч 163.com,ЫљвдЫќФмЬсЙЉвЛЬѕИќЧхЮњЕФЗНЯђЁЃ
- ЖЅМЖгђУћЗўЮёЦїЫЕ:ЁАЮвИјФуИКд№ www.163.com ЧјгђЕФШЈЭў DNS ЗўЮёЦїЕФЕижЗ,ФуШЅЮЪЫќгІИУФмЮЪЕНЁЃЁБ
- БОЕи DNS зЊЯђЮЪШЈЭў DNS ЗўЮёЦї:ЁАФњКУ,www.163.com ЖдгІЕФ IP ЪЧЩЖбН?ЁБ163.com ЕФШЈЭў DNS ЗўЮёЦї,ЫќЪЧгђУћНтЮіНсЙћЕФдГіДІЁЃЮЊЩЖНаШЈЭўФи?ОЭЪЧЮвЕФгђУћЮвзіжїЁЃ
- ШЈЭў DNS ЗўЮёЦїВщбЏКѓНЋЖдгІЕФ IP ЕижЗ X.X.X.X ИцЫпБОЕи DNSЁЃ
- БОЕиDNSдкНЋIPЕижЗЗЕЛиПЭЛЇЖЫ,ПЭЛЇЖЫКЭФПБъНЈСЂСЌНг
ЯёЯТУцетИіЭМвЛбљ
HTTPавщ
HTTPавщ(ГЌЮФБОДЋЪфавщHyperText Transfer Protocol),ЫќЪЧЛљгкTCPавщЕФгІгУВуДЋЪфавщ,МђЕЅРДЫЕОЭЪЧПЭЛЇЖЫКЭЗўЮёЖЫНјааЪ§ОнДЋЪфЕФвЛжжЙцдђЁЃ
зЂвт:ПЭЛЇЖЫгыЗўЮёЦїЕФНЧЩЋВЛЪЧЙЬЖЈЕФ,вЛЖЫГфЕБПЭЛЇЖЫ,вВПЩФмдкФГДЮЧыЧѓжаГфЕБЗўЮёЦїЁЃетШЁОігыЧыЧѓЕФЗЂЦ№ЖЫЁЃHTTPавщЪєгкгІгУВу,НЈСЂдкДЋЪфВуавщTCPжЎЩЯЁЃПЭЛЇЖЫЭЈЙ§гыЗўЮёЦїНЈСЂTCPСЌНг,жЎКѓЗЂЫЭHTTPЧыЧѓгыНгЪеHTTPЯьгІЖМЪЧЭЈЙ§ЗУЮЪSocketНгПкРДЕїгУTCPавщЪЕЯжЁЃ
HTTP ЪЧвЛжжЮозДЬЌ (stateless) авщ, HTTPавщБОЩэВЛЛсЖдЗЂЫЭЙ§ЕФЧыЧѓКЭЯргІЕФЭЈаХзДЬЌНјааГжОУЛЏДІРэЁЃетбљзіЕФФПЕФЪЧЮЊСЫБЃГжHTTPавщЕФМђЕЅад,ДгЖјФмЙЛПьЫйДІРэДѓСПЕФЪТЮё, ЬсИпаЇТЪЁЃ
ШЛЖј,дкаэЖргІгУГЁОАжа,ЮвУЧашвЊБЃГжгУЛЇЕЧТМЕФзДЬЌЛђМЧТМгУЛЇЙКЮяГЕжаЕФЩЬЦЗЁЃгЩгкHTTPЪЧЮозДЬЌавщ,ЫљвдБиаыв§ШывЛаЉММЪѕРДМЧТМЙмРэзДЬЌ,Р§ШчCookieЁЃ
http url
HTTP URL АќКЌСЫгУгкВщевФГИізЪдДЕФЯъЯИаХЯЂ, ИёЪНШчЯТ:
http://host[":"port][abs_path]
httpЧыЧѓRequest
ПЭЛЇЖЫЗЂЫЭвЛИіHTTPЧыЧѓЕНЗўЮёЦїЕФЧыЧѓЯћЯЂАќРЈвдЯТИёЪН:
ЧыЧѓаа(request line)ЁЂЧыЧѓЭЗВП(header)ЁЂПеааКЭЧыЧѓЪ§ОнЫФИіВПЗжзщГЩЁЃ
httpЯьгІResponse
вЛАуЧщПіЯТ,ЗўЮёЦїНгЪеВЂДІРэПЭЛЇЖЫЗЂЙ§РДЕФЧыЧѓКѓЛсЗЕЛивЛИіHTTPЕФЯьгІЯћЯЂЁЃ
HTTPЯьгІвВгЩЫФИіВПЗжзщГЩ,ЗжБ№ЪЧ:зДЬЌааЁЂЯћЯЂБЈЭЗЁЂПеааКЭЯьгІе§ЮФЁЃ
http5ДѓЬиЕу
- жЇГжПЭЛЇ/ЗўЮёЦїФЃЪН
- МђЕЅПьЫй:ПЭЛЇЯђЗўЮёЦїЧыЧѓЗўЮёЪБ,жЛашДЋЫЭЧыЧѓЗНЗЈКЭТЗОЖЁЃЧыЧѓЗНЗЈГЃгУЕФга
GETЁЂHEADЁЂPOSTЁЃУПжжЗНЗЈЙцЖЈСЫПЭЛЇгыЗўЮёЦїСЊЯЕЕФРраЭВЛЭЌЁЃгЩгкHTTPавщМђЕЅ,ЪЙЕУHTTPЗўЮёЦїЕФГЬађЙцФЃаЁ,вђЖјЭЈаХЫйЖШКмПьЁЃ - СщЛю:HTTPдЪаэДЋЪфШЮвтРраЭЕФЪ§ОнЖдЯѓЁЃе§дкДЋЪфЕФРраЭгЩ
Content-TypeМгвдБъМЧЁЃ - ЮоСЌНг:ЮоСЌНгЕФКЌвхЪЧЯожЦУПДЮСЌНгжЛДІРэвЛИіЧыЧѓЁЃЗўЮёЦїДІРэЭъПЭЛЇЕФЧыЧѓ,ВЂЪеЕНПЭЛЇЕФгІД№Кѓ,МДЖЯПЊСЌНгЁЃВЩгУетжжЗНЪНПЩвдНкЪЁДЋЪфЪБМфЁЃдчЦкетУДзіЕФдвђЪЧЧыЧѓзЪдДЩй,зЗЧѓПьЁЃКѓРДЭЈЙ§
Connection: Keep-AliveЪЕЯжГЄСЌНг - ЮозДЬЌ:
HTTPавщЪЧЮозДЬЌавщЁЃЮозДЬЌЪЧжИавщЖдгкЪТЮёДІРэУЛгаМЧвфФмСІЁЃШБЩйзДЬЌвтЮЖзХШчЙћКѓајДІРэашвЊЧАУцЕФаХЯЂ,дђЫќБиаыжиДЋ,етбљПЩФмЕМжТУПДЮСЌНгДЋЫЭЕФЪ§ОнСПдіДѓЁЃСэвЛЗНУц,дкЗўЮёЦїВЛашвЊЯШЧАаХЯЂЪБЫќЕФгІД№ОЭНЯПьЁЃ
HTTPЕФВЛзу
- ЭЈаХЪЙгУУїЮФ(ВЛМгУм),ФкШнПЩФмЛсБЛЧдЬ§
- ВЛбщжЄЭЈаХЗНЕФЩэЗн,вђДЫгаПЩФмдтгіЮБзА
- ЮоЗЈжЄУїБЈЮФЕФЭъећад,ЫљвдгаПЩФмвбдтДлИФ
ДгЖјв§ГіСЫЮвУЧЯТЮФжаЕФHTTPS
HTTPS
HTTP авщжаУЛгаМгУмЛњжЦ,ЕЋПЩвдЭЈ Й§КЭ SSL(Secure Socket Layer, АВШЋЬзНгВу )Лђ TLS(Transport Layer Security, АВШЋВуДЋЪфавщ)ЕФзщКЯЪЙгУ,МгУм HTTP ЕФЭЈаХФкШнЁЃЪєгкЭЈаХМгУм,МДдкећИіЭЈаХЯпТЗжаМгУмЁЃ
HTTP + МгУм + ШЯжЄ + ЭъећадБЃЛЄ = HTTPS(HTTP Secure )
HTTPS ВЩгУЙВЯэУмдПМгУм(ЖдГЦ)КЭЙЋПЊУмдПМгУм(ЗЧЖдГЦ)СНепВЂгУЕФЛьКЯМгУмЛњжЦЁЃШєУмдПФмЙЛЪЕЯжАВШЋНЛЛЛ,ФЧУДгаПЩФмЛсПМТЧНіЪЙгУЙЋПЊУмдПМгУмРДЭЈаХЁЃЕЋЪЧЙЋПЊУмдПМгУмгыЙВЯэУмдПМгУмЯрБШ,ЦфДІРэЫйЖШвЊТ§ЁЃ
HTTPSЕФВЛзу:
- SSLжЄЪщашвЊШЅ,ЙІФмдНЧПДѓЕФжЄЪщЗбгУдНИп,ИіШЫЭјеОЁЂаЁЭјеОУЛгаБивЊвЛАуВЛЛсгУЁЃ
- SSLжЄЪщЭЈГЃашвЊАѓЖЈIP,ВЛФмдйЭЌвЛIPЩЯАѓЖЈЖрИігђУћ,IPv4зЪдДВЛПЩФмжЇГХетИіЯћКФ(SSLгаРЉеЙПЩвдВПЗжНтОіетИіЮЪЬт,ЕЋЪЧБШНЯТщЗГ,ЖјЧввЊЧѓфЏРРЦїЁЂВйзїЯЕЭГжЇГж,Windows XPОЭВЛжЇГжетИіРЉеЙ,ПМТЧЕНXPЕФзАЛњСП,етИіЬиадМИКѕУЛгУ)ЁЃ
- httpsСЌНгЛКДцВЛШчhttpИпаЇ,ДѓСїСПЭјеОШчЗЧБивЊвВВЛЛсВЩгУ,СїСПГЩБОЬЋИпЁЃ
- httpsСЌНгЗўЮёЦїЖЫзЪдДеМгУИпКмЖр,жЇГжЗУПЭЩдЖрЕФЭјеОашвЊЭЖШыИќДѓЕФГЩБО,ШчЙћШЋВПВЩгУhttps,ЛљгкДѓВПЗжМЦЫузЪдДЯажУЕФМйЩшЕФVPSЕФЦНОљГЩБОЛсЩЯШЅЁЃ
- httpsавщЮеЪжНзЖЮБШНЯЗбЪБ,ЖдЭјеОЕФЯьгІЫйЖШгаИКУцгАЯь,ШчЗЧБивЊ,УЛгаРэгЩЮўЩќгУЛЇЬхбщЁЃ
ЕчзггЪМўЕФДЋЫЭЙ§ГЬ
ЕчзггЪМў,ПЩППЕФДЋЪфЪЧЕквЛЮЛ,ЫљвдЪЙгУTCPавщ,ФПЧАЮвУЧГЃгУЕФSMTPзїЮЊгЪМўЗЂЫЭавщ,ГЃгУЕФPOP3зїЮЊгЪМўЖСШЁавщЁЃSMTPКЭ POP3 (ЛђIMAP)ЖМЪЧЪЙгУTCPСЌНгРДДЋЫЭгЪМўЕФ,ЯТУцЮвУЧЛљгкгЪМўЕФЗЂЫЭКЭНгЪеРДМђЪівЛЯТетМИИіавщ
SMTPавщ
SMTPЙцЖЈСЫдкСНИіЯрЛЅЭЈаХЕФSMTPНјГЬжЎМфгІШчКЮНЛЛЛаХЯЂЁЃгЩгкSMTPЪЙгУПЭЛЇЗўЮёЦїЗНЪН,вђДЫИКд№ЗЂЫЭгЪМўЕФSMTPНјГЬОЭЪЧSMTPПЭЛЇ,ЖјИКд№НгЪегЪМўЕФSMTPНјГЬОЭЪЧSMTPЗўЮёЦїЁЃжСгкгЪМўФкВПЕФИёЪН,гЪМўШчКЮДцДЂ,вдМАгЪМўЯЕЭГгІвдЖрПьЕФЫйЖШРДЗЂЫЭгЪМў,SMTPвВЖМЮДзіГіЙцЖЈЁЃ
SMTPЙцЖЈСЫдкСНИіЯрЛЅЭЈаХЕФSMTPНјГЬжЎМфгІШчКЮНЛЛЛаХЯЂ,ИКд№ЗЂЫЭгЪМўЕФSMTPНјГЬЪЧSMTPПЭЛЇ,ИКд№НгЪегЪМўЕФНјГЬЪЧSMTPЗўЮёЦїЁЃSMTPЙцЖЈСЫ14ЬѕУќСюКЭ21жжгІД№аХЯЂ,змНсЩЯУцЕФМИОф
- ПЭЛЇЖЫ:ЗЂЫЭаХЯЂЕФЗўЮёЦї
- ЗўЮёЖЫ:НгЪеаХЯЂЕФЗўЮёЦї
- ЪЙгУTCPНјааemailаХЯЂЕФПЩППДЋЪф
- ДЋЪфЕФШ§ИіНзЖЮ
- ЮеЪж
- ЯћЯЂЕФДЋЪф
- ЙиБе
- УќСю/ЯьгІНЛЛЅФЃЪН
УќСю(command): ASCIIЮФБО
ЯьгІ(response): зДЬЌДњТыКЭгяОф - EmailЯћЯЂжЛФмАќКЌ7ЮЛASCIIТы
POP3авщ
POP3авщЪЧгЪМўЗУЮЪавщ:ДгЗўЮёЦїЛёШЁгЪМў,гЪОжавщ( Post Office Protocol, POP) ЪЧвЛИіЗЧГЃМђЕЅЕЋЙІФмгаЯоЕФгЪМўЖСШЁавщ,ЯждкЪЙгУЕФЪЧЫќЕФЕк3ИіАцБОPOP3
POP: Post Office Protocol [RFC 1939] ШЯжЄ/ЪкШЈ(ПЭЛЇЖЫ<ЁЊ>ЗўЮёЦї)КЭЯТди
POP3 ВЩгУЕФЪЧЁАРЁБ(Pull)ЕФЭЈаХЗНЪН,ЕБгУЛЇЖСШЁгЪМўЪБ,гУЛЇДњРэЯђгЪМўЗўЮёЦїЗЂГіЧыЧѓ,ЁАРЁБШЁгУЛЇгЪЯфжаЕФгЪМў, ЪзЯШвЊНјааШЯжЄ,ШЛКѓВХПЩвдНјШыЪТЮёНзЖЮ,НјааЛёШЁгЪМў
POPЪЙгУПЭЛЇ/ЗўЮёЦїЕФЙЄзїЗНЪН,дкДЋЪфВуЪЙгУTCP,ЖЫПкКХЮЊ110
POPгаСНжжЙЄзїЗНЪН:ЁАЯТдиВЂБЃСєЁБКЭЁАЯТдиВЂЩОГ§ЁБ
(1)гУЛЇДггЪМўЗўЮёЦїЩЯЖСШЁгЪМўКѓ,гЪМўвРШЛЛсБЃДцдкгЪМўЗўЮёЦїЩЯ,гУЛЇПЩдйДЮДгЗўЮёЦїЩЯЖСШЁИУгЪМў
(2)ЯТдиВЂЩОГ§
гЪМўвЛЕЉБЛЖСШЁ,ОЭБЛДггЪМўЗўЮёЦїЩЯЩОГ§,гУЛЇВЛФмдйДЮДгЗўЮёЦїЩЯЖСШЁ
зЂ:POP3ЪЧЮозДЬЌЕФ
IMAPавщ
вђЬиЭјБЈЮФДцШЁавщ(IMAP), ЫќБШPOPИДдгЕУЖр,IMAPЮЊгУЛЇЬсЙЉСЫДДНЈЮФМўМаЁЂдкВЛЭЌЮФМўМажЎМфвЦЖЏгЪМўМАдкдЖГЬЮФМўМажаВщбЏгЪМўЕФУќСю,ЮЊДЫIMAPЗўЮёЦїЮЌЛЄСЫЛсЛАгУЛЇЕФзДЬЌаХЯЂ
- ЫљгаЯћЯЂЭГвЛБЃДцдквЛИіЕиЗН:ЗўЮёЦї
- дЪаэгУЛЇРћгУЮФМўМазщжЏЯћЯЂ
- MAPжЇГжПчЛсЛА(Session)ЕФгУЛЇзДЬЌ
IMAPдЪаэгУЛЇДњРэжЛЛёШЁБЈЮФЕФФГаЉВПЗж,Р§ШчПЩвджЛЖСШЁвЛИіБЈЮФЕФЪзВП,ЛђвЛИіЖрВПЗжMIMEБЈЮФЕФвЛВПЗжЁЃетЗЧГЃЪЪгУгкЕЭДјПэЕФЧщПі,гУЛЇПЩФмВЂВЛЯыШЁЛигЪЯфжаЕФЫљгагЪМў,гШЦфЪЧАќКЌКмЖрвєЦЕЛђЪгЦЕЕФДѓгЪМў
POP3КЭIMAPЕФЧјБ№
POP3авщдЪаэЕчзггЪМўПЭЛЇЖЫЯТдиЗўЮёЦїЩЯЕФгЪМў,ЕЋЪЧдкПЭЛЇЖЫЕФВйзїгЪМў,ЪЧВЛЛсЗДРЁЕНЗўЮёЦїЩЯ,БШШчЭЈЙ§ПЭЛЇЖЫЖСШЁСЫгЪЯфжаЕФ3ЗтгЪМўВЂвЦЖЏЕНЦфЫћЮФМўМа,гЪЯфЗўЮёЦїЩЯЕФгЪМўВЛЛсИФБф
IMAPЬсЙЉwebmail гыЕчзггЪМўПЭЛЇЖЫжЎМфЕФЫЋЯђЭЈаХ
DHCPЕФЬиЕу
DHCPЪЧЖЏЬЌжїЛњХфжУавщЕФЫѕаДЁЃЫќЪЧвЛжжДцдкгкгІгУВуЕФЭјТчЙмРэавщЁЃдкDHCPЕФАяжњЯТ,ПЩвдЖЏЬЌЕиИјЭјТчЩЯЕФШЮКЮЩшБИЛђНкЕуЗжХфвЛИіЛЅСЊЭјавщIPЕижЗ,ЪЙЫќУЧПЩвдЪЙгУетИіIPНјааЭЈаХЁЃЭјТчЙмРэдБЕФШЮЮёЪЧНЋДѓСПЕФIPЕижЗЪжЖЏЗжХфИјЭјТчжаЕФЫљгаЩшБИЁЃШЛЖј,дкDHCPжа,етИіШЮЮёЪЧздЖЏЛЏЕФ,ЪЧМЏжаЙмРэ,ЖјВЛЪЧЪжЙЄЙмРэЁЃЮоТлЪЧаЁаЭБОЕиЭјТчЛЙЪЧДѓаЭЦѓвЕЭјТчЖМЪЕЯжСЫDHCPЁЃDHCPЕФЛљБОФПБъЪЧЮЊжїЛњЗжХфвЛИіЮЈвЛЕФIPЕижЗЁЃ
ЕБDHCPЗўЮёЦїзїЮЊЗўЮёЦїЪБ,DHCPЗўЮёЦїЪЧгУРДздЖЏЗжХфЮЈвЛЕФIPЕижЗ,ЭЌЪБХфжУЭјТчЕФЦфЫћаХЯЂЁЃдкаЁаЭЦѓвЕЛђМвЭЅжа,DHCPЗўЮёЦїГ§СЫТЗгЩЦїжЎЭт,УЛгаЦфЫћШЮКЮвЛИіЪЧDHCPЗўЮёЦїЁЃШЛЖј,дкДѓаЭЭјТчжа,DHCPЗўЮёЦїПЩвдЪЧвЛЬЈМЦЫуЛњЁЃ
Й§ГЬМђЕЅзмНсШчЯТ:
-
ПЭЛЇЖЫЯђжїЛњЗЂЫЭвЛИіIPЕижЗЧыЧѓЁЃПЭЛЇЖЫПЩвдЪЧШЮКЮЗЂЫЭЧыЧѓЕФЩшБИ,жїЛњПЩвдЪЧТЗгЩЦїЁЃ
-
жїЛњНЋбАеввЛИіПЩгУЕФIPЕижЗВЂЗжХфИјПЭЛЇЖЫЁЃ
-
ЪЙгУетИіIPЕижЗ,ПЭЛЇЖЫОЭПЩвддкЭјТчЩЯНјааЭЈаХЁЃ
гХШБЕу:
гХЕу:
- ПЩвдКмШнвзЕидкЭјТчжаЬэМгаТЕФПЭЛЇЖЫЁЃ
- IPЕижЗЪЧгЩDHCPМЏжаЙмРэЕФЁЃ
- IPЕижЗПЩвджиИДЪЙгУ,ДгЖјМѕЩйСЫЖдIPЕижЗзмЪ§ЕФвЊЧѓЁЃ
- DHCPЗўЮёЦїЩЯЕФIPЕижЗПеМфПЩвдКмШнвзЕиНјаажиаТХфжУ,ЖјВЛашвЊЕЅЖРжиаТХфжУПЭЛЇЖЫЁЃ
- ЭјТчЙмРэдБПЩвдРћгУDHCPавщЬсЙЉЕФЗНЗЈ,ДгМЏжаЧјгђХфжУЭјТчЁЃ
ШБЕу:
? гЩгкЫќЪЧздЖЏЗжХф,ЫљвддкНЋIPЕижЗЗжХфИјВЛЭЌЕФжїЛњЪБ,гаЪБЛсГіЯжIPЕижЗГхЭЛЕФЧщПі
змНс:
ЖЏЬЌжїЛњХфжУавщЪЧвЛИіЗЧГЃЙиМќКЭживЊЕФЭјТчЗўЮё,ЪЧБиаывЊгаЕФ,вђЮЊЪЙгУЫќПЩвдАяжњФузїЮЊвЛИіЯЕЭГЙмРэдБЛђЭјТчЙмРэдБ,ЭЈЙ§ЗжХфЁЂИњзйКЭжиаТЗжХфIPРДДІРэПЭЛЇЖЫЁЃРыПЊЙмРэ,ДЫЭт,ШчЙћгаШЮКЮЮЪЬт,ФужЛашвЊБЃГжгыЗўЮёЦїСЌНг,ВЂбщжЄЩшжУ,ЖјВЛЪЧдкПЭЛЇЖЫжЎМфдЫааЁЃ
ЭјТчЙмРэЕФШ§ИізщГЩВПЗж
МђЕЅЕФРДЫЕ:
- ШєИЩИіжїЛњ,ЫќУЧЯђИїгУЛЇЬсЙЉЗўЮё
- вЛИіЭЈаХзгЭј,ЫќгЩвЛаЉзЈгУЕФНсЕуНЛЛЛЛњКЭСЌНгетаЉНсЕуЕФЭЈаХСДТЗЫљзщГЩЁЃ
- вЛЯЕСаЕФавщЁЃетаЉавщЪЧЮЊдкжїЛњжЎМфЛђжїЛњКЭзгЭјжЎМфЕФЭЈаХЖјгУЕФЁЃ
ЯЕЭГЕїгУКЭгІгУБрГЬНгПкЕФЛљБОИХФю
ЯЕЭГЕїгУНгПк
ДѓЖрЪ§ВйзїЯЕЭГЪЙгУЯЕЭГЕїгУЛњжЦдкгІгУГЬађКЭВйзїЯЕЭГжЎМфДЋЕнПижЦШЈ
ЖдГЬађдБРДЫЕ,ЯЕЭГЕїгУКЭвЛАуГЬађЩшМЦжаЕФКЏЪ§ЕїгУЗЧГЃЯрЫЦ,жЛЪЧЯЕЭГЕїгУЪЧНЋПижЦШЈДЋЕнИјСЫВйзїЯЕЭГ(гУЛЇЬЌ->ФкКЫЬЌ)
гІгУБрГЬНгПк
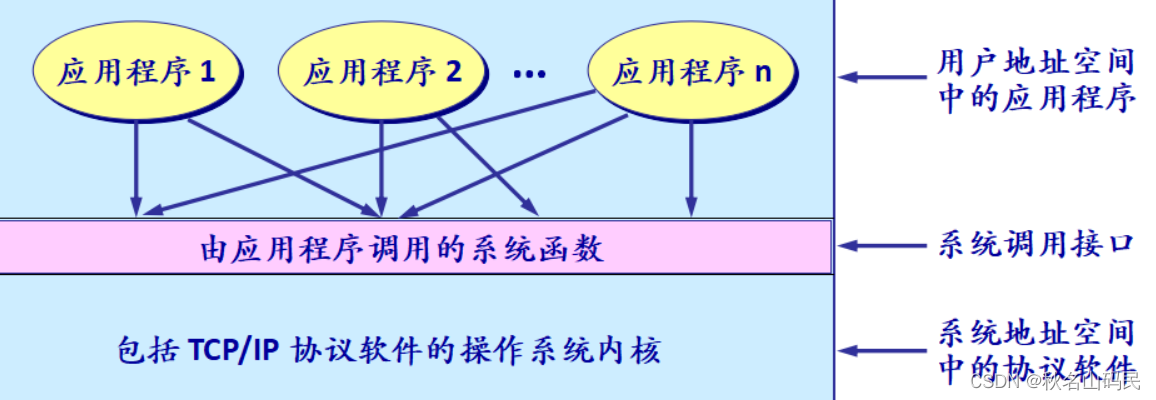
1)зїгУ:гІгУНјГЬЕФПижЦШЈКЭВйзїЯЕЭГЕФПижЦШЈНјаазЊЛЛЕФНгПк
ЂйЕБФГИігІгУНјГЬЦєЖЏЯЕЭГЕїгУЪБ,ПижЦШЈОЭДггІгУНјГЬДЋЕнИјСЫЯЕЭГЕїгУНгПк
ЂкДЫНгПкдйНЋПижЦШЈДЋЕнИјМЦЫуЛњЕФВйзїЯЕЭГ,ВйзїЯЕЭГНЋДЫЕїгУзЊИјФГИіФкВПЙ§ГЬ,ВЂжДааЫљЧыЧѓЕФВйзї
ЂлФкВПЙ§ГЬвЛЕЉжДааЭъБЯ,ПижЦШЈОЭгжЭЈЙ§ЯЕЭГЕїгУНгПкЗЕЛиИјгІгУНјГЬ
P2P
ЕЋЪЧЮоТлЪЧ HTTP ЕФЗНЪН,ЛЙЪЧ FTP ЕФЗНЪН,ЖМгавЛИіБШНЯДѓЕФШБЕу,ОЭЪЧФбвдНтОіЕЅвЛЗўЮёЦїЕФДјПэбЙСІ, вђЮЊЫќУЧЪЙгУЕФЖМЪЧДЋЭГЕФПЭЛЇЖЫЗўЮёЦїЕФЗНЪНЁЃ
КѓРД,вЛжжДДаТЕФЁЂГЦЮЊ P2P ЕФЗНЪНСїааЦ№РДЁЃP2P ОЭЪЧ peer-to-peerЁЃзЪдДПЊЪМВЂВЛМЏжаЕиДцДЂдкФГаЉЩшБИЩЯ,ЖјЪЧЗжЩЂЕиДцДЂдкЖрЬЈЩшБИЩЯЁЃетаЉЩшБИЮвУЧЙУЧвГЦЮЊ peerЁЃ
ЯывЊЯТдивЛИіЮФМўЕФЪБКђ,ФужЛвЊЕУЕНФЧаЉвбОДцдкСЫЮФМўЕФ peer,ВЂКЭетаЉ peer жЎМф,НЈСЂЕуЖдЕуЕФСЌНг,ЖјВЛашвЊЕНжааФЗўЮёЦїЩЯ,ОЭПЩвдОЭНќЯТдиЮФМўЁЃвЛЕЉЯТдиСЫЮФМў,ФувВОЭГЩЮЊ peer жаЕФвЛдБ,ФуХдБпЕФФЧаЉЛњЦї,вВПЩФмЛсбЁдёДгФуетРяЯТдиЮФМў,ЫљвдЕБФуЪЙгУ P2P ШэМўЕФЪБКђ,Р§Шч BitTorrent,ЭљЭљФмЙЛПДЕН,МШгаЯТдиСїСП,вВгаЩЯДЋЕФСїСП,вВМДФуздМКвВМгШыСЫетИі P2P ЕФЭјТч,здМКДгБ№ШЫФЧРяЯТди,ЭЌЪБвВЬсЙЉИјЦфЫћШЫЯТдиЁЃПЩвдЯыЯѓ,етжжЗНЪН,ВЮгыЕФШЫдНЖр,ЯТдиЫйЖШдНПь,вЛЧаЭъУРЁЃ
Р§зг:
етРяОЭвЊАсГіРД,бИРзСЫ,ЮвВЛжЊЕРФуУЧгаУЛгагЁЯѓ,дкЕБЪБАцШЈвтЪЖЛЙВЛЪЧЬиБ№УїШЗЕФЪБКђ,ЯыПДвЛВНЕчгАвВВЛашвЊШЅИїДѓЭјеОевvip,бИРзжжзг,етИідкP2PФЃЪНжаГЦЮЊжжзг(.torrent)ЮФМў
жжзг(.torrent)ЮФМў
жжзг,вВМДдлУЧБШНЯЪьЯЄЕФ.torrent ЮФМўЁЃ.torrent ЮФМўгЩСНВПЗжзщГЩ,ЗжБ№ЪЧ:announce(tracker URL)КЭЮФМўаХЯЂЁЃ
ЮФМўжагаетаЉаХЯЂ:
- info Чј:етРяжИЖЈЕФЪЧИУжжзггаМИИіЮФМўЁЂЮФМўгаЖрГЄЁЂФПТМНсЙЙ,вдМАФПТМКЭЮФМўЕФУћзжЁЃ
- Name зжЖЮ:жИЖЈЖЅВуФПТМУћзжЁЃ
- ЖЮЙўЯЃжЕ:НЋећИіжжзгжа,УПИіЖЮЕФ SHA-1 ЙўЯЃжЕЦДдквЛЦ№ЁЃ
ЯТдиЪБ,BT ПЭЛЇЖЫЪзЯШНтЮі.torrent ЮФМў,ЕУЕН tracker ЕижЗ,ШЛКѓСЌНг tracker ЗўЮёЦїЁЃtracker ЗўЮёЦїЛигІЯТдиепЕФЧыЧѓ,НЋЦфЫћЯТдиеп(АќРЈЗЂВМеп)ЕФ IP ЬсЙЉИјЯТдиепЁЃЯТдиепдйСЌНгЦфЫћЯТдиеп,ИљОн.torrent ЮФМў,СНепЗжБ№ЖдЗНИцжЊздМКвбОгаЕФПщ,ШЛКѓНЛЛЛЖдЗНУЛгаЕФЪ§ОнЁЃДЫЪБВЛашвЊЦфЫћЗўЮёЦїВЮгы,ВЂЗжЩЂСЫЕЅИіЯпТЗЩЯЕФЪ§ОнСїСП,вђДЫМѕЧсСЫЗўЮёЦїЕФИКЕЃЁЃ
ЯТдиепУПЕУЕНвЛИіПщ,ашвЊЫуГіЯТдиПщЕФ Hash бщжЄТы,ВЂгы.torrent ЮФМўжаЕФЖдБШЁЃШчЙћвЛбљ,дђЫЕУїПще§ШЗ,ВЛвЛбљдђашвЊжиаТЯТдиетИіПщЁЃетжжЙцЖЈЪЧЮЊСЫНтОіЯТдиФкШнЕФзМШЗадЮЪЬтЁЃ
ДгетИіЙ§ГЬвВПЩвдПДГі,етжжЗНЪНЬиБ№вРРЕ trackerЁЃtracker ашвЊЪеМЏЯТдиепаХЯЂЕФЗўЮёЦї,ВЂНЋДЫаХЯЂЬсЙЉИјЦфЫћЯТдиеп,ЪЙЯТдиепУЧЯрЛЅСЌНгЦ№РД,ДЋЪфЪ§ОнЁЃЫфШЛЯТдиЕФЙ§ГЬЪЧЗЧжааФЛЏЕФ,ЕЋЪЧМгШыетИі P2P ЭјТчЕФЪБКђ,ЖМашвЊНшжњ tracker жааФЗўЮёЦї,етИіЗўЮёЦїЪЧгУРДЕЧМЧгаФФаЉгУЛЇдкЧыЧѓФФаЉзЪдДЁЃЫљвд,етжжЙЄзїЗНЪНгавЛИіБзЖЫ,вЛЕЉ tracker ЗўЮёЦїГіЯжЙЪеЯЛђепЯпТЗдтЕНЦСБЮ,BT ЙЄОпОЭЮоЗЈе§ГЃЙЄзїСЫЁЃ
ШЅжааФЛЏ
ФЧУДгаУЛгаАьЗЈШЅГ§жааФЛЏ,ЕБtrackerЗўЮёЦїГіЯжЙЪеЯЛђепЯпТЗдтЕНЦСБЮКѓ,BTЙЄОпвВФме§ГЃЙЄзїЕФФи?етЪБОЭвЊв§ГіDHTШЅжааФЛЏЭјТч,УПИіМгШыетИі DHT ЭјТчЕФШЫ,ЖМвЊИКд№ДцДЂетИіЭјТчРяЕФзЪдДаХЯЂКЭЦфЫћГЩдБЕФСЊЯЕаХЯЂ,ЯрЕБгкЫљгаШЫвЛЦ№ЙЙГЩСЫвЛИіХгДѓЕФЗжВМЪНДцДЂЪ§ОнПтЁЃ
етРягаИіавщ:Kademliaавщ,ЮвУЧРДЯъЯИЫЕвЛЯТ
Kademliaавщ
МђЕЅЕФЫЕ,Kad ЪЧвЛжжЗжВМЪНЙўЯЃБэММЪѕ,ШЮКЮвЛИі BitTorrent ЦєЖЏжЎКѓ,ЫќЖМгаСНИіНЧЩЋЁЃвЛИіЪЧ peer,МрЬ§вЛИі TCP ЖЫПк,гУРДЩЯДЋКЭЯТдиЮФМў,етИіНЧЩЋБэУї,ЮветРягаФГИіЮФМўЁЃСэвЛИіНЧЩЋ DHT node,МрЬ§вЛИі UDP ЕФЖЫПк,ЭЈЙ§етИіНЧЩЋ,етИіНкЕуМгШыСЫвЛИі DHT ЕФЭјТчЁЃдк DHT ЭјТчРяУц,УПвЛИі DHT node ЖМгавЛИі IDЁЃетИі ID ЪЧвЛИіКмГЄЕФДЎЁЃУПИі DHT node ЖМгад№ШЮеЦЮевЛаЉжЊЪЖ,вВОЭЪЧЮФМўЫїв§,вВМДЫќгІИУжЊЕРФГаЉЮФМўЪЧБЃДцдкФФаЉНкЕуЩЯЁЃЫќжЛашвЊгаетаЉжЊЪЖОЭПЩвдСЫ,ЖјЫќздМКБОЩэВЛвЛЖЈОЭЪЧБЃДцетИіЮФМўЕФНкЕуЁЃ
ЙўЯЃжЕ
DHT ЫуЗЈЪЧетбљЙцЖЈЕФ:ШчЙћвЛИіЮФМўМЦЫуГівЛИіЙўЯЃжЕ,дђКЭетИіЙўЯЃжЕвЛбљЕФФЧИі DHT node,ОЭгад№ШЮжЊЕРДгФФРяЯТдиетИіЮФМў,МДБуЫќздМКУЛБЃДцетИіЮФМўЁЃ
ЕБШЛВЛвЛЖЈетУДЧЩ,змФмевЕНКЭЙўЯЃжЕвЛФЃвЛбљЕФ,гаПЩФмвЛФЃвЛбљЕФ DHT node вВЯТЯпСЫ,Ыљвд DHT ЫуЗЈЛЙЙцЖЈ:Г§СЫвЛФЃвЛбљЕФФЧИі DHT node гІИУжЊЕР,ID КЭетИіЙўЯЃжЕЗЧГЃНгНќЕФ N Иі DHT node вВгІИУжЊЕРЁЃ
ЪВУДНаКЭЙўЯЃжЕНгНќФи?Р§ШчжЛаоИФСЫзюКѓвЛЮЛ,ОЭКмНгНќ;аоИФСЫЕЙЪ§ 2 ЮЛ,вВВЛдЖ;аоИФСЫЕЙЪ§ 3 ЮЛ,вВПЩвдНгЪмЁЃзмжЎ,ДеЦыСЫЙцЖЈЕФ N етИіЪ§ОЭааЁЃ
дк DHT ЭјТчжа,УПИі node ЖМБЃДцСЫвЛЖЈЕФСЊЯЕЗНЪН,ЕЋЪЧПЯЖЈУЛга node ЕФЫљгаСЊЯЕЗНЪНЁЃDHT ЭјТчжа,НкЕужЎМфЭЈЙ§ЛЅЯрЭЈаХ,вВЛсНЛСїСЊЯЕЗНЪН,вВЛсЩОçьЯЕЗНЪНЁЃКЭШЫУЧЕФЗНЪНвЛбљ,ФугаФуЕФХѓгбШІ,ФуЕФХѓгбгаЫќЕФХѓгбШІ,ФуУЧЛЅЯрМгЮЂаХ,ОЭЛЅЯрШЯЪЖСЫ,Й§вЛЖЮЪБМфВЛСЊЯЕ,ОЭЩОГ§ХѓгбЙиЯЕЁЃ
гаИіРэТлЪЧ,ЩчНЛЭјТчжа,ШЮКЮСНИіШЫжБНгЕФОрРыВЛГЌЙ§СљЖШ,вВМДФуЯыСЊЯЕБШЖћИЧДФ,вВОЭСљИіШЫОЭФмЙЛСЊЯЕЕНСЫЁЃ
Ыљвд,node new ЯыСЊЯЕ node C,ОЭШЅЭђФмЕФХѓгбШІШЅЮЪ,ВЂЧвЧѓзЊЗЂ,ХѓгбдйЮЪХѓгб,КмПьОЭФмевЕНЁЃШчЙћевВЛЕН C,вВФмевЕНКЭ C ЕФ ID КмЯёЕФНкЕу,ЫќУЧвВжЊЕРШчКЮЯТдиЮФМў 1ЁЃдк node C ЩЯ,ИцЫп node new,ЯТдиЮФМў 1,вЊШЅ BЁЂDЁЂ F,гкЪЧ node new бЁдёКЭ node B Нјаа peer СЌНг,ПЊЪМЯТди,ЫќвЛЕЉПЊЪМЯТди,здМКБОЕивВгаЮФМў 1 СЫ,гкЪЧ node new ИцЫп node C вдМАКЭ node C ЕФ ID КмЯёЕФФЧаЉНкЕу,ЮввВгаЮФМў 1 СЫ,ПЩвдМгШыФЧИіЮФМўгЕгаепСаБэСЫЁЃЕЋЪЧФуЛсЗЂЯж node new ЩЯУЛгаЮФМўЫїв§,ЕЋЪЧИљОнЙўЯЃЫуЗЈ,вЛЖЈЛсгаФГаЉЮФМўЕФЙўЯЃжЕЪЧКЭ node new ЕФ ID ЦЅХфЩЯЕФЁЃдк DHT ЭјТчжа,ЛсгаНкЕуИцЫпЫќ,ФуМШШЛМгШыСЫдлУЧетИіЭјТч,ФувВгад№ШЮжЊЕРФГаЉЮФМўЕФЯТдиЕижЗЁЃКУСЫ,вЛЧаЖМЗжВМЪНСЫЁЃ

