引入
面试题:在32位系统下,能否申请1G的内存空间。
对于这个问题我们需要分情况讨论:
- 当物理内存剩余空间大于1G,可以成功。
- 当物理内存剩余空间不足1G,但是加上虚拟内存空闲的空间,大于1G,那么也能成功。
在这里我们引入虚拟内存这个概念,虚拟内存在Linux中十分重要,下面对虚拟内存进行说明。
虚拟内存空间=用户空间+内核空间
内存的管理以及访问控制向来都是非常困难的看,如果直接使用物理内存,通常都会面临以下几种问题:
- 内存缺乏访问控制,安全性不足
- 各进程同时访问物理内存,可能会互相产生影响,没有独立性
- 物理内存极小,而并发执行进程所需又大,容易导致内存不足
- 进程所需空间不一,容易导致内存碎片化问题。
基于上面几种原因,Linux为了解决这些问题,通过mm_struct结构体来描述了一个虚拟的,连续的,独立的地址空间,也就是我们所说的虚拟地址空间。
虚拟地址空间并没有分配实际的物理内存,而当进程需要实际访问内存资源的时候就会
由内核的请求分页机制产生缺页中断,才会建立虚拟地址和物理地址的映射,调入物理内存页。通过这种方法,就能够保证我们的物理内存只在实际使用时才进行分配,避免了内存浪费的问题。
这也是我们可以调用比物理内存大的应用程序的原因;并且虚拟内存是放在磁盘上的。
虚拟地址的内存空间存储:
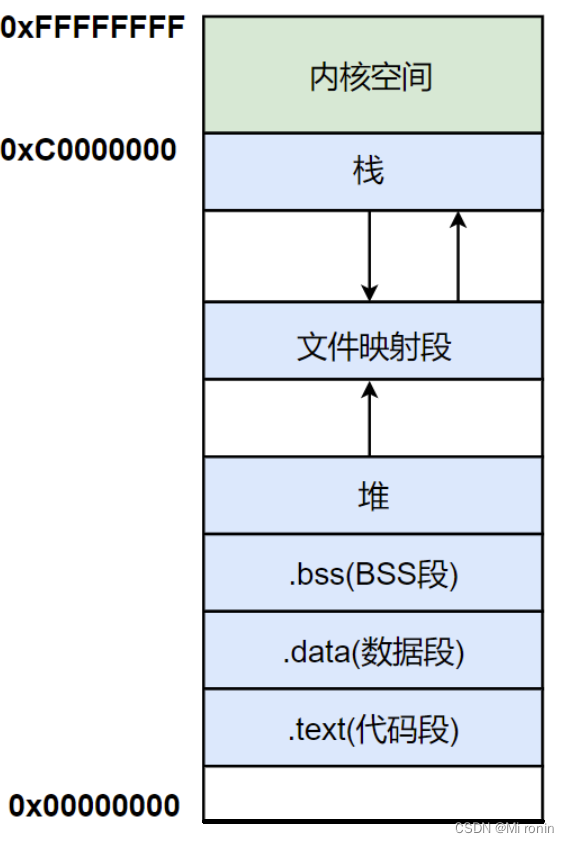
Linux中虚拟内存的存储空间分为:内核空间 + 用户空间
用户空间
用户空间是用户在虚拟空间中可以访问的一部分空间,在32位系统下用户空间的最大存储空间为3G。
面试题接上述引入部分:那么是否可以在32位系统空间下申请3G的内存空间:
答案是不可以的。
但是有人会有疑问了 为什么申请不了呢?这里说的最大存储空间就是3G呀。
原因是:
32位系统下最大使用内存为3G,但是会有一部分呢被软件和硬件所占用,所以就没有3G使用空间。
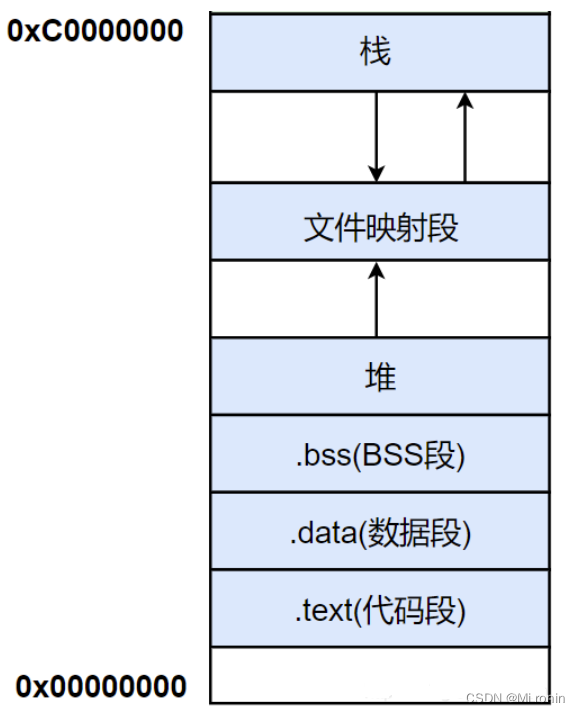
用户空间的组成:
- 栈:用来存放程序中临时创建的局部变量,函数的参数,内部变量等等;每当一个函数被调用时,就会将参数压入进程调用栈中,调用结束后返回值也会被放回栈中。同时,每调用一次函数就会创建一个新的栈,所以在递归较深时容易导致栈溢出。栈内存的申请和释放由编译器自动完成,并且栈容量由系统预先定义。
栈从高地址向低地址增长。 - 文件映射段:也称共享区;主要包括共享内存,动态链接库等共享资源。
文件映射段从低地址向高地址增长。 - 堆:堆用来存放动态分配的内存。堆内存由用户申请分配和释放。
堆从低地址向高地址增长。 - BSS段:BSS段用来存放程序中未初始化的全局变量和静态变量。
- 数据段:数据段用来存放程序中已初始化全局变量与静态变量。
- 代码段:代码段用来存放程序执行代码,也可能包含一些只读的常量。这块区域的大小在程序运行时就已经确定,并且为了防止代码和常量遭到修改,代码段被设置为只读。
用户空间的内存分配
在C语言中我们可以使用malloc来在用户空间中动态的分配内存,而malloc作为库函数,其本质就是对系统调用进行了一层封装,因此在不同的系统下其实现不同。
在Linux中,当我们申请的内存小于128K时,malloc会使用sbrk或者brk在堆区分配内存。而当我们申请大于128K的大块空间时,会使用mmap在映射区进行分配。
但是由于上述的brk/sbrk/mmap都属于系统调用,因此当我们每次调用它们时,就会从用户态切换至内核态,在内核态完成内存分配后再返回用户态。
倘若每次申请内存都要因为系统调用而产生大量的CPU开销,那么性能会大打折扣。如果低地址的内存没有被释放,则高地址的内存就不能被回收,就会产生内存碎片的问题。
malloc是如何实现解决这个问题的呢?
为了减少内存碎片和系统调用的开销,malloc在底层采用了内存池来解决这个问题。
它会先申请大块内存作为堆区,然后将这块内存拆分为多个不同大小的内存块,以块作为内存管理的基本单位。同时,会使用隐式链表来连接所有的内存块,包括已分配块和未分配块。为了方便内存空闲块的管理,malloc采用显式链表来管理所有的空闲块。
当我们调用malloc进行内存分配时,就会去搜索空闲链表,找到满足需求的内存块,如果内存块过大,则会将内存块拆分为两部分,即一部分用来分配,另一部分则变为新的空闲块。
同理,当我们释放内存块时,会通过遍历隐式链表,判断释放块前后内存块是否空闲,来决定是否需要合并内存块
内核空间
内核空间即进程陷入内核态后才能够访问的空间。
虽然每个进程都具有自己独立的虚拟地址空间,但是这些虚拟地址空间中的内核空间 ,其实都关联的是同一块物理内存。
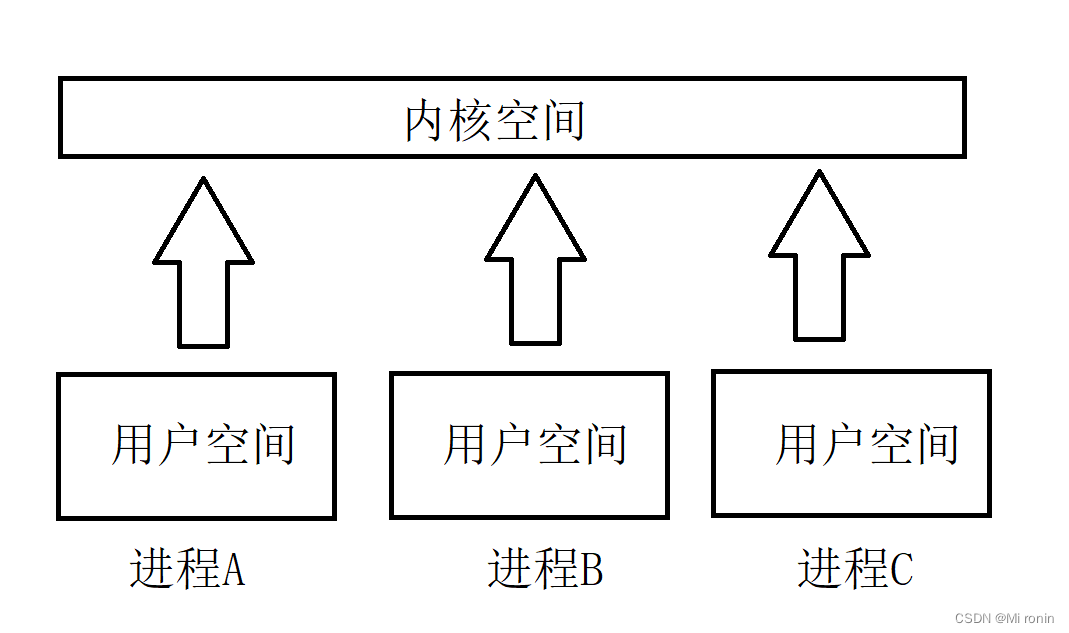
通过这种方法,保证了进程在切换至内核态后能够快速的访问内核空间。
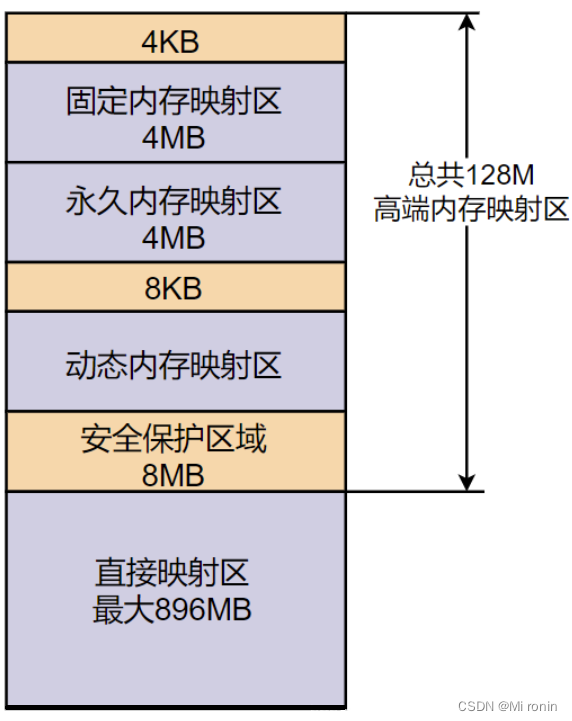
内核空间的组成:
直接映射区和高级内存映射区。
直接映射区:从内核空间起始位置开始,从低地址往高地址增长,最大为896M的区域即为直接映射区。
直接映射区的896M的虚拟地址与物理地址的前896M进行直接映射,所以虚拟地址和分配的物理地址都是连续的。
高级内存映射区:在上面也提到了,内核空间利用直接映射区来将896M的内存直接映射到物理内存中,但是我们的物理内存远远不止这么点,那么对于剩下的物理内存的寻址工作,就交给了高端内存映射区。
由于我们的内核空间只有1G,而直接映射区又占据了896M,因此我们将剩下的128M空间划分成了三个高端内存的映射区,从上往下分别是固定内存映射区,永久内存映射区,动态内存映射区。
- 动态内存映射区:该区域的特点是虚拟地址连续,但是其对应的物理地址并不一定连续。该区域使用内核函数vmalloc进行分配,分配的虚拟地址的物理页可能会处于低端内存,也可能处于高端内存
- 永久内存映射区:该区域可以访问高端内存。使用alloc_page(_GFP_HIGHMEM)分配高端内存页,或者使用kmap将分配的高端内存映射到该区域
- 固定内存映射区:该区域的每个地址项都服务于特定的用途,如ACPI_BASE-
内核空间内存分配
在内核空间中,通过与malloc类似的两个系统调用来进行内存的分配,它们分别是kmalloc和vmalloc。
kmalloc:
kmalloc与上面介绍的用户空间的malloc函数非常类似,其用于为内核空间的直接内存映射区分配内存。
kmalloc以字节为分配单位,通常用于分配小块内存,并且kmalloc确保分配的页在物理地址上是连续的(虚拟地址也必然连续)。并且kmalloc为了防止内存碎片的问题,其底层页面分配算法是基于slab分配器实现的。
vmalloc:
vmalloc用于为内核空间中的动态内存映射区进行内存分配。
vmalloc的工作方式与kmalloc类似,不同的地方在于vmalloc分配的内存只保证了虚拟地址是连续的,而物理地址不一定连续。它通过分配非连续的物理内存块,再通过修正页表的映射关系,把
内存映射到虚拟地址空间的连续区域,就能够做到这一点。

