文章目录
【写在前面】
本文中会介绍很多结构化的知识,我们会通过很多例子里的角色和场景来对一个概念进行定位和阐述,让大家有一个宏观的认识,之后再循序渐进的填充细节,如果你一上来就玩页表怎么映射,那么你可能连页表存在的价值是什么都不知道,最后也只是竹篮打水。
一、回顾与纠正
C/C++ 内存布局这个概念比较重要,之前我们也涉及过 ―― 我们在语言上定义的各种变量等在内存中的分布情况,如果没有听说过,那么你的 C/C++ 是不可能学好的。
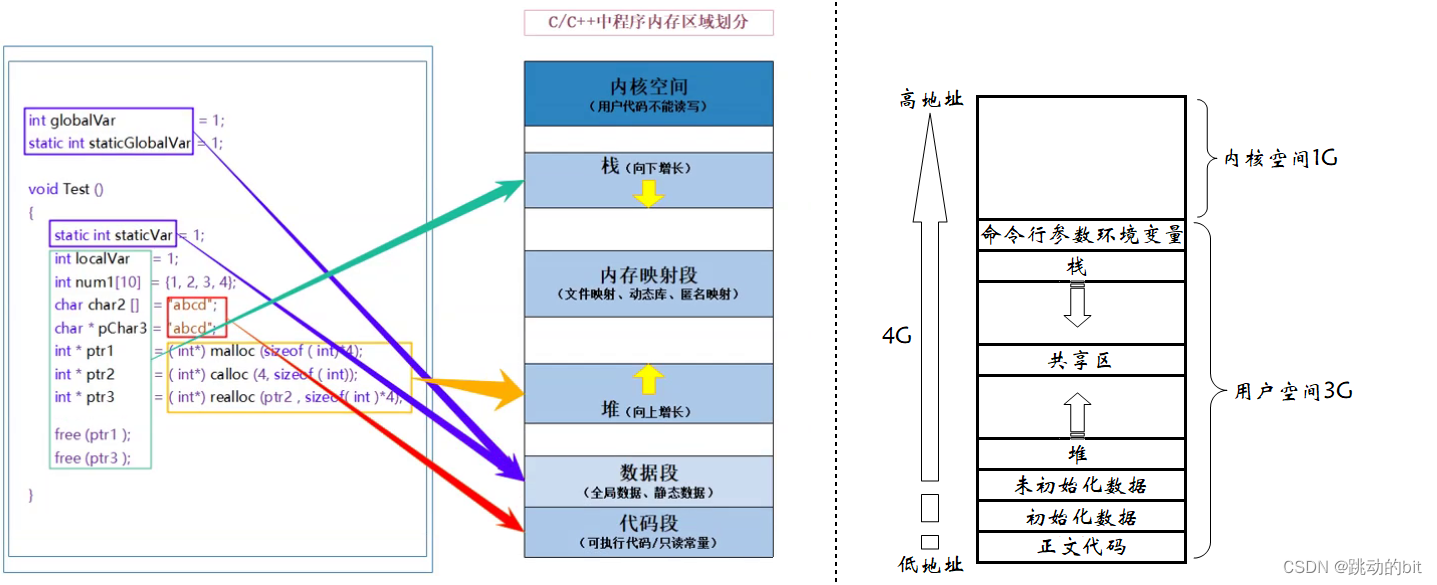
上图表示的是内存吗 ?
??其实我们曾经说过的 C/C++ 内存布局,严格来说是错误的,从今天开始我们应该称之为C/C++ 进程地址空间。为啥要故意说错呢,其实是因为方便理解,如果当时说 C/C++ 进程地址空间,那么不谈进程、地址、空间,就很容易误导大家。也就是说实际上要真正理解 C/C++ 的空间布局,光学习语言是远远不够的,还需要学习系统以及进程和内存之间的关系。
进程地址空间既然不是内存,那么栈、堆等这些空间的数据存储在哪 ???
??进程地址空间,会在进程的整个生命周期一直存在,直到进程退出,这也就解释了为什么全局变量具有全局属性。其实这些数据最后一定会存储于内存,只不过进程地址空间是需要经过某种转换才到物理内存的。
二、 验证进程地址空间的基本排布
#include<stdio.h>
#include<stdlib.h>
int g_unval;
int g_val = 100;
int main(int argc, char* argv[], char* env[])
{
printf("code addr: %p\n", main);
const char* p = "hello bit!";
printf("read only: %p\n", p);
static int a = 5;
printf("static global val: %p\n", &a);
printf("global val: %p\n", &g_val);
printf("global uninit val: %p\n", &g_unval);
char* q1 = (char*)malloc(10);
char* q2 = (char*)malloc(10);
printf("heap addr: %p\n", q1);
printf("heap addr: %p\n", q2);
printf("p stack addr: %p\n", &p);
printf("q1 stack addr: %p\n", &q1);
printf("args addr: %p\n", argv[0]);
printf("args addr: %p\n", argv[argc - 1]);
printf("env addr: %p\n", env[0]);
return 0;
}
💨结果:
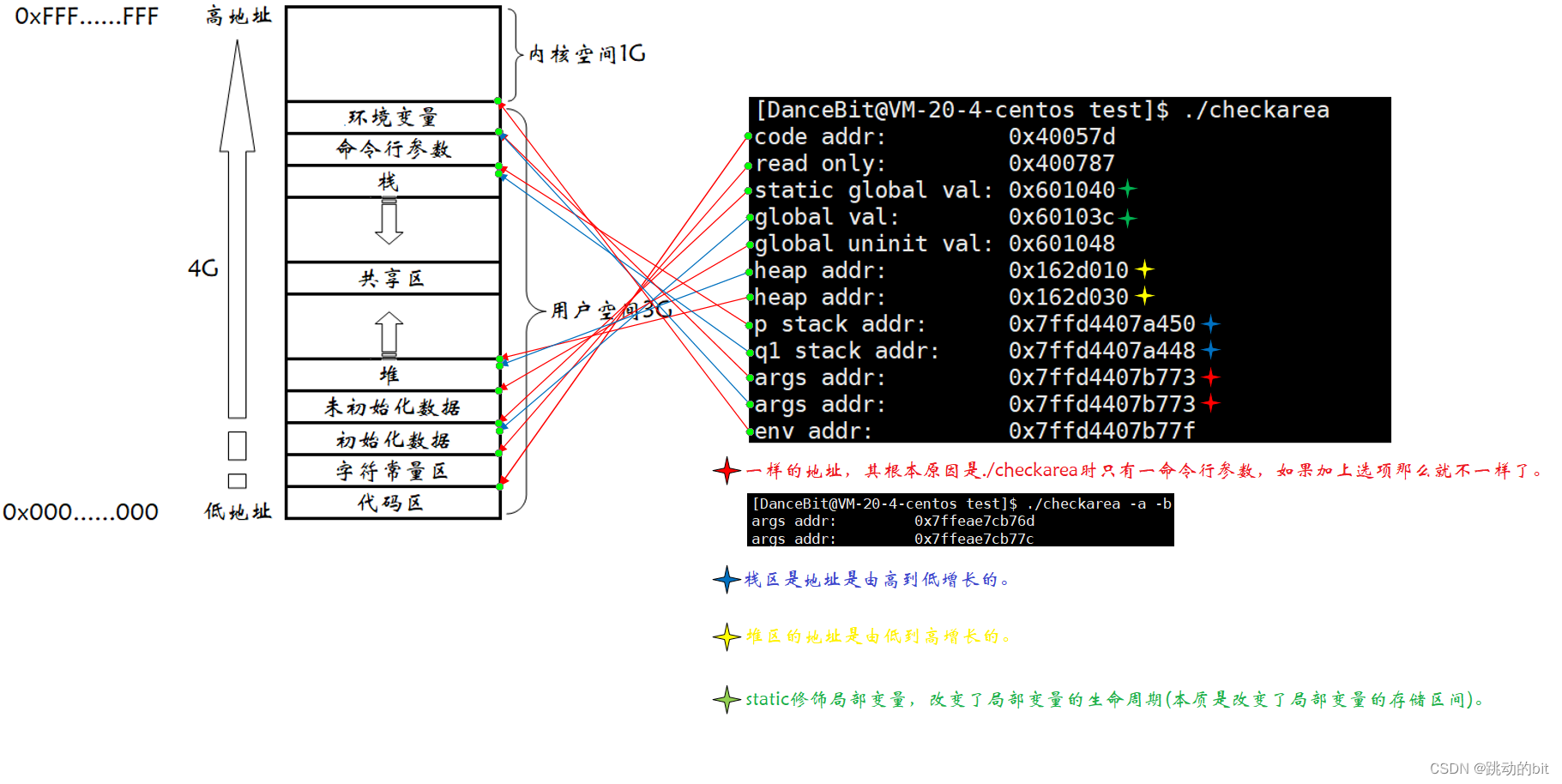
三、 什么是进程地址空间
💦 观察父子进程在5秒后,全局变量g_val的值和地址
#include<stdio.h>
#include<unistd.h>
#include<sys/types.h>
int g_val = 0;
int main()
{
printf("begin......%d\n", g_val);
pid_t id = fork();
if(id == 0)
{
int count = 0;
while(1)
{
printf("child pid: %d, ppid: %d, [g_val: %d][&g_val: %p]\n", getpid(), getppid(), g_val, &g_val);
sleep(1);
count++;
if(count == 5)
{
g_val = 100;
}
}
}
else if(id > 0)
{
while(1)
{
printf("father pid: %d, ppid: %d, [g_val: %d][&g_val: %p]\n", getpid(), getppid(), g_val, &g_val);
sleep(1);
}
}
else
{
//TODO
}
return 0;
}
💨结果:
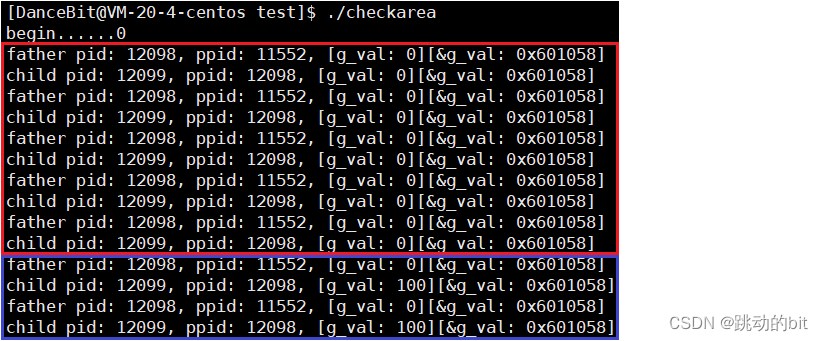
??根据我们现有的知识,无可厚非的是前 5 次父子进程的 g_val 的值是一样的,且地址也一样,因为我们没有修改 g_val, 5 次后,子进程把 g_val 的值改了之后,父进程依旧是旧值,这个我们一点都不意外,因为父子共享代码,数据各自私有;但匪夷所思的是 5 次后,父子进程的 g_val 的地址竟然也是一样的。
推导和猜测 ???
??从上图我们可以知道&g_val一定不是物理地址(真正在内存中的地址),因为同一个物理地址处怎么可能读取到的是不同的值。所以我们断言曾经所看到的任何地址都不是物理地址,而这种地址本质是虚拟地址,它是由操作系统提供的,那么操作系统一定要有一种方式帮我们把虚拟地址转换为物理地址,因为数据和代码一定在物理内存上存储,这是由冯 ? 诺依曼体系结构规定的。
💦 理解进程地址空间

地址空间在 Linux 内核中是一个mm_struct结构体,这个结构体没有告诉我们空间大小,但是它告诉我们空间排布情况,比如[code_start(0x1000), code_end(0x2000)],其中就会有若干虚拟地址,这是因为操作系统为了把物理内存包裹起来,给每个进程画的一把尺子,这把尺子我们叫进程地址空间。进程地址空间是在进程和物理内存之间的一个软件层,它通过mm_struct这样的结构体来模拟,让操作系统给进程画大饼,每一个进程可以根据地址空间来划分自己的代码。
所以我们再回顾:进程地址空间当然不是物理内存,它只是操作系统让进程看待物理内存的方式。
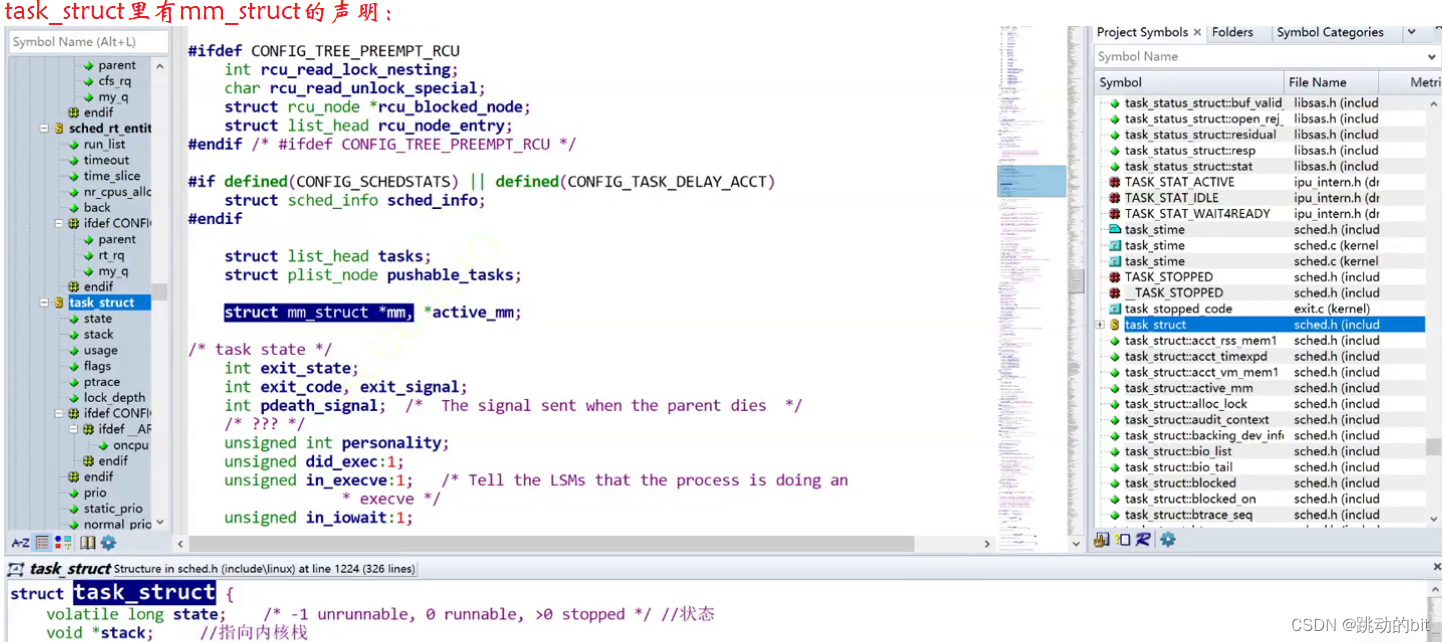
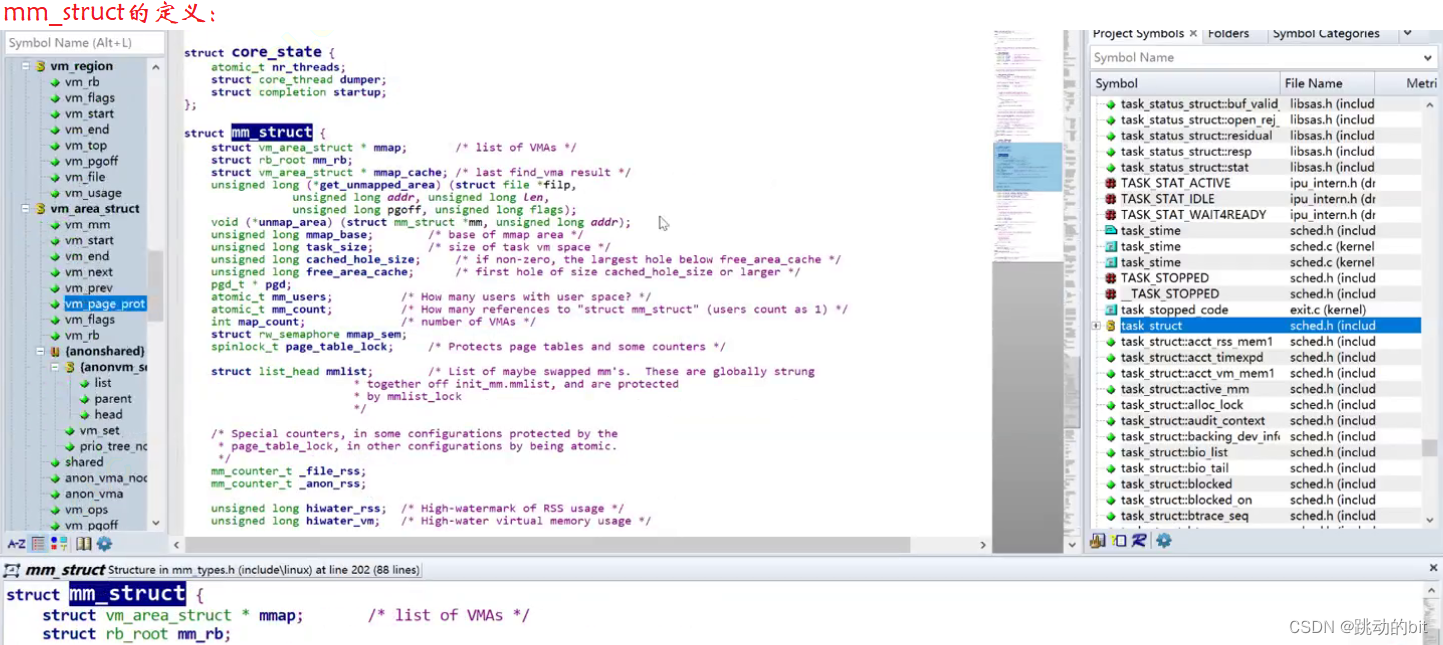
进程地址空间本质是进程看待物理内存的方式,它是抽象出来的概念,其中 Linux 内核中是用mm_struct数据结构来表示的。这样的话每个进程都认为自己独占系统内存资源(好比每个老婆都认为自己独占10亿);区域划分的本质是将线性地址空间划分成为一个一个的区域[start, end];而所谓的虚拟地址本质是在[start, end]之间的各个地址。
💦 进程地址空间如何映射至物理内存 (页表的引出)
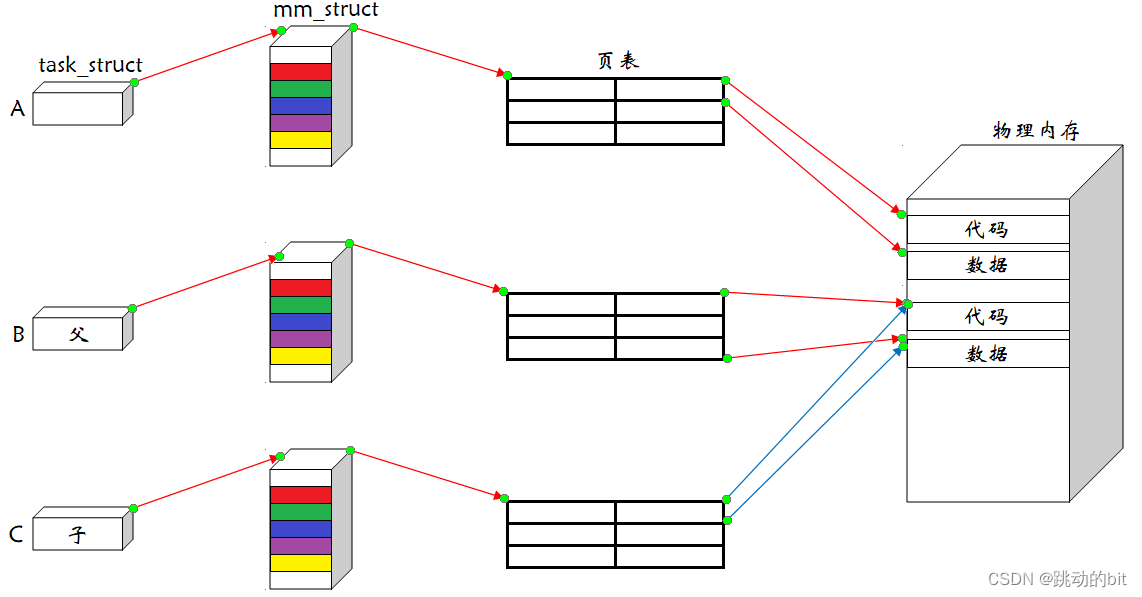
假设存在三个进程 A B C,操作系统就会给每一个进程画一张大饼,叫做当前进程的虚拟地址空间,其中会通过指针将进程和虚拟地址空间关联起来。运行进程A,就要把进程A加载到物理内存中,其中操作系统会给每一个进程创建一张独立的页表结构,我们称之为用户级页表,当然后面还有内核级页表,而页表构建的就是从地址空间中出来的虚拟地址到物理地址中的映射,每个进程都通过页表来维护进程地址空间和物理内存之间的关系,这是页表的核心工作,所以就进程就可以根据页表的映射访问物理内存。
能否把进程A中的代码和数据加载到物理内存中的任意位置 ?
??在不考虑特殊情况下,是可以将进程对应的代码和数据加载到物理内存的任意位置的,因为最终我们能通过进程中虚拟地址与页表之间的映射,再通过页表与物理内存中代码和数据的映射进行访问。所以进程中的代码和数据是能够加载到物理内存中的任意位置的,其中本质是通过页表去完成的。
多个进程之间会互相干扰吗 ?
不同的进程它们的虚拟地址可以一样吗 ???
??同样进程B也可以通过页表把代码和数据加载到物理内存的任意位置,这里就算不同的进程的虚拟地址完全一样也没问题,因为不同进程通过一样的虚拟地址查的是不同的页表,其中的工作细节是由页表去完成的。
如果物理地址重址呢 ???
??这是操作系统的代码,一般不可能重址。当然也存在这样的特殊情况,如果进程B和进程C是父子关系,我们在创建子进程C的 PCB、地址空间、页表、建立各种映射关系,把代码区、数据区等区域映射时,只需要将子进程C映射到物理内存中父进程代码和数据处,但当子进程C修改数据时,操作系统就会重新申请内存,修改当前进程的指向关系,让子进程C指向新的空间,把旧数据拷贝至新数据,此时这就是写时拷贝。所以不同的页表,物理地址可以重址,只不过这种重址是刻意的。
💦 为什么要存在进程地址空间
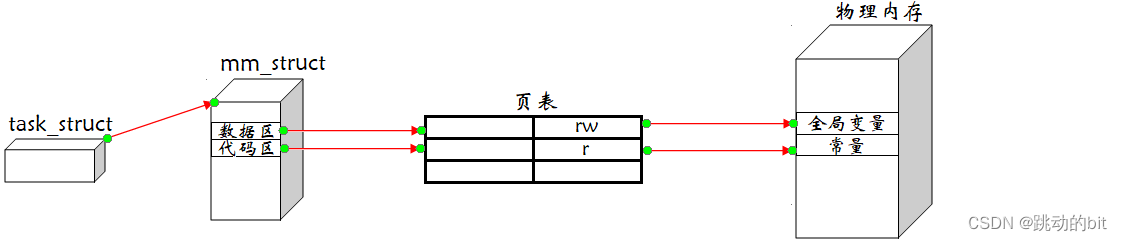
?&emsp其实早期操作系统是没有所谓的虚拟地址空间的。如果进程直接访问物理内存,那么我们看到的地址就是物理地址,当我们认识过在 C语言中有一个概念叫做指针,那么就能理解有可能会出现:如果进程A出现了越界,那么就有可能直接访问到了另一个进程的代码和数据,所以进程的独立性便无法保证。因为物理内存暴露,其中就有可能有恶意程序直接通过物理地址,进行内存数据的篡改。比如说某进程里有帐号和密码的数据,那就有可能会被更改帐号密码,如果操作系统不让改,那也可以进行读取,如果操作系统不想让你读取,操作系统就要实现一些较为困难的权限管理,成本较高。后来大佬对进程和物理内存之间就引出了虚拟地址空间,其中每一个进程都有自己的地址空间、页表。虚拟地址最终通过页表转换为物理地址,那么页表需要根据实际情况转或不转。好比小时候过年,收到亲戚的压岁钱后,妈妈怕你乱花钱,所以就帮你存起来,当你要买资料时,你妈就帮你支出,但你要买游戏机时,你妈就可以拒绝你。换言之,虚拟地址到物理地址的转换,是由页表完成的,同时也需要进行合法性检测。
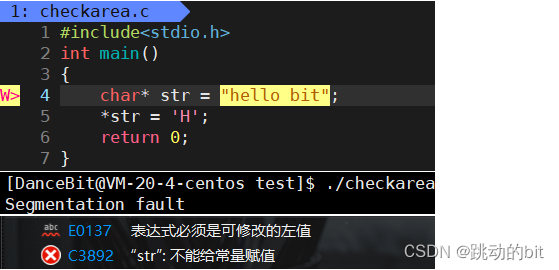
??至此我们认识到地址空间的引入可以保护物理内存。其它情况,越界时不一定报错,比如在栈区越界后还是在栈区,在一个合法区域内,操作系统是有其它机制去检测的,那么既定的 C/C++ 事实是我们在越界时是不一定报错的,因为编译器是以抽查的形式来检测,这里可以去了解一下金丝雀技术。对于有区域划分的地址空间,你访问数据区,但是因为越界访问了代码区,操作系统就可以根据你曾经区域划分时的[start, end]来确认是否越界。对于页表,它将每个区域映射至物理内存中,页表要进行某种映射级别的权限管理,比如在映射数据区时,物理内存的任意位置都是可以被修改的,否则曾经的数据是怎么被加载的;但在映射代码区后,你有任何的写入操作时,操作系统发现对应页表你只有r权限,一旦写了,操作系统就终止你的进程。我们都知道如上这种字符串是在代码区存储,代码区是只读的,所以你要修改它,在 Linux 下报的是段错误,在 VS 下报的是表达式必需是可修改的左值。从 Linux 报的错误来看,这段代码是能编译通过的,但是运行后,操作系统发现页表在映射时,你要映射的区域是不可写的,那么经过这样的进程地址空间 + 页表,操作系统就可以直接终止进程,换言之,进程地址空间是为了更好的进行权限管理。
只读的代码区,那么第一次是怎么形成的 ???
??形成代码区时不就是把数据往代码区里写吗,其实代码区在操作系统的角度,它一定是物理内存的任何位置都可以改的,只不过*str = 'H'是在你进行写入后修改字符串起始的第一个字符,所以经过对应的页表映射时,发现你对这个区域的权限是只读的,而你竟然想写入,所以操作系统就不会映射,直接终止进程。
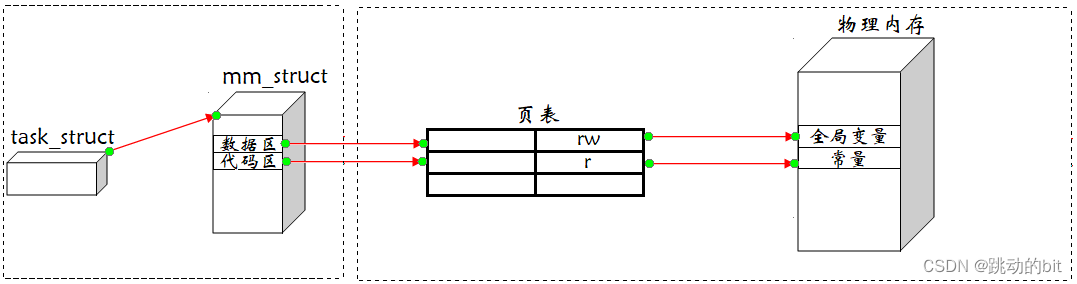
我们都知道操作系统具有 4 种核心功能:进程管理、内存管理、驱动管理、文件管理。而上图很明显是与进程管理和内存管理有关,比如说一个进程要执行,首先要申请内存资源,并加载到内存,然后创建 PCB 等进程管理工作;而进程死亡后,就需要内存管理模块来进行尽快回收,内存管理必须得做到知道某个进程的状态。所以内存管理模块和进程管理模块是强耦合的。如果有了虚拟地址空间的概念,那么进程管理关注左半部分,而内存管理关注右半部分。在 C++ 中有一个技术叫做智能指针,比如说给物理内存的一块区域设置一个计数器 count,其中当页表映射一个进程后,count++,当进程释放后,映射关系消失,count--。所以内存管理只需要检测当前物理内存中的 count 是否为 0。
一个 16G 的游戏能否在 4G 的物理内存上运行 ?
??能,比如你的内存是 32G,即便你加载了 16G,对计算机而言,它是从头开始访问的,也就是说 16G,你已经有 15G 已经加载到内存了,但你尚没有正常使用,还需要等待后面的数据加载进来,所以这是一种很低效的方案。所以操作系统要执行这个进程,但内存管理模块认为给你搞这么多你又不使用,所以就先加载 200M 给你,当你从上至下访问到最后时,如果你还需要,就再给你覆盖式的加载 200M,此时进程是不知道内存管理模块给他做的操作,内存管理就可以通过不断延迟加载的技术方案,来保证进程照样可以正常运行,这就是进程管理模块和内存管理模块解耦。所以对于用户来说,唯一感受到的是我的电脑变慢了,当然这也是应该的。
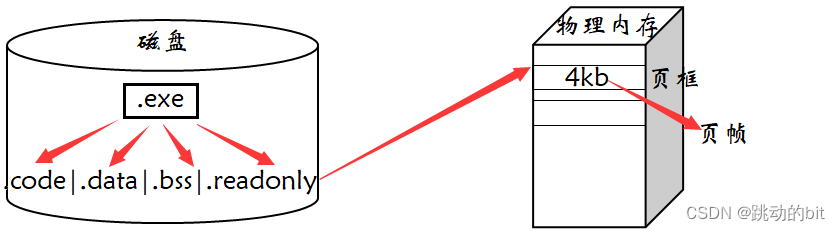
在磁盘上形成的 .exe 文件在编译时其实并不是无脑的把代码和数据一分为二就完了,而是在磁盘中按照文件的方式组织成一个一个区域,这样做的原因是便于生成可执行程序,如果划分好了区域,那么就会减少程序链接过程的成本。因为磁盘上的可执行程序本身就是按模块划分的,所以进程地址空间才有了区域划分的概念,但要注意物理内存的情况有可能大部分的空间已经被使用了,那么进程的代码和数据就零散的分布于物理内存的不同位置。物理内存也有区域,只不过它的内存分配是按页为单位,一页是 4kb,换言之,磁盘数据加载到物理内存时,是按 4kb 为单位,其中每页是页框、4kb 是页帧。
顺序语句 ?
??本质是将虚拟地址线性连续后,顺序语句就能实现了。所以顺序语句就是当前语句的起始地址 + 当前代码的长度。
show 函数调用完后,字符串还在吗 ?
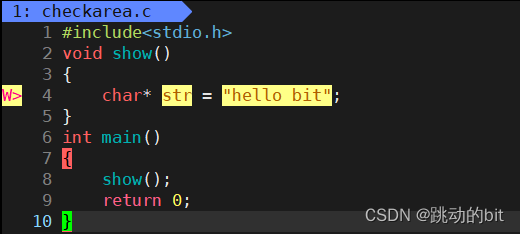
??当 show 函数调用完后,函数栈帧销毁,所以局部变量 str 一定是不在了;但是对于字符串,它存储于常量区,只要进程还在,那么字符串就还在。show 栈帧结束,理论上是找不到字符串了,所以我们就能理解所有的地址信息都必须要用变量保存,当你在物理内存中 malloc 好一块内存,页表构建映射关系,把地址映射到堆区,最后这个区域的起始地址就返回给用户,如果用户不使用变量保存,那么就会存在内存泄漏。
所以虚拟地址空间存在的意义有:
- 更好的进行权限管理和保护物理内存不受到任何进程内地址的直接访问,方便进行合法性校验。
- 进程管理和物理管理进行解耦。
- 让每个进程以同样的方式,来看待代码和数据。
💦 解释子进程修改全局变量g_val后的地址相同于父进程&g_val
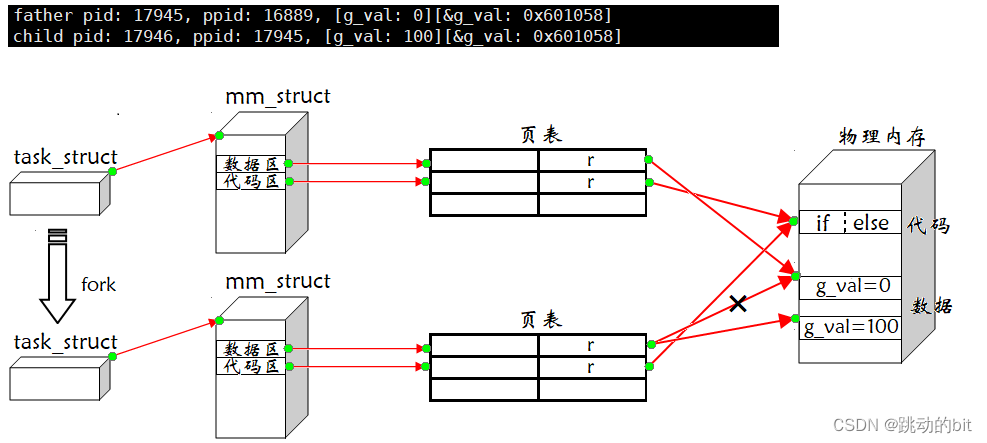
??父进程在 fork 时,操作系统一定是多了一个进程,而子进程需要创建自己的 mm_struct、页表,其中子进程中的大多数属性是以父进程为模板。代码里是通过 if 和 else 来分流的 ―― 父进程执行 if,子进程执行 else,实际上,不管是父进程还是子进程都能看到所有的代码,只不过不会全部执行。因为子进程中的大多数属性是以父进程为模板,所以父子进程 &g_val 的虚拟地址是相同的,当子进程尝试对 g_val 写入,而操作系统发现对于 g_val,父子进程只有 r 权限(因为它们指向同一块内存),你居然想 w,操作系统又发现,你俩是父子关系,所以没有杀掉子进程, 而给你重新开辟一块空间,把旧空间的内容拷贝,子进程的页表就不再映射至父进程的 g_val,而是子进程的 g_val 自己私有一份,所以子进程再修改时,就可以把 g_val = 100 了,其过程的本质是写时拷贝。所以我们就能解释为啥 g_val 的值改变后,而 &g_val 的值却是相同的。
进程和程序有什么区别 ?
??从现在开始我们再提到进程,就应该立马能联想到 task_struct、mm_struuct、页表、代码和数据。
四、Linux2.6内核进程调度队列 ―― 了解
不是本文的重点,所以了解一下即可。
💦 Linux2.6内核中进程队列的数据结构
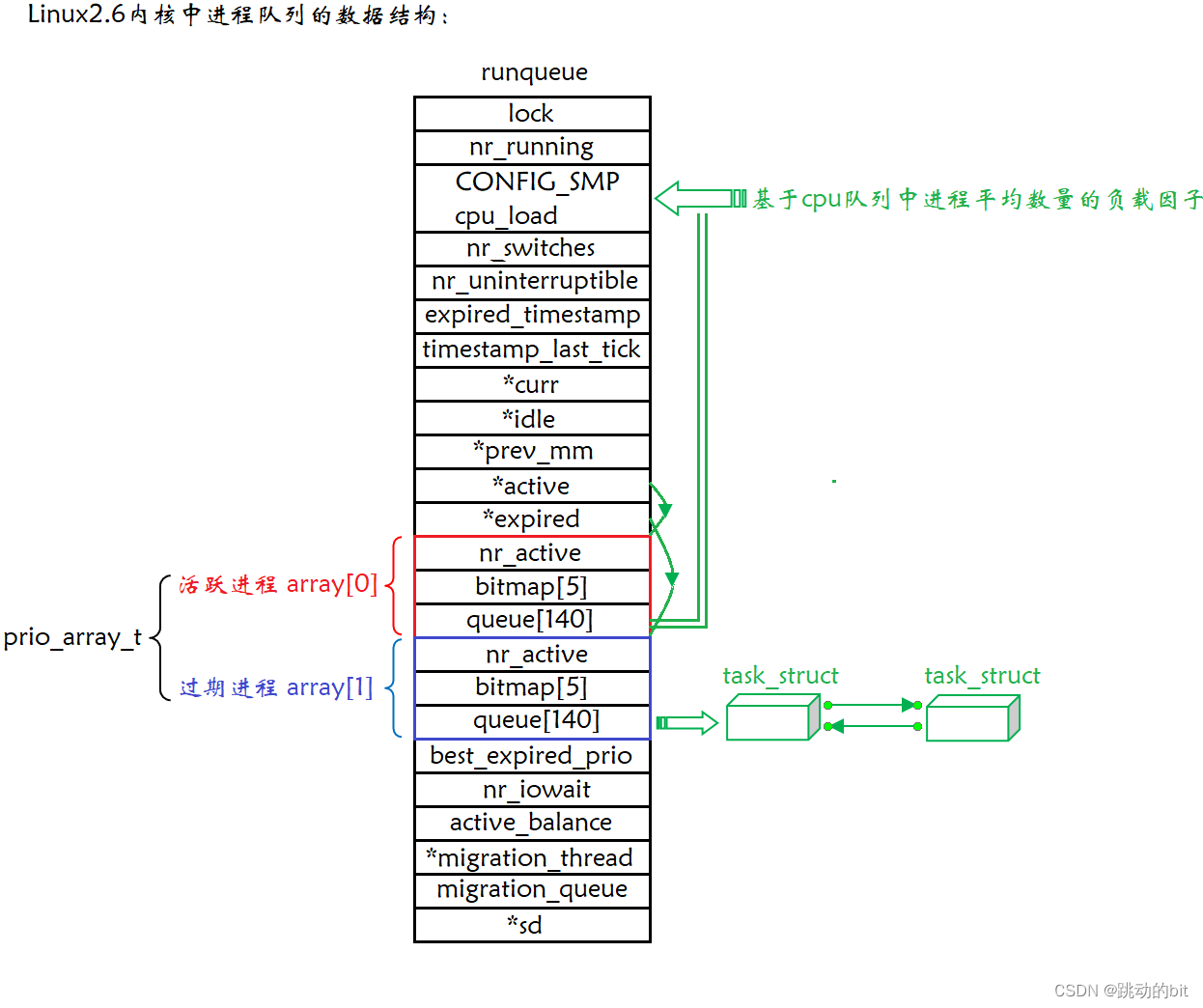
💦 一个CPU拥有一个runqueue
- 如果有多个 CPU 就要考虑进程个数的负载均衡问题。
💦 优先级
- 普通优先级:100~139 (我们都是普通的优先级,想想 nice 值的取值范围,可与之对应 !)。
- 实时优先级:0~99 (不关心)
💦 活动队列
-
时间片还没有结束的所有进程都按照优先级放在该队列。
-
nr_active:总共有多少个运行状态的进程。
-
queue[140]:一个元素就是一个进程队列,相同优先级的进程按照 FIFO 规则进行排队调度,所以,数组下标就是优先级。
-
从该结构中,选择一个最合适的进程,过程是怎么的呢 ?
1、从 0 下标注开始遍历 queue[140]。
2、找到第一个非空队列,该队列必定为优先级最高的队列。
3、拿到选中队列的第一个进程,开始运行,调度完成。
4、遍历 queue[140] 时间复杂度是常数,但还是太低效了。 -
bitmap[5]:一共 140 个优先级,一共 140 个进程队列,为了提高查找非空队列的效率,就可以用 5*32 个比特位表示队列是否为空,这样,便可以大大提高查找效率。
💦 过期队列
- 过期队列和活动队列结构一模一样。
- 过期队列上放置的进程,都是时间片耗尽的进程。
- 当活动队列上的进程都被处理完毕之后,对过期队列的进程进行时间片重新计算。
💦 active指针 and expired指针
- active 指针永远指向活动队列。
- expired 指针永远指向过期队列。
- 可是活动队列上的进程会越来越少,过期队列上的进程会越来越多,因为进程时间片到期时一直都会存在的。
- 没关系,在合适的时候,只要能够交换 active 指针和 expired 指针的内容,就相当于有具有了一批新的活动进程。
💦 总结
- 在系统当中查找一个最合适调度的进程的时间复杂度是一个常数,不随着进程增多而导致时间成本增加,我们称之为进程调度 O(1) 算法。

