【写在前面】
本文主要学习理解 fork 的返回值、写时拷贝的工作细节、为什么要存在写时拷贝;进程退出码、进程退出的场景及常见的退出方法、对比 man 2 _exit 和 man 3 exit;进程终止、操作系统怎么进行释放资源、池的概念;进程等待的价值、进程等待的方法 wait 和 waitpid(常用)、int* status、阻塞和非阻塞、如何理解等待、W
IFEXITED、WEXITSTATUS、WTERMSIG;什么是进程替换 && 为什么要进程替换、替换原理、7个exec系列的替换函数、模拟shell解释器;
一、进程创建
现阶段我们知道进程创建有如下两种方式,其实包括在以后的学习中这两种方式也是最常见的:
- 命令行启动命令 (程序、指令等)。
- 通过程序自身,fork 的子进程。
💦 fork函数
在 linux 中 fork 函数是非常重要的函数,它从已存在的进程中创建一个新进程。新进程为子进程,而原进程为父进程。
#include<unistd.h>
pid_t fork(void);
返回值:子进程返回 0,父进程返回子进程的 pid,出错返回 -1。
现在我们知道父进程被创建时,是有自己的 PCB、地址空间、页表的,在系统层面是通过用户级页表来维护地址空间和物理内存之间的映射关系的,而父进程只需要根据 PCB,找到地址空间,通过地址空间这样的窗口找到资源。不论是进程还是地址空间,它都是某种 struct 结构体变量,其中就包含很多属性和属性值。父进程 fork 时,子进程是以父进程为模板,人话就是子进程的大部分属性和属性值是继承父进程的,而小部分是指子进程的调度时间要重置、子进程的 pid、ppid 以及兄弟的要重置。其中上面的 PCB、地址空间、页表都在内核里由操作系统维护的,这也就意味着我们只需要调用操作系统提供的接口 fork,而具体工作细节由操作系统完成。
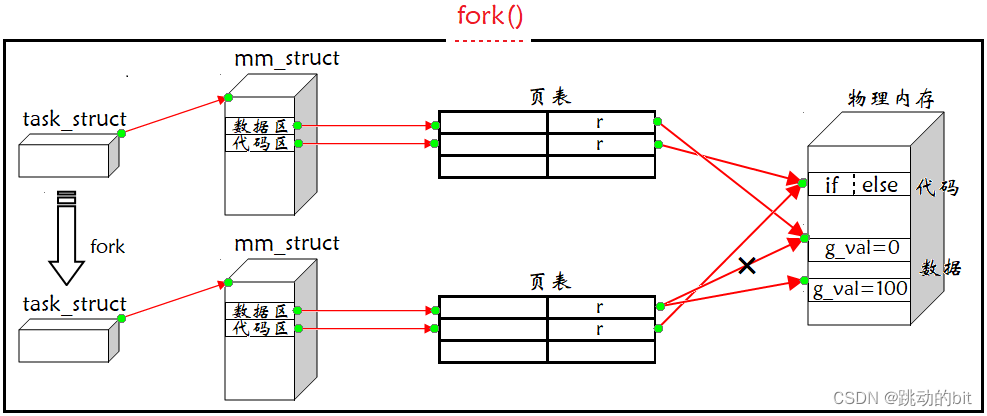
进程调用 fork 时,控制逻辑就由用户层转移至内核,内核做:
- 分配新的内存块和内核数据结构给子进程。
- 将父进程部分数据结构内容拷贝至子进程。
- 添加子进程到系统进程列表当中。
- fork 返回,调度器调度。
💦 fork函数的返回值
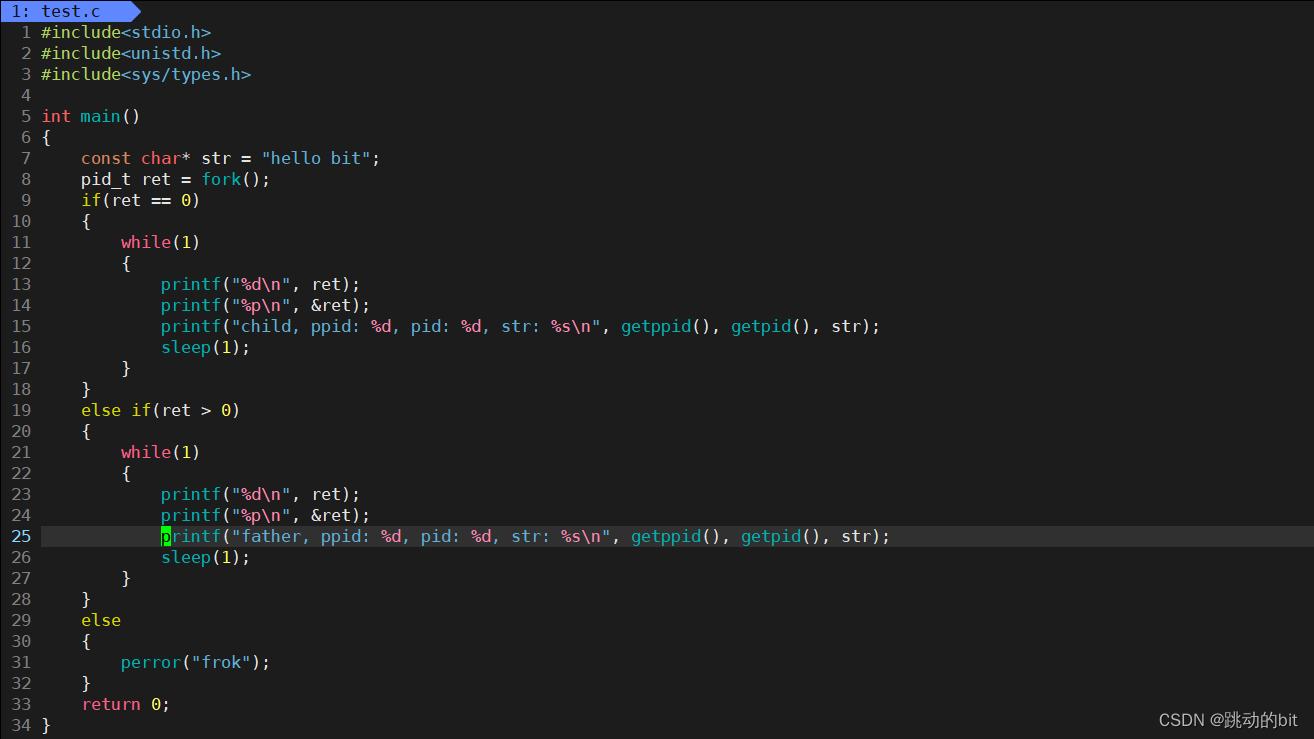
如下代码运行后共创建了多少个子进程,它的之间的关系是啥 ?
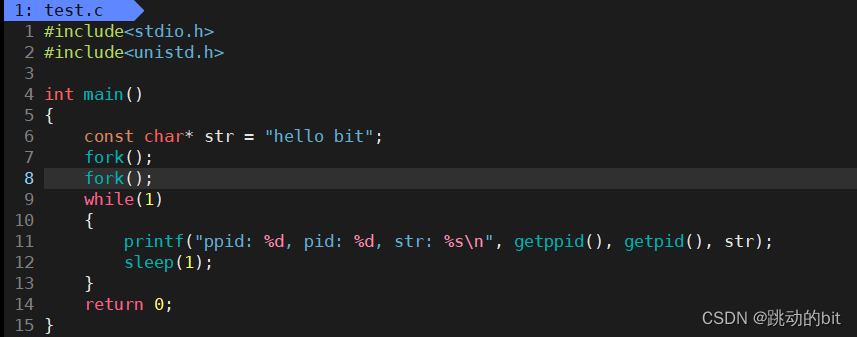
💨 运行后:
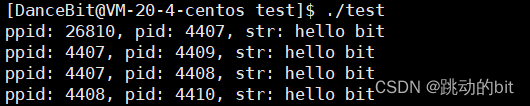
??当我们看到这样的结果时,也不要奇怪,这是由调度器决定的。这里 4407 fork 了 4409 和 4408,此时 4407 第 1 次 fork 的进程 4408 还要在 fork 4410。
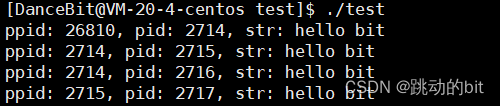
??这里共创建了 4 个子进程,其中 2714 fork 之后,创建了 2715 进程,最后 2714 和 2715 会再 fork 2716 和 2717。这里就算是 2717 进程,对于 test.c 中所有的代码都是共享的,只不过不会执行它以上的代码,其中 2717 进程是通过程序计数器 epi 指针知道自己该执行哪行代码的。
一般我们不会让父子进程做同样的事 ?
💨 运行后:
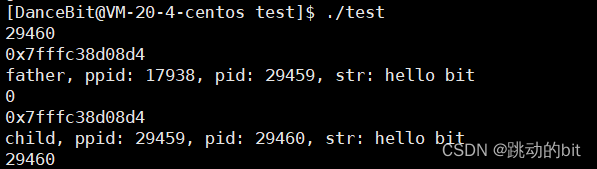
??结合《Linux进程概念――上》至现在的认识,我们知道 fork 是一个系统函数,其中它会完成创建 pcb,生成 pid、创建地址空间、创建页表、构建映射关系、将子进程的 pcb 链入调度队列、返回 pid 等工作,在返回之前,这些工作看起来是由父进程完成的,我们曾经说过函数在返回时,函数的主要逻辑已经执行完了。
??父进程的 pid 是 29459,子进程的 pid 是 29460。子进程的 pid 并不是由父进程给予的,包括父进程的 pid 也不是父进程的父进程给予的,而是由操作系统给予的。也就是说进程的创建看起来是由父进程创建的,但其实并不是,而是父进程通过调用 fork 函数开始了创建新进程的过程,本质任何进程的创建还是要由操作系统去完成的。
我们根据 fork 的返回值,来执行不同的逻辑流。从这里我们需要回答两个问题:
为啥 fork 同时有两个返回值和用于接收 fork 返回值的 ret 变量是怎么做到 ret == 0 && ret > 0 ???
??子进程创建之后,父子进程是共享代码的,我们认定 return 是代码,是和父子进程共享的代码,所以当我们父进程 return 时,这里的子进程也要 return,所以说这里的父子进程会 return 2 个值。
??这里 pid_t ret = fork(),父进程调用 fork,在 return 时,子进程已经创建出来了,那么父进程就 return 子进程的 pid 来初始化 ret 局部变量,随后子进程就 return 0 ,此时必定是通过写时拷贝来完成数据的各自私有,虽然父子进程的 &ret 是一样的,但是物理内存一定是两块不同的空间。 当我们理解了为啥同一个变量,却可以是两个不同的值后,再看 fork 为啥会有两个返回值时就有了新的理解角度。
注意不是 fork 创建子进程,并写时拷贝,而是 fork 创建子进程之后,父子谁先写入谁就写时拷贝,这里发生写时拷贝的原因是父子进程 return 的值用于初始化局部变量 ret 了。
??角度一 (好理解,因为不用理解写时拷贝):父子进程会使 fork return 2 个值。
??角度二 (较为准确):返回时发生了写时拷贝。
最后我们就可以明确了写时拷贝的价值就是保证父子进程的独立性。
💦 写时拷贝
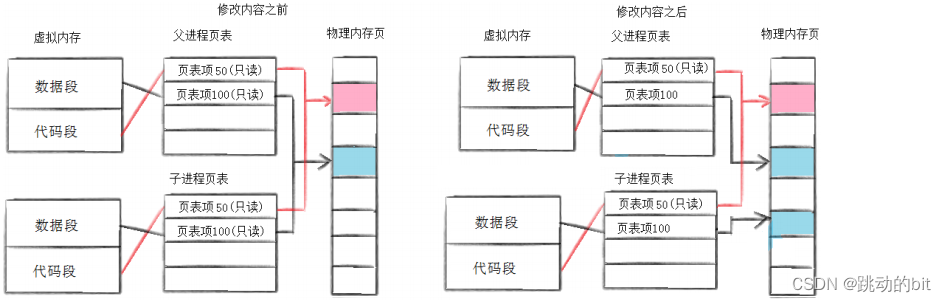
写时拷贝是一种机制或者策略,好比打仗时的敌退我打,敌进我撤,它根据实时情况来完成既定规则。同理写时拷贝是根据父和子谁先写入的实时情况来完成拷贝的,它是一种延时操作的策略。
通常,父子代码共享,父子不写入时,数据也是共享的,且它们都是只读的,当任意一方试图写入,一般情况下程序就会报错终止了 (这里的报错是系统层面的,但因为这里是父子关系,操作系统就需要做拦截工作),所以操作系统便以写时拷贝的方式生成一份副本于内存,修改页表的映射关系,并且更改权限为可读可写。具体见下图:
这里要强调的是这里的写时拷贝是针对数据的写时拷贝,这里留一个疑问 ―― 代码会发生类似的写时拷贝的问题吗 ?
??答案是会的,在下面的进程替换会说明。
为什么存在写时拷贝 ?
-
写时拷贝是为了保证父子进程的独立性。
-
节省内存和系统资源,提高 fork 的效率,减少 fork 失败的概率。
父子进程创建时,所有数据直接各自拷贝一份不行吗 ???
??很明显,不使用写时拷贝也可以保证父子进程的独立性,为啥还要费劲使用写时拷贝。其根本原因是 a) 所有的数据,父和子并不是都必须写入数据,有可能它们仅仅需要读取,而此时的各自拷贝是没有意义的,而且会浪费内存和系统资源。b) fork 时,创建数据结构,如果还要将数据拷贝一份,那么 fork 的效率一定会降低。c) fork 本质就是向系统申请更多的内存资源,资源申请多了,fork 有可能就会失败。
💦 fork常规用法
- 一个父进程希望复制自己,使父子进程同时执行不同的代码段。例如,父进程等待客户端请求,生成子进程来处理请求,这个会在《Linux 网络编程》中学习。
- 一个进程要执行一个不同的程序。例如子进程从 fork 返回后,调用 exec 函数,这个会在本文中学习。
💦 fork调用失败的原因
fork 是操作系统的接口,所以失败的原因一定是系统级别的原因。
- 系统中已经存在太多的进程了。
- 实际用户创建的进程超过了限制。
二、进程终止
为什么 main 函数中,总是 return 0,return 其它值可以吗 ?
??对于 main 函数的返回值,我们称之为进程退出码,它代表进程退出后,结果是否正确,通常进程退出码为 0 代表成功,!0 代表其它含义,如果你愿意你也可以 return 其它值。大部分情况下,main 函数跑完后,默认结果是正确的,所以以前返回的都是 0。
main 函数 return 的值给谁看 ???
??其实 main 函数 return 的值是给系统看的,以此来判断进程执行后的结果。
程序员怎么看 main 函数 return 的值吗 ???
??echo $?用来保存最近一次程序运行结束时退出码的值是多少。
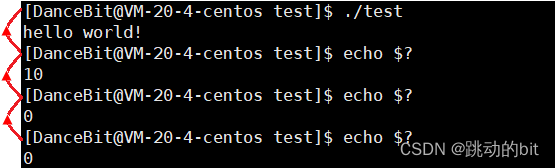
💦 进程退出的场景
此文重点学习前两种场景,第三种会学习一部分,后面信号再补充:
- 代码运行完毕,结果正确,退出码为 0
- 代码运行完毕,程序没有崩溃,但因为逻辑问题,结果不正确,退出码为 !0。
- 代码没有运行完毕,程序非正常结束,包括人为终止,此时退出码没有意义。
在之前我们经常会遇到第二种场景,但是它返回的也是 0 ?
??说明之前写的代码并不好,更加规范的写法是如果结果符合预期就返回 0,否则返回 !0。
退出码 ?
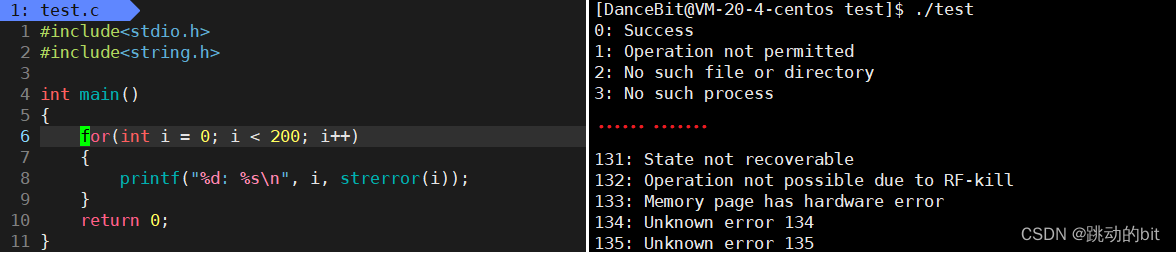
??退出码可以人为的定义,比如 0 表示成功,1 表示链表翻转时头节点传野指针了等,也可以使用系统的错误码列表。当程序运行失败时,毫无疑问我们最关心的是为什么会失败。比如你的妈妈很严厉,而你今天考试得了零分,这是一次很失败的考试经历,你妈妈知道后,一定会问你为什么失败,此时你就得告诉妈妈失败的原因。人最擅长的是处理字符串,所以你说是因为迟到了。而计算机擅长处理整型类型的数据,所以才有了 0, 1, 2, 3 等这样的退出码。所以计算机需要将 int 类型的错误码转换为 string 类型的错误码,以供我们认识。
演示 int 到 string 错误码之间的映射 ???
??你可以使用系统错误码,但是这种方式是受限的。strerror 可以实现 int 到 string 错误码之间的映射。
所有的父进程都关心子进程退出结果 ?
??大部分情况下通常退出码是父进程关心的,因为父进程费了很大的劲把子进程创建出来干活,活干的怎么样,父进程得知道。但并不是所有的父进程都关心子进程退出结果,比如说公司老板想开除我,然后 hr 找我谈,说你的合同到期了,可以走了,再干下去你也没工资,此时你肯定会走,hr 也不需要关心。换言之,我们后面可能会碰到父进程不需要关心子进程的退出结果的场景。
进程非正常结束 ?
??野指针、/0、越界等都可能导致进程非正常结束,父进程也要关心这种情况,但此时退出码是无意义的。好比,今天考试,因为肚子痛考了 0 分,那么这个理由是可以被妈妈信服的。但因为考试作弊被抓,考了 0 分,这个其实不算理由,因为你都不是正常考完的,后面你再解释的所有理由就毫无意义。
??一般这里异常终止时,是由信号终止的,因为涉及信号,不是本文的重点,所以后面再详谈。
💦 进程常见的退出方法
1、正常退出
-
main 函数 return。
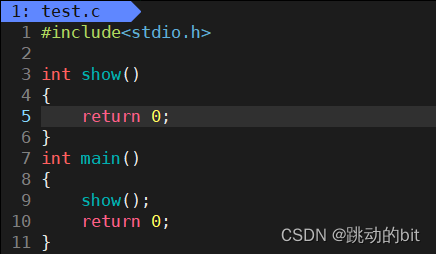
可以看到只有 main 函数的 return 才是结束进程,非 main 函数的 return 是结束函数。
-
任何函数 exit。
对于 exit,这里我们使用库函数就足够了。
任何函数 exit,都表示直接终止进程。
2、异常退出
- ctrl + c,信号终止
3、_exit函数
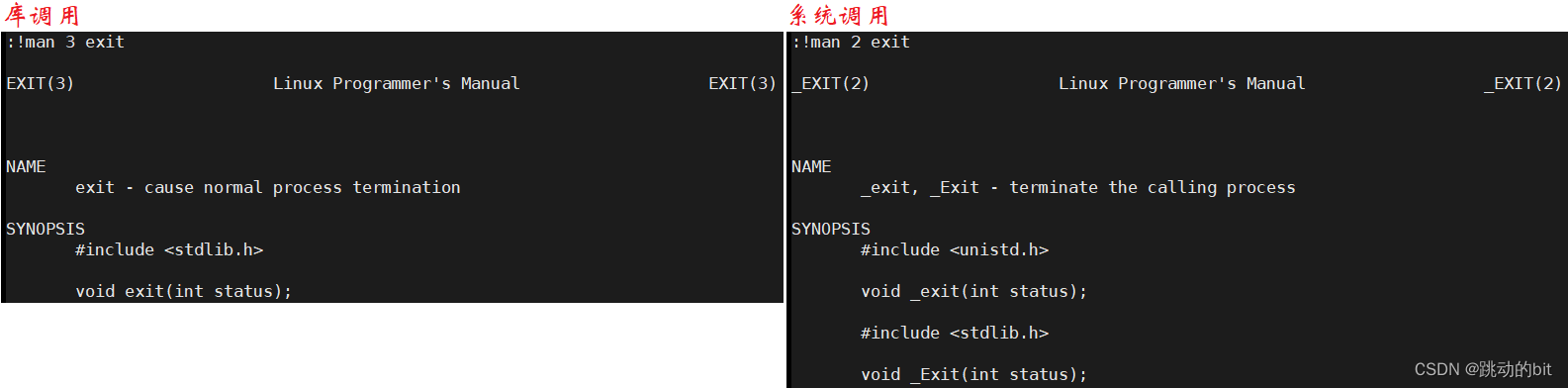
这是系统提供的接口,它的原型同库里的 exit 函数,那么系统的 _exit 和 库函数的 exit 有什么区别 ?
-
exit 在退出时同默认的 return,会进行后续资源处理,包括刷新缓冲区。

-
_exit 在退出时,不会进行后续资源处理,直接终止进程。

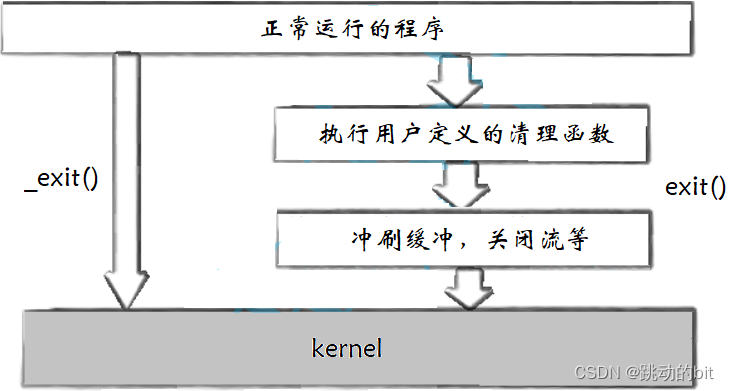
exit 最后也会调用 _exit,但在这之前,exit 还做了其它工作 ???
- 执行用户通过 atexit 或 on_exit 定义的清理函数。
- 关闭所有打开的流,所有的缓存数据均被写入。
- 调用 _exit。
main 函数里都不写 return 和 exit,退出码是啥 ?

理论上这里的退出码是未定义的、随机的,但实际上,得到的退出码是 0,因为你的 main 函数里总会调用其它函数,成功后,遗留的历史数据是会充当返回值去返回的。

main 函数里啥也不做,可以看到退出码依旧是 0,不必太纠结,这个本就是标准未定义的。
💦 如何理解进程终止
站在操作系统角度,如何理解进程终止 ?
??之前我们说过,进程创建,操作系统要做的事:把程序加载到内存、创建对应的 pcb、地址空间、页表、构建地址空间到物理内存的映射关系、把进程放在运行队列调度。那么进程终止肯定是曾经进程创建的相反工作,核心是归还资源。
-
“ 释放 ” 曾经为了管理进程所维护的所有的数据结构对象。
这里的释放,在操作系统里,并不是真的把数据结构对象销毁,而是设置为不用状态,然后保存起来,如果这样不用的对象多了,就有了一个 “ 数据结构池 ”。
池 ?
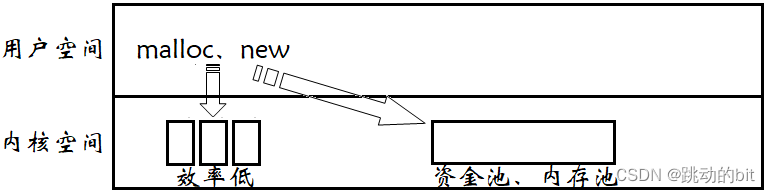
??我们在 C/C++ 中都使用过库函数 malloc、操作符 new 来申请过内存,内存是硬件,malloc、new 一定是向操作系统申请,而这个过程相对比较耗时。比如你是某某市的首富的儿子,要去银行贷款 100 万,银行会让你填张表、排队、审核你的条件,最后说 5 天之后放款。你的钱用完了,还需要去银行再贷款 200 万,又重复贷款流程。你的钱又用完了,又还需要去银行再贷款 300 万,又重复贷款流程。那么对银行来讲,只要你不嫌麻烦,银行当然没问题,可是实际对你来讲,每次贷款都需要等很长的时间,效率太低,所以干脆你可以直接贷款 1000 万,这 1000 万我们称之为资金池,后面你想用 100 万、200 万,就不用去找银行了,你直接从你的资金池里拿,后面你盈利了,就把钱还给银行。 这就意味着你一次申请一大块内存,可以节省你频繁的从用户空间向内核空间要资源的过程,我们把申请的一大块空间叫做内存池,所以池本质是为了提高用户的效率。
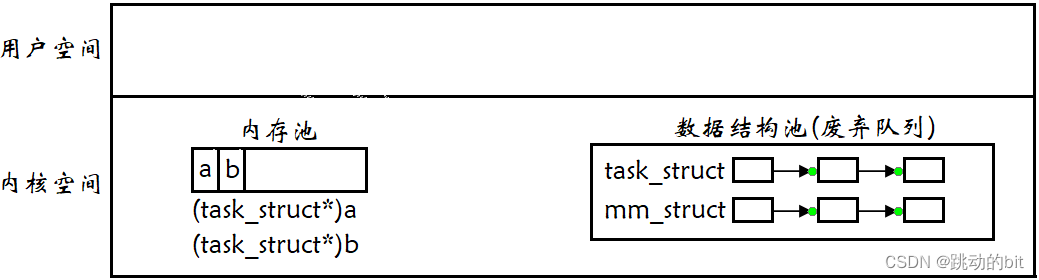
??我们创建进程,就需要生成 task_struct、mm_struct 等各种数据结构,那么就需要往已经申请好的内存池空间来存储,此时需要对该空间进行强制类型转换为 task_struct*,每个进程创建生成的数据结构,都要进行强制类型转换,太麻烦了,内存池也没规定必须得是这样的结构。所以这里使用了一个链表结构,里面存储的是没有人使用的 task_struct 等数据结构,如果要释放进程所维护的数据结构,那么就把数据结构对象链入链表中,如果进程创建,需要对应的数据结构,就直接从数据结构池里拿,这样就不用申请空间和强制类型转换了。我们可以维护各种各样的数据结构,整体我们称之为数据结构池。
??所以我们就可以把不要的数据结构,包括里面的数据一起保留在废弃队列里,创建进程时,先从废弃队列里找,如果有合适的节点,就直接拿去用,如果没有,就再重新开辟。好比有 100 个实习生要在这几天陆续入职公司,公司会为每个实习生配电脑,如果每来一个实习生,公司就去京东上买台电脑,这样做一方面下单、邮寄,效率太低了;另一方面,每一个人都用新电脑,对于公司来说成本太高了。所以当一个人离职时,并不是把这个人所有信息都销毁、其所使用的电脑卖掉,而是把所有不用的电脑放在一起,当有新的员工入职时,直接从电脑池里拿。
??所以在 Linux 中,这种释放规则叫做
Slab 分配器,它的核心工作是完成在 Linux 内核中数据结构级别的内存分配。 -
“ 释放 ” 程序代码和数据占用的内存空间。
所以有了上面的理解,我们就知道这里的 “ 释放 ” 不是把代码和数据清空,而是把内存设置为无效。比如你从 U 盘里拷贝一个 3G 的电影到你的电脑,你会发现速度特别慢,拷贝 30 秒钟,后来你看完了,你花了 1 秒钟删掉它,这里就有个问题。
如果删除的过程和写入的过程是一个相似的、相反的逻辑,写的过程是在磁盘上把数据以二进制写好,删的过程是相反,那么它们所花的时间应该是相同的 ?
??实际我们在进行删除时,就是对所对应的空间标识为无效,这就意味着它是可以被覆盖的,写入新数据的同时就是在覆盖老数据。所以这里想说的是计算机里的释放并不是真的释放,要么就是利用 Slab 分配器以数据结构的方式缓存起来,要么就是把空间设置为无效,你都可以进行二次覆盖。也就是说以前我们经常看到的把文件删除后,文件就跑到回收站里了,此时并不是真正的删除,而是设置为无用状态,本质是临时删除放进回收站的文件只是在注册表中状态被改为无用状态,而再对回收站中的文件进行删除时,就意味着文件在注册表中被除名,但是文件的数据仍在,所以,即使我们把回收站的文件清空了,照样可以通过注册表来恢复文件。
内存空间怎么做到无效 ?
??内存也要进行管理,其也有对应的数据结构,如果没有人指向这个内存,此时这个内存就是无效的,后面我们学习文件以及多进程时会证明内存无效。
-
取消曾经该进程的链接关系。比如我是子进程,我有 1 个父进程,3 个兄弟进程,除了所有进程本身是用双链表链接的,这里与父和子也有链接关系,所以我要离开了,就要把之前的关系统统去掉。
三、进程等待
💦 进程等待的必要性
之前讲过,子进程退出,父进程如果不管不顾,就可能造成 “ 僵尸进程 ” 的问题,进而造成内存泄漏。另外,进程一旦变成僵尸状态,那就刀枪不入,“ 杀人不眨眼 ” 的kill -9也无能为力,因为谁也没有办法杀死一个已经死去的进程。 最后,父进程派给子进程的任务完成的如何,我们需要知道。如,子进程运行完成,结果对还是不对,或者是否正常退出。父进程通过进程等待的方式,回收子进程资源,获取子进程退出信息。
-
回收僵尸进程,避免内存泄漏。
-
需要获取子进程的运行结束状态、结果。
结束状态和结果不是必须的。注意区分运行状态和运行结果,两者是有区别的。
-
尽量保证父进程要晚于子进程退出,可以规范化进行资源回收。
将来我们写代码时,所有要做的事情都交给子进程,子进程把事办完了,由父进程统一回收。这点其实是与编码相关的策略,而并非属于系统级别的要求。
其实信号部分结束我们就可以知道有一种方案可以让父进程既不等子进程又没有内存泄漏。
💦 进程等待的方法
1、wait方法
#include<sys/types.h>
#include<sys/wait.h>
pid_t wait(int* status);
返回值:
成功则返回被等待进程的pid,失败则返回-1。
参数:
输出型参数,获取子进程退出状态,不关心则可以设置为NULL。wait 的参数 int* status 会重点在下面的 waitpid 学习。
? 测试用例一:
父进程等待子进程退出后,wait 取子进程的 pid。
#include<stdio.h>
#include<stdlib.h>
#include<unistd.h>
#include<sys/types.h>
#include<sys/wait.h>
int main()
{
pid_t id = fork();
if(id < 0)
{
perror("fork");
return 1;
}
else if(id == 0)
{
int count = 5;
while(count)
{
printf("child is running: %d, ppid: %d, pid: %d\n", count--, getppid(), getpid());
sleep(1);
}
printf("child quit...\n");
exit(0);
}
else
{
printf("father is waiting...\n");
pid_t ret = wait(NULL);
printf("father is wait done, ret: %d\n", ret);
}
return 0;
}
💨运行结果:
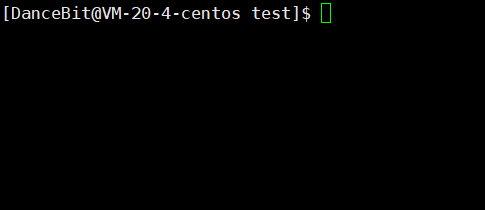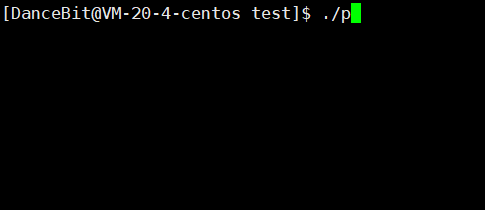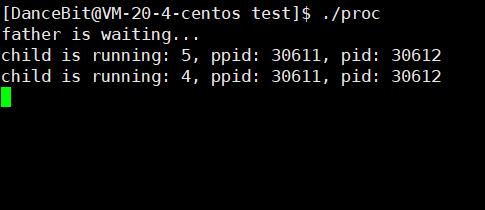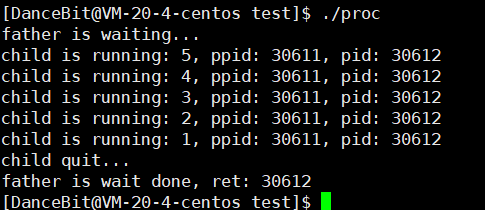
? 测试用例二:
相比测试用例一,更直观的等待,进程从无到有,从有到无。
#include<stdio.h>
#include<stdlib.h>
#include<unistd.h>
#include<sys/types.h>
#include<sys/wait.h>
int main()
{
pid_t id = fork();
if(id < 0)
{
perror("fork");
return 1;
}
else if(id == 0)
{
int count = 5;
while(count)
{
printf("child is running: %d, ppid: %d, pid: %d\n", count--, getppid(), getpid());
sleep(1);
}
printf("child quit...\n");
exit(0);
}
else
{
printf("father is waiting...\n");
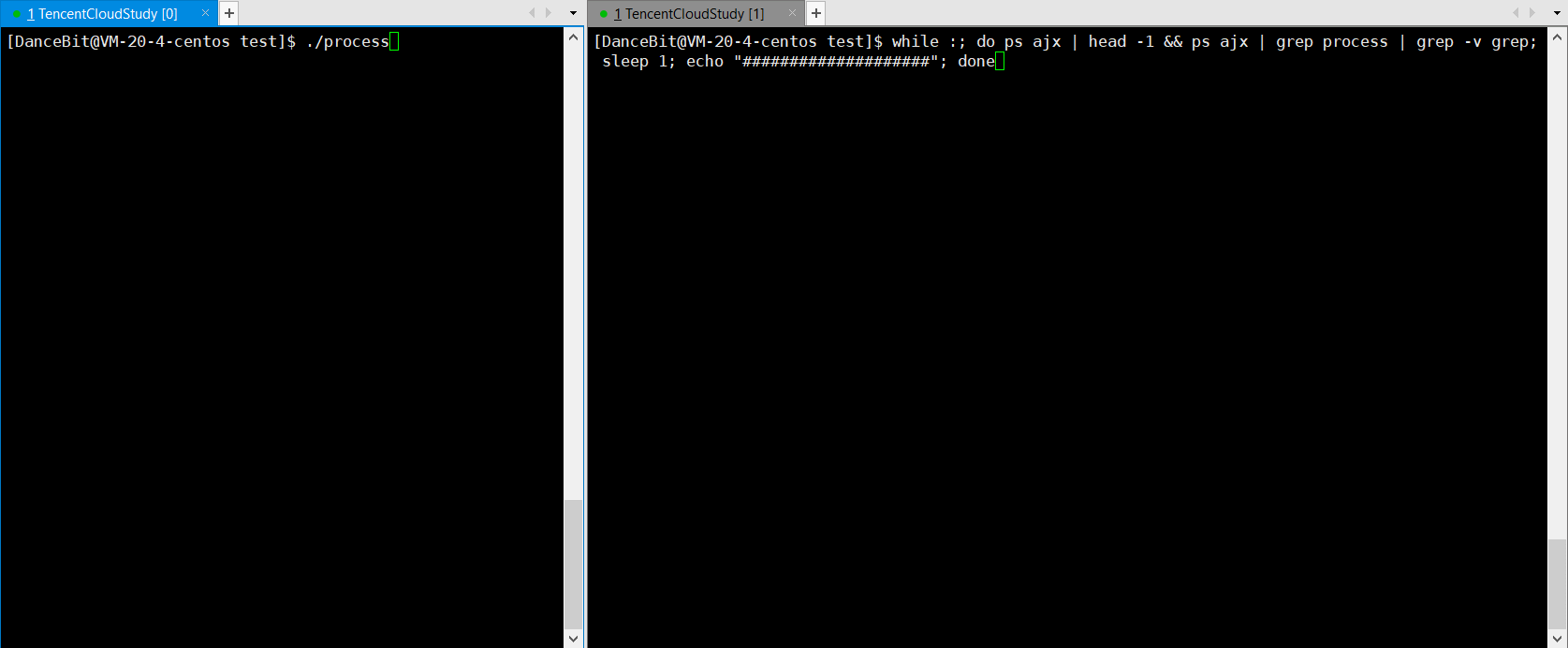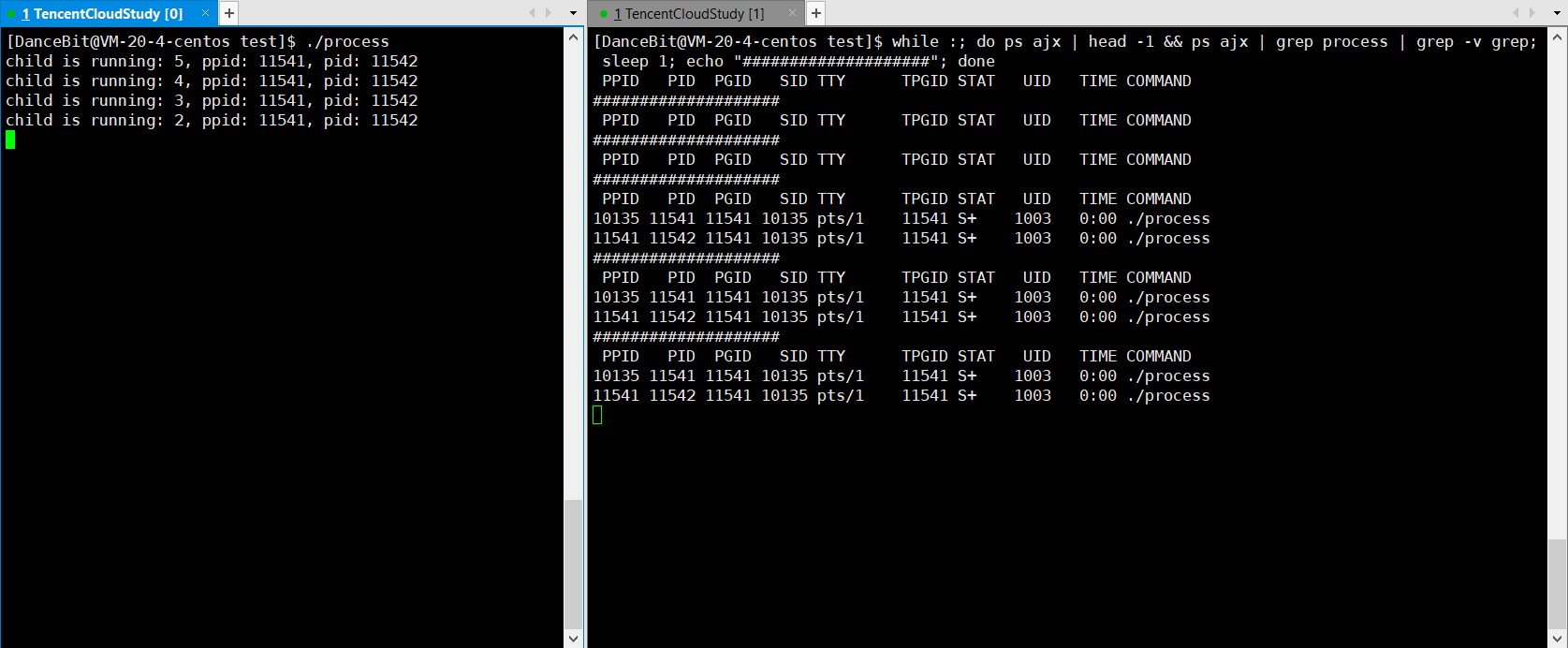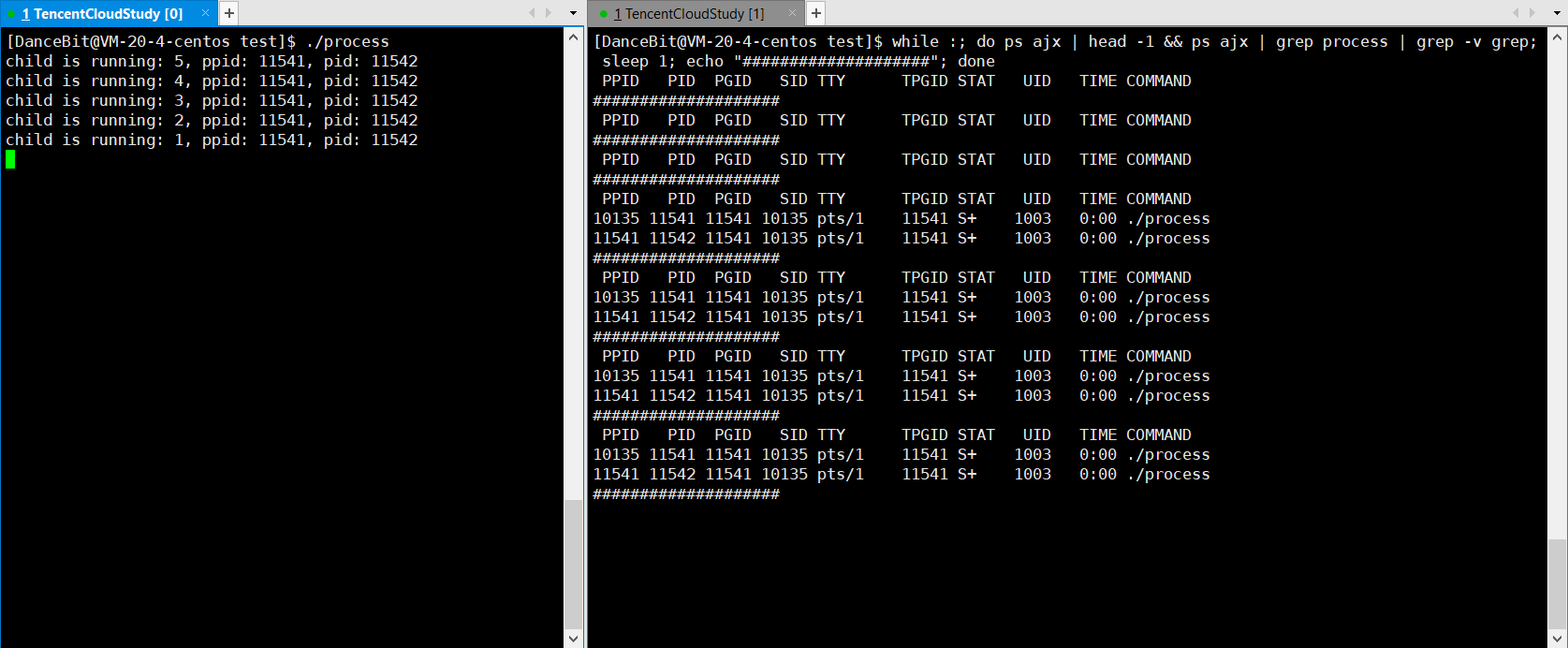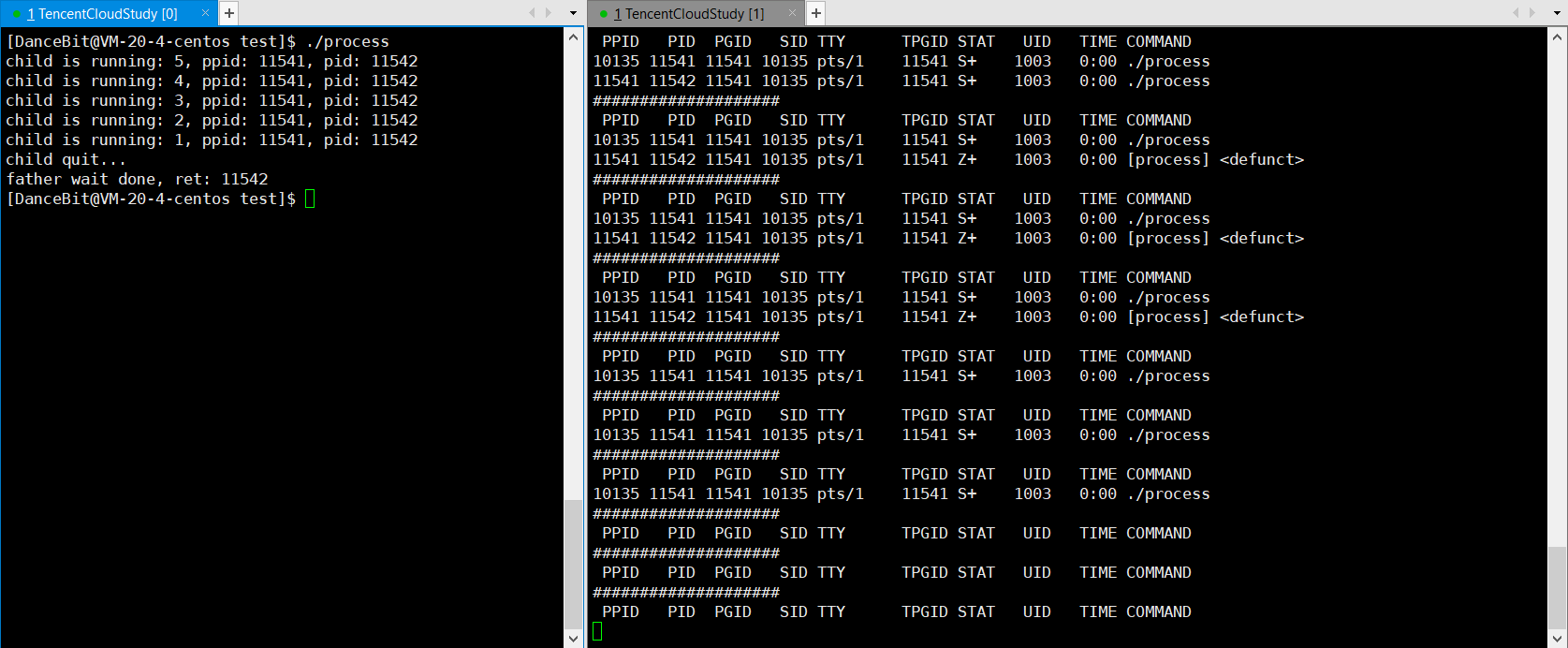
sleep(10);
pid_t ret = wait(NULL);
printf("father is wait done, ret: %d\n", ret);
sleep(3);
printf("father quit...\n");
}
return 0;
}
💨运行结果:
??监控脚本:while :; do ps ajx | head -1 && ps ajx | grep process | grep -v grep; sleep 1; echo "####################"; done
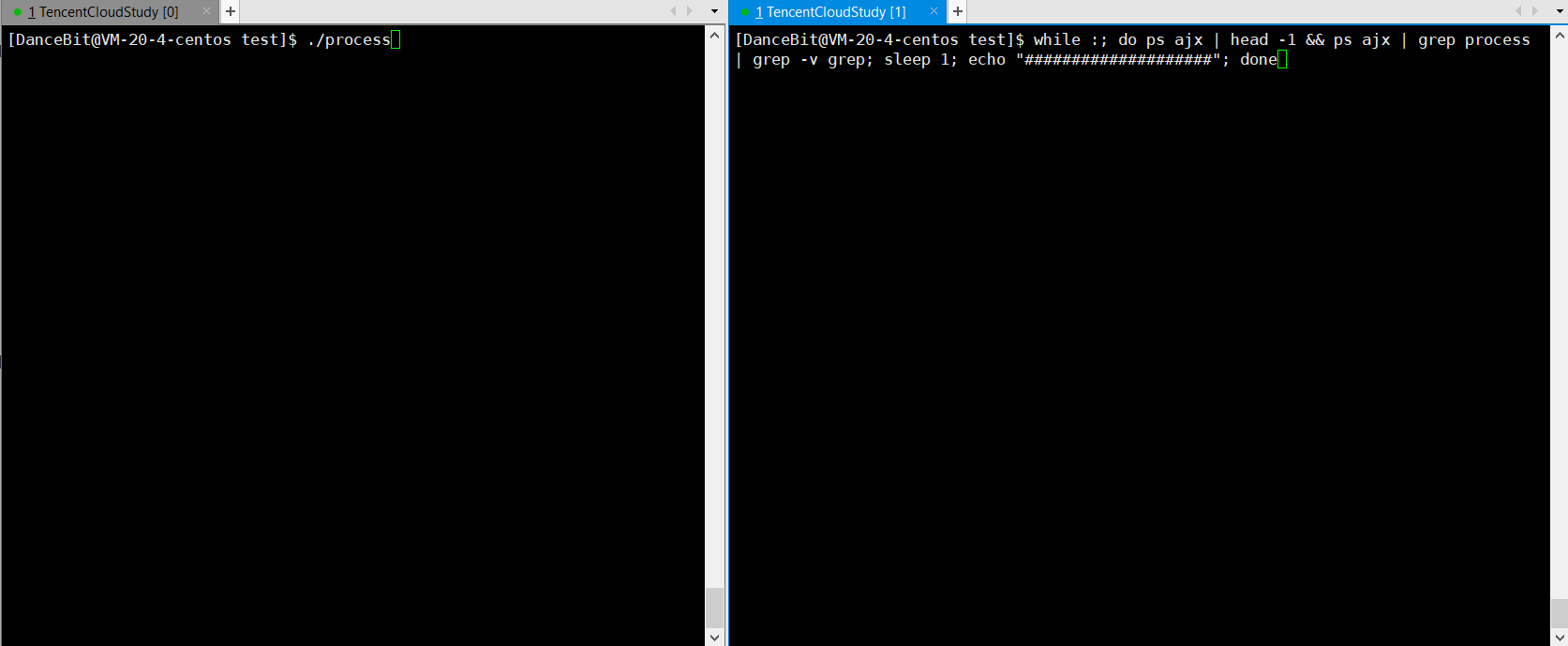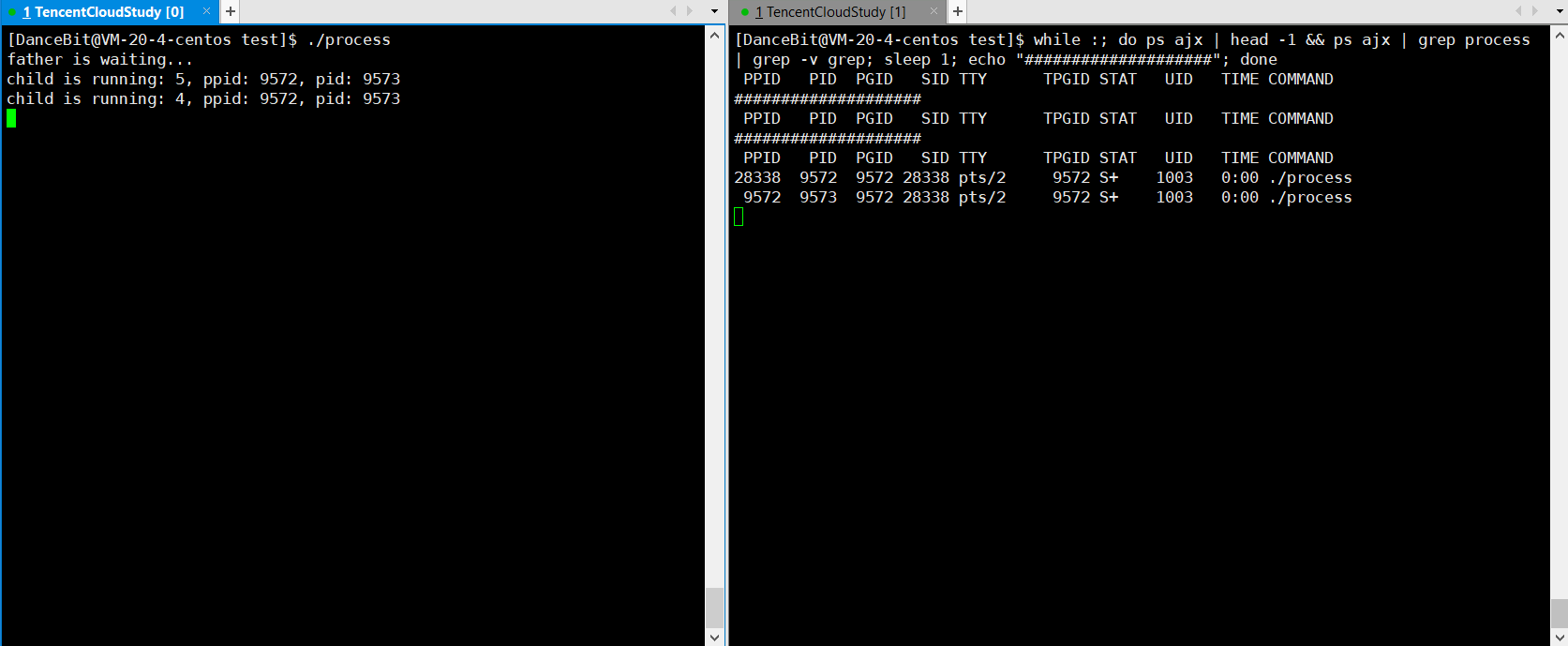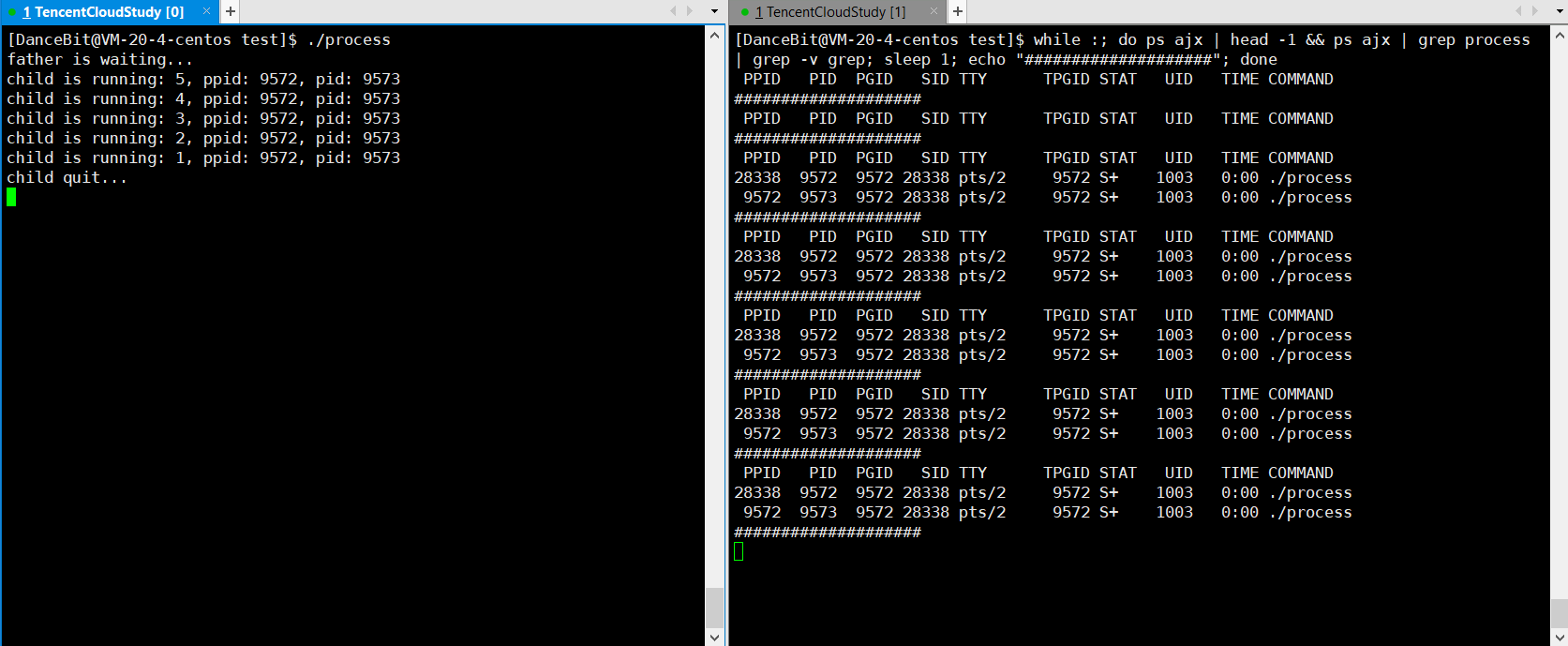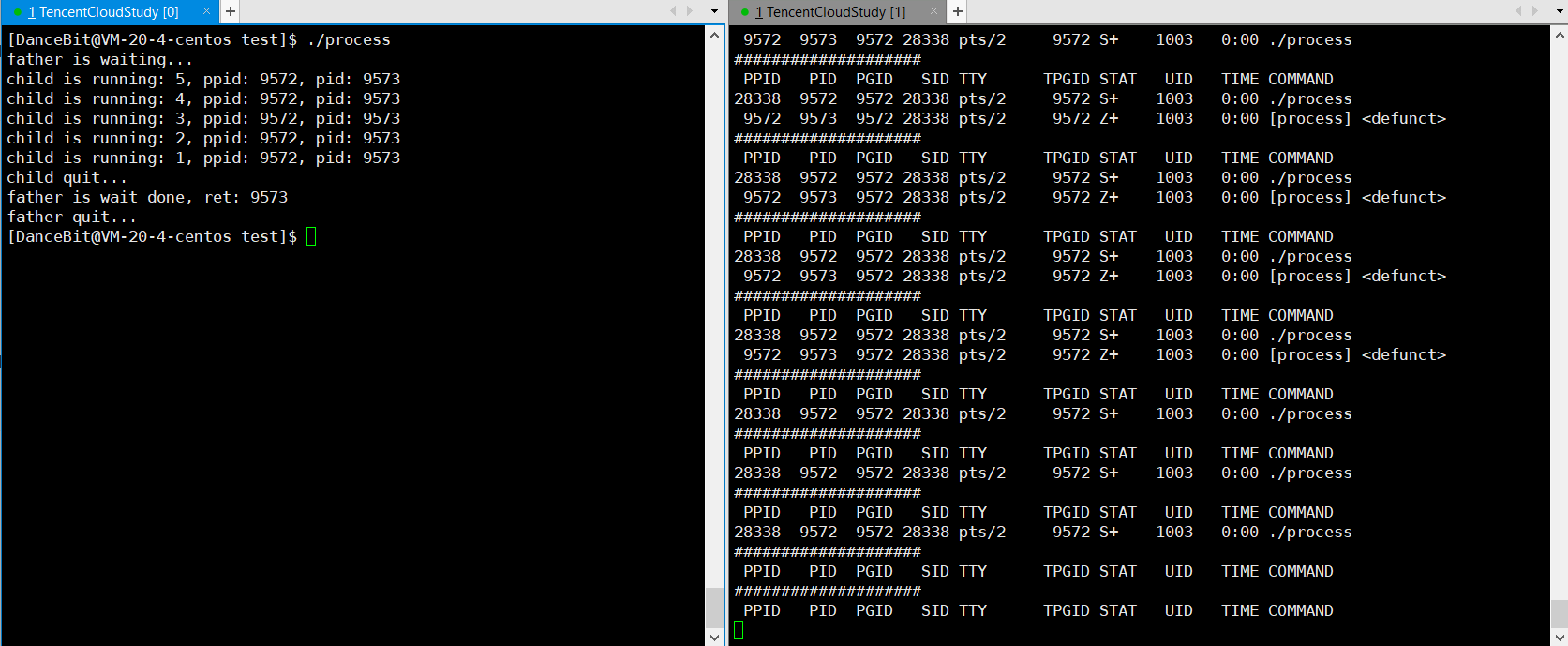
? 测试用例三:
fork 5 个子进程后,父进程依次等待,并回收僵尸进程。
#include<stdio.h>
#include<stdlib.h>
#include<unistd.h>
#include<sys/types.h>
#include<sys/wait.h>
int main()
{
int i = 0;
while(i < 5)
{
pid_t id = fork();
if(id < 0)
{
perror("fork");
return 1;
}
if(id == 0)
{
int count = 5;
while(count)
{
printf("child is running: %d, ppid: %d, pid: %d\n", count--, getppid(), getpid());
sleep(1);
}
printf("child quit...\n");
exit(0);
}
i++;
}
for(i = 0; i < 5; i++)
{
printf("father is waiting...\n");
sleep(10);
pid_t ret = wait(NULL);
printf("father is wait done, ret: %d\n", ret);
sleep(3);
printf("father quit...\n");
}
return 0;
}
💨运行结果:
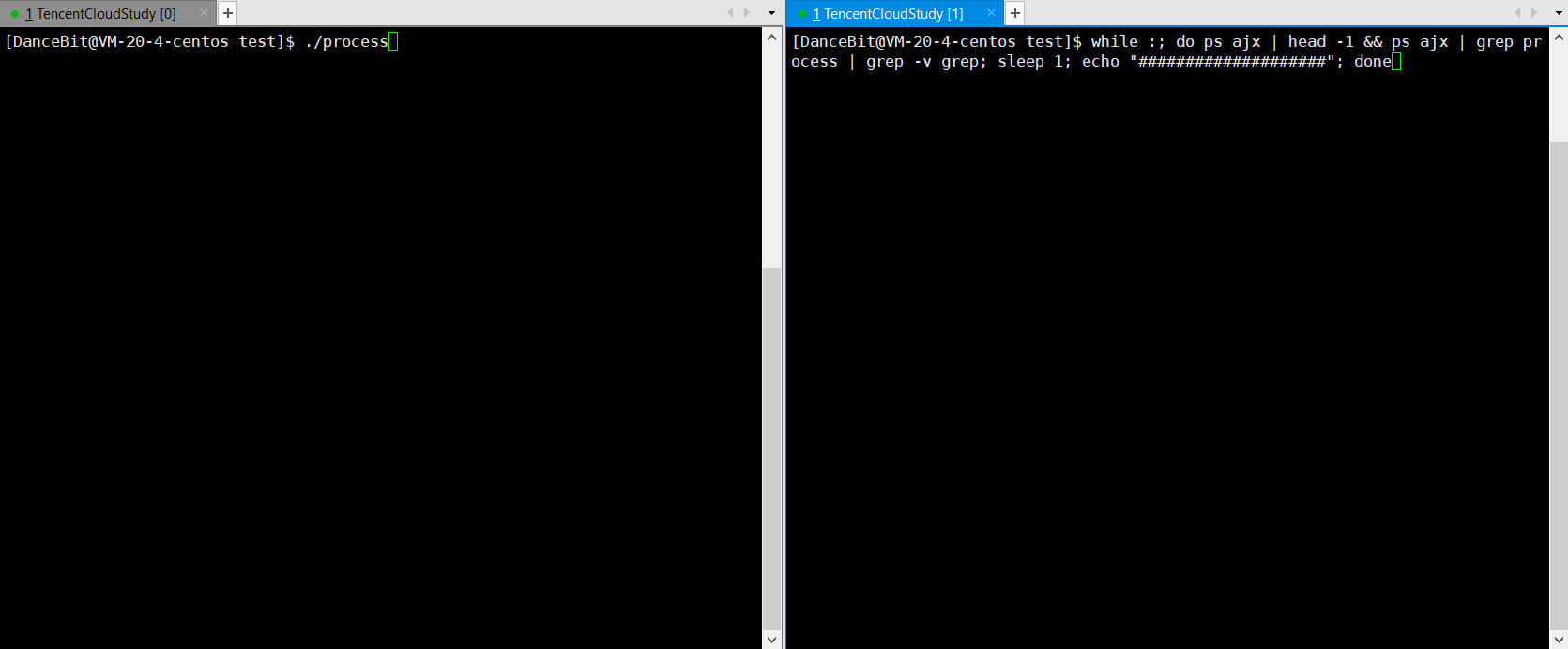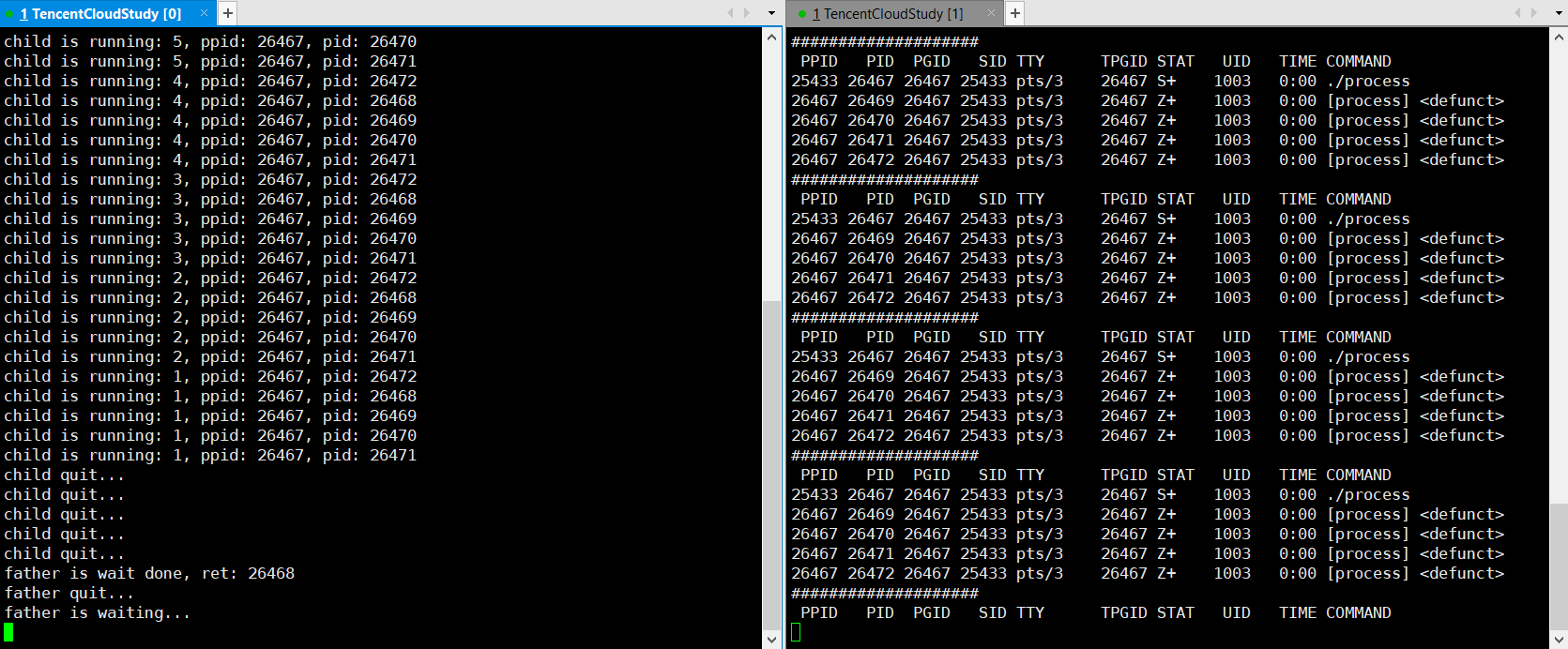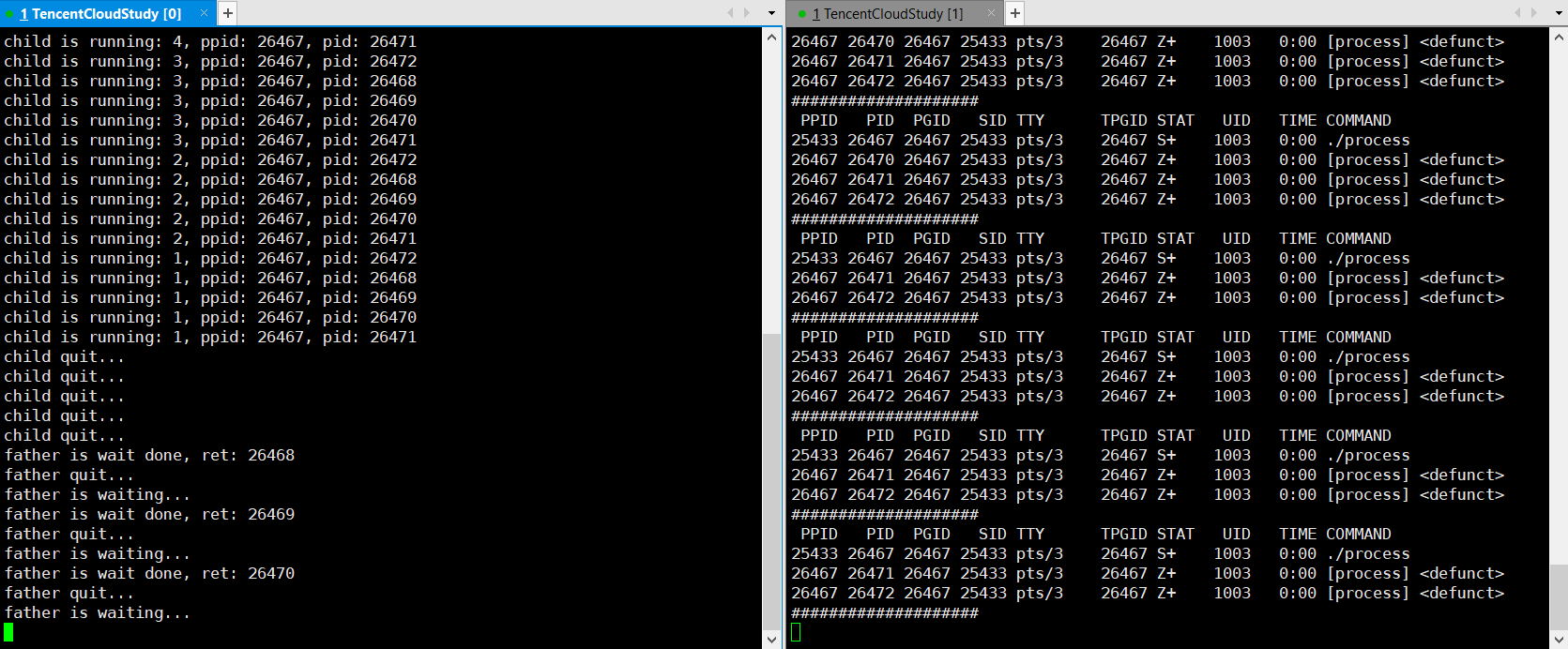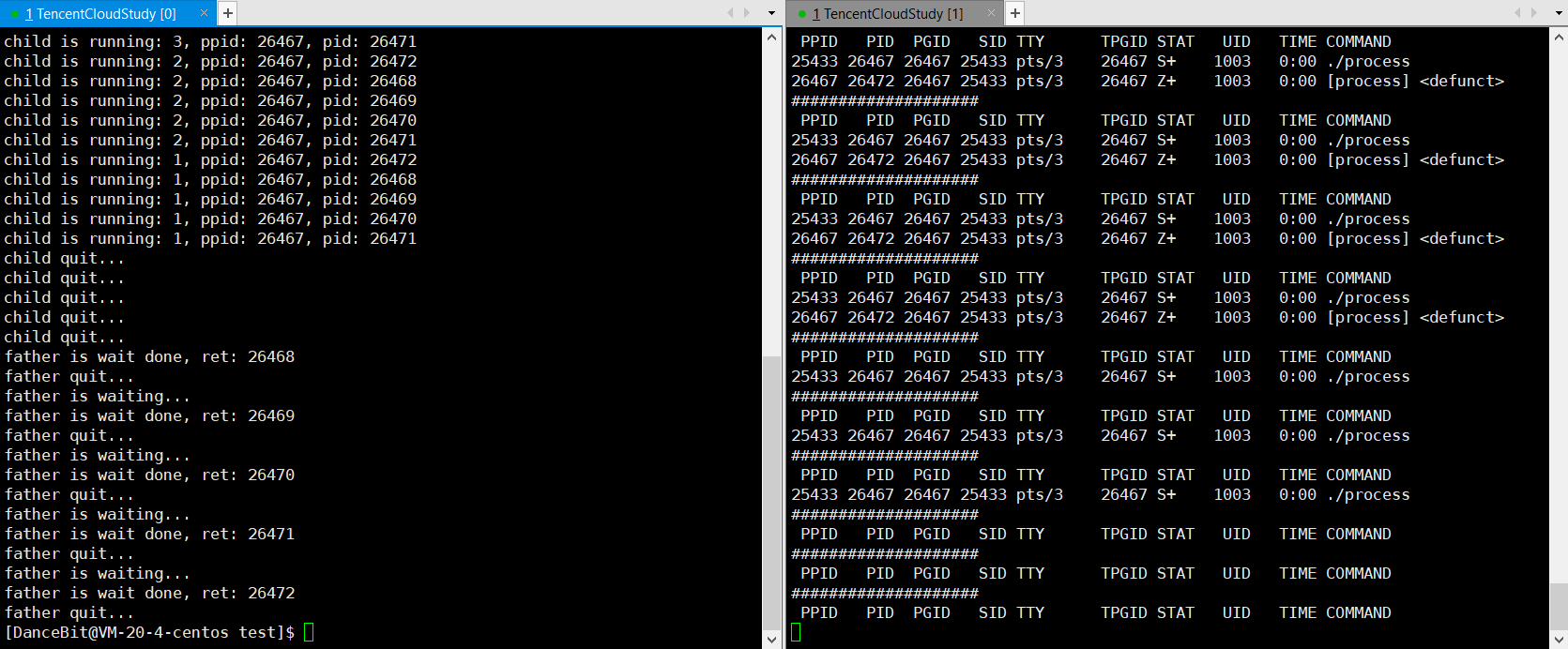
子进程僵尸了,父进程也退出了 ?
??此时 ps ajx 能否看到僵尸进程是不确定的。因为父进程退出,子进程会被操作系统领养。那么这个僵尸进程是在被操作系统领养后立马回收,还是积累到一定的僵尸进程再回收,这是由操作系统的策略决定的,同时也跟当前操作系统的状态有关系,如果操作系统发现内存资源已经很紧张了,就会提前回收。
父进程是如何知道子进程的退出结果呢 ?
??
2、waitpid方法
#include<sys/types.h>
#include<sys/wait.h>
pid_t waitpid(pid_t pid, int* status, int options);
返回值:
当正常返回时,waitpid返回收集到的子进程的进程ID;
如果设置了选项WNOHANG,而调用waitpid时,发现没有已退出的子进程可收集,则返回0;
如果调用中出错,则返回-1,这时errno会被设置成相应的值以指示错误所在;
参数:
pid,
pid=-1,等待任何一个子进程,同wait;
pid>0,等待其进程ID与pid相等的子进程;
因为父进程返回的是子进程的pid,所以父进程就可以等待指定的子进程,等待本质是管理的一种方式;
status,
输出型参数,我们传了一个整数地址进去,最终通过指针解引用把期望的数据拿出来。与之对应的是实参传递给形参是输入型参数;
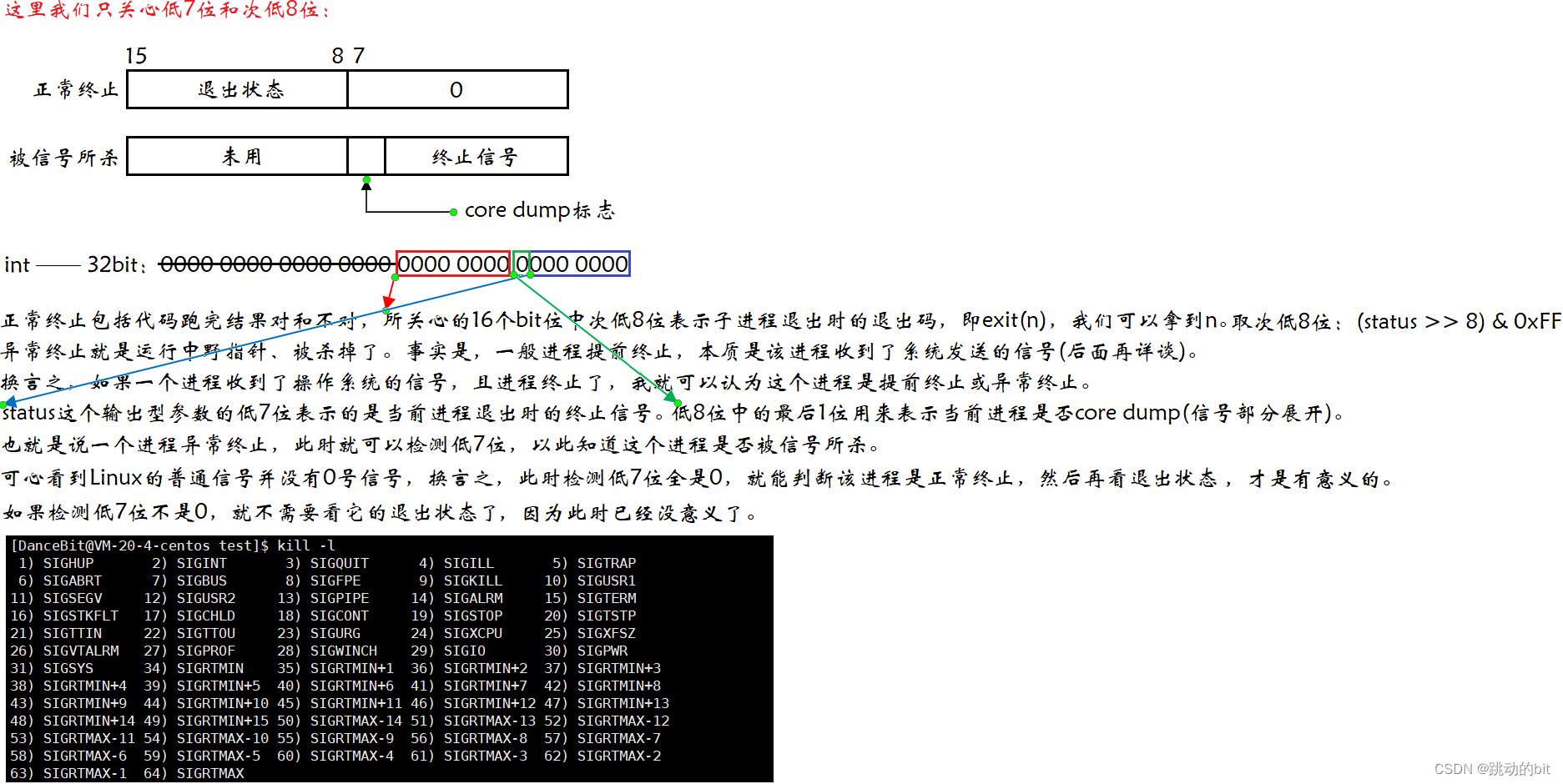
WIFEXITED(status),查看进程是否正常退出,是则真,不是则假;
WEXITSTATUS(status),查看进程退出码,需要WIFEXITED(status)返回true,WIFEXITED(status)正常退出则返回true;
WTERMSIG(status),返回导致子进程终止的信号的编号,需要WIFSIGNALED(status)返回true,WIFSIGNALED(status)子进程被信号终止返回true;
options,
WNOHANG,若pid指定的子进程没有结束,则waitpid()函数返回0,本次不予以等待,需要我们再次等待;若非正常结束,则返回该子进程的ID;或者小于0,失败了。
0,阻塞式等待,同wait――――子进程没退出、回收,父进程等待;
status ?
- wait 和 waitpid,都有一个 status 参数,该参数是一个输出型参数,由操作系统填充。
- 如果传递NULL,表示不关心子进程的退出状态信息。
- 否则,操作系统会根据该参数,将子进程的退出信息反馈给父进程。
- status 不能简单的当作整型来看待,可以当作位图来看待,具体细节如下图(只研究 status 低16 比特位)。
阻塞和非阻塞 ?
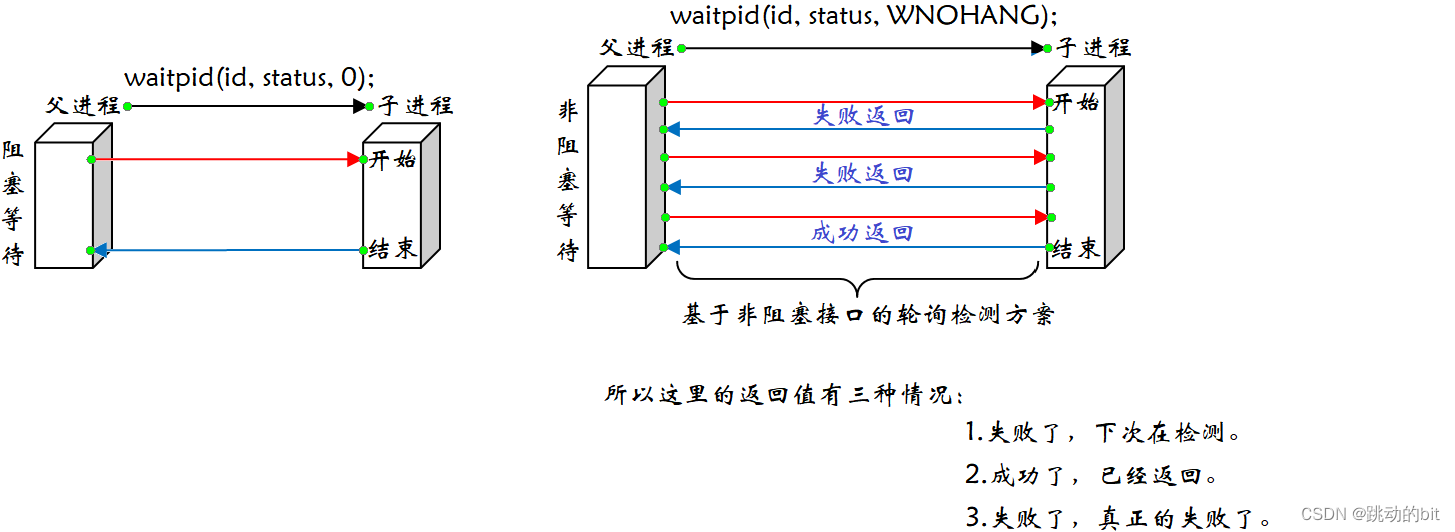
??这个概念我们是第一次接触,也不会深入,后面再学习文件和网络时会经常接触。如果 waitpid 中的 options 传 WNOHANG ,那么等待方式就是非阻塞;如果传 0,那么等待方式就是阻塞。
??比如你的学习很差,所以打电话给楼上学习好的同学张三,说:张三,你下来,我请你吃个饭,然后你帮我复习一下。张三说:行,没问题,但是我在写代码,半个小时之后再来。一般一个班,学习好的人总是少数,所以你怕你电话一挂,有人又跟张三打电话求助,导致你不能及时复习,所以你又跟张三说:张三,你电话不要挂,你把电话放你旁边,我喜欢看你写代码的样子。然后你什么事都不做,就在那等待,直到张三下来。当然现实中很少有这种情况,但是这样的场景是存在的,一般是比较紧急的情况,比如你爸打电话让你做件事且告诉你不要挂电话。此时张三不下来,电话就不挂就类似于调用函数,这种等待方式就叫做阻塞等待。我们目前所调用的函数,全部是阻塞函数,不管是你自己写的、库里的、系统的,阻塞函数最典型的特征是调用 ? 执行 ?返回 ? 结束,其中调用方始终在等待,什么事情都没做。
??又比如,你跟张三说:明天要考试了,一会我们去吃个饭,然后去自习室,你帮我复习下。张三说:没问题,但是我在写代码,你得等我下。你说:行吧,我在食堂等你。然后挂电话。过了两分钟,你给张三打电话说:张三,你来了没。张三说:我还得一会,你再等下。你说:行吧。然后挂电话。又过了两分钟,你又给张三打电话说:张三,你来了没 … … 。你不断重复的给张三打电话,这种场景在生活中比较多,我们经常催一个人做一件事时,他老是不动,你就不断重复给他打电话。你本质并不是给张三打电话,而是检测张三的状态,张三有没有达到我所期望的状态,每次检测张三是不一定立马就就绪的,如他有没有写完、开始下楼等。这里的检测张三的状态,只是想查看进度,所以这里打电话过程并不会把我卡住,我通过多次打电话来检测张三的进度。每次打电话挂电话的过程就叫做非阻塞等待。 我们只要看了它的状态不是就绪,就立马返回。这种基于多次的非阻塞的调用方案叫做非阻塞轮询检测方案。
为什么现实世界中大部分选择非阻塞轮询 ???
??这种高效体现在:主要是对调用方高效,你给张三打电话,张三就要 10 分钟,那就是 10 分钟,类似于计算机,你再怎么催都没用,所以我们就不会死等,我们可以先做其它的事,反正不会让因为等待你,而让我做不了事情。
那为什么我们写的代码大部分都是阻塞调用 ??
??根本原因在于我们的代码都是单执行流,所以选择阻塞调用更简单。
为什么是 WNOHANG ???
??在服务器资源即将被吃完时,卡住了,我们一般称服务器hang住了,进而导致宕机。所以 W 表示等待,NO 表示不要,HANG 表示卡了,所以这个宏的意思是等待时不要卡住。
如何理解父进程等子进程中的 “ 等 ” ???
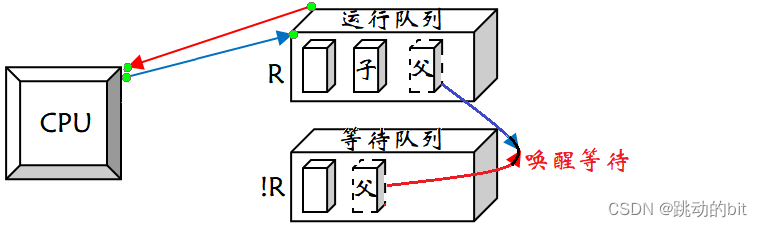
??所谓的等并不是把父进程放在 CPU 上,让父进程在 CPU 上边跑边等。本来父子进程都在运行队列中等待 CPU 运行,当子进程开始被 CPU 运行后,就把父进程由 R 状态更改为 !R 状态,并放入等待队列中,此时父进程就不运行了,它就在等待队列中等待。当子进程运行结束后,操作系统就会把父进程放入运行队列,并将状态更改为 R 状态,让 CPU 运行,这个过程叫做唤醒等待的过程。
操作系统是怎么知道子进程退出时就应该唤醒对应的父进程呢 ??
??wait 和 waitpid 是系统函数,是由操作系统提供的,你是因为调用了操作系统的代码导致你被等待了,操作系统当然知道子进程退出时该唤醒谁。
??这里,我们只要能理解等待就是将当前进程放入等待队列中,将状态设置为 !R 状态。所以一般我们在平时使用计算机时,肉眼所发现的一些现象,如某些软件卡住了,根本原因是要么进程太多了,导致进程没有被 CPU 调度;要么就是进程被放到了等待队列中,长时间不会被 CPU 调度。我们曾经在写 VS 下写过一些错误代码,一旦运行,就会导致 VS 一段时间没有反应。所谓的没有反应就是因为程序导致系统出现问题,操作系统在处理问题区间,把 VS 进程设置成 !R 状态,操作系统处理完,再把 VS 唤醒。
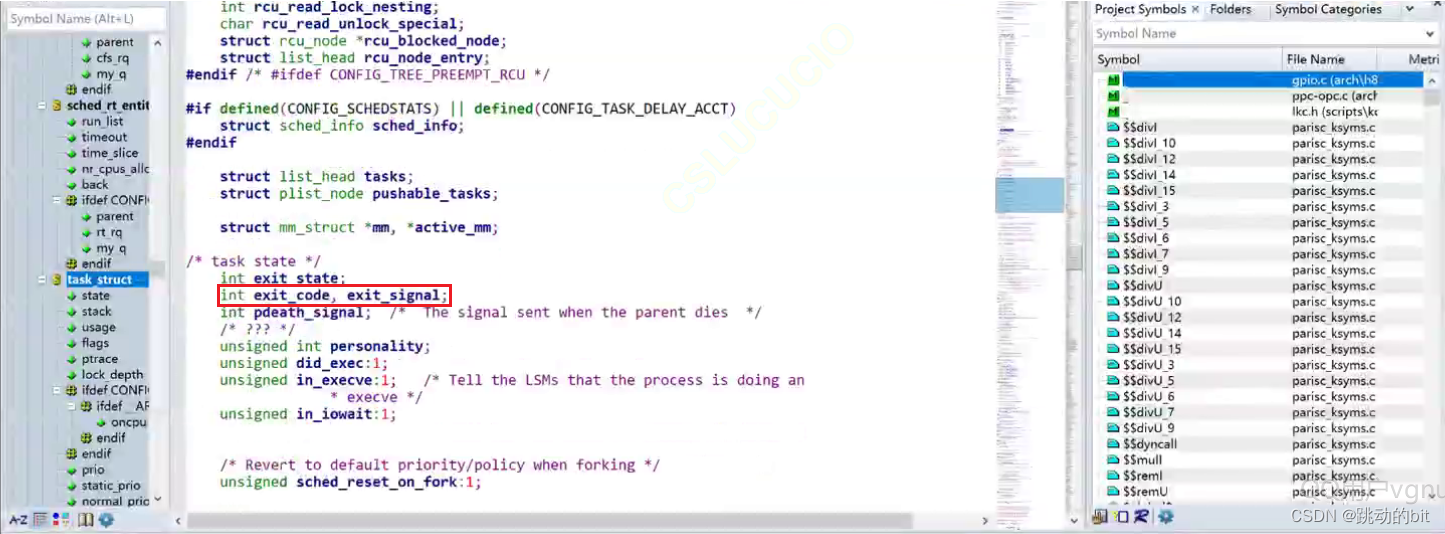
验证子进程僵尸后,退出结果会保存在 PCB 中 ???
??可以看到在 Linux 2.6.32 源码中,task_struct 里包含了退出码和退出信息。
? 测试用例一:
同 wait 测试用例二。
#include<stdio.h>
#include<stdlib.h>
#include<unistd.h>
#include<sys/types.h>
#include<sys/wait.h>
int main()
{
pid_t id = fork();
if(id == 0)
{
int count = 5;
while(count)
{
printf("child is running: %d, ppid: %d, pid: %d\n", count--, getppid(), getpid());
sleep(1);
}
printf("child quit...\n");
exit(0);
}
//father
sleep(8);
pid_t ret = waitpid(id, NULL, 0);//同waitpid(-1, NULL, 0)
printf("father wait done, ret: %d\n", ret);
sleep(3);
return 0;
}
💨运行结果:
? 测试用例二:
父进程 fork 派生一个子进程干活,父进程通过 status 可以知道子进程把活做的怎么样。
#include<stdio.h>
#include<stdlib.h>
#include<unistd.h>
#include<sys/types.h>
#include<sys/wait.h>
int main()
{
pid_t id = fork();
if(id == 0)
{
int count = 5;
while(count)
{
printf("child is running: %d, ppid: %d, pid: %d\n", count--, getppid(), getpid());
sleep(1);
}
printf("child quit...\n");
exit(123);
}
//father
int status = 0;
pid_t ret = waitpid(-1, &status, 0);
int code = (status >> 8) & 0xFF;
printf("%d\n", status);
printf("father wait done, ret: %d, exit code: %d\n", ret, code);
if(code == 0)
{
printf("做好了\n");
}
else
{
printf("没做好\n");
}
return 0;
}
💨运行结果:
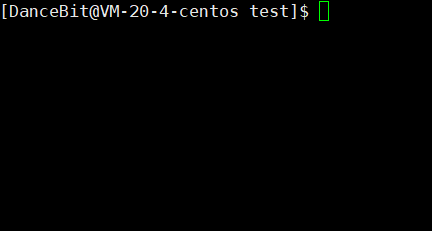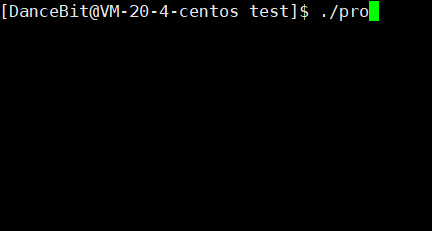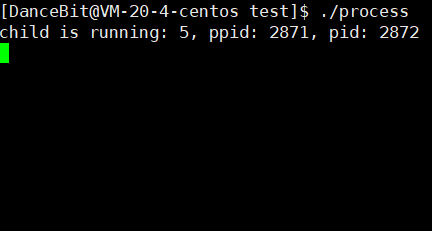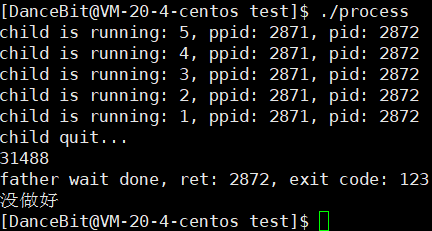
(31488)10 = (0111 1011 0000 0000)2 ;
0111 1011 0000 0000 >> 8 = 0111 1011;
(0111 1011)2 = (123)10 ;
子进程已经退出了,子进程的退出码放在哪 ?
??换句话说,父进程通过 waitpid 要拿子进程的退出码应该从哪里去取呢,明明子进程已经退出了。子进程是结束了,但是子进程的状态是僵尸,也就是说子进程的相关数据结构并没有被完全释放。当子进程退出时,进程的 task_struct 里会被填入当前子进程退出时的退出码,所以 waitpid 拿到的 status 值是通过 task_struct 拿到的。
? 测试用例三:
针对测试用例二,父进程无非就是想知道子进程的工作完成的结果,那全局变量是否可以作为子进程退出码的设置,以此告知父进程子进程的退出码。
#include<stdio.h>
#include<stdlib.h>
#include<unistd.h>
#include<sys/types.h>
#include<sys/wait.h>
int code = 0;
int main()
{
pid_t id = fork();
if(id == 0)
{
int count = 5;
while(count)
{
printf("child is running: %d, ppid: %d, pid: %d\n", count--, getppid(), getpid());
sleep(1);
}
printf("child quit...\n");
code = 123;
exit(0);
}
//father
int status = 0;
pid_t ret = waitpid(-1, &status, 0);
printf("father wait done, ret: %d, exit code: %d\n", ret, code);
if(code == 0)
{
printf("做好了\n");
}
else
{
printf("没做好\n");
}
return 0;
}
💨运行结果:
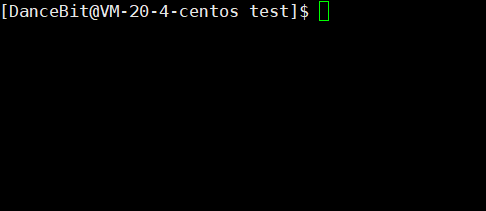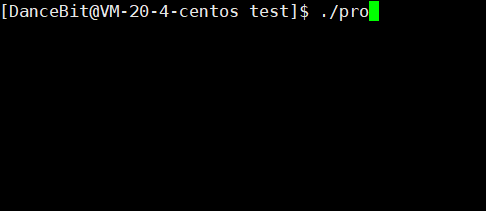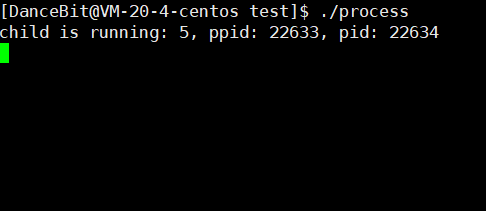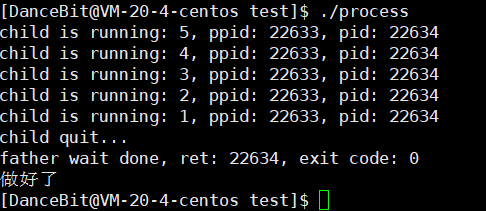
??很显然,不可以。这里对于全局变量,发生了写时拷贝,在进程地址空间里我们说过父子是具有独立性的,虽然变量是同一个,但实际上子进程或父进程所写的数据,它们都是无法看到彼此的,所以不可能让父进程拿到子进程的退出结果。
? 测试用例四:
模拟异常终止 ―― 野指针。
#include<stdio.h>
#include<stdlib.h>
#include<unistd.h>
#include<sys/types.h>
#include<sys/wait.h>
int main()
{
pid_t id = fork();
if(id == 0)
{
int count = 5;
while(count)
{
printf("child is running: %d, ppid: %d, pid: %d\n", count--, getppid(), getpid());
sleep(1);
//err
int* p = 0x12345;
*p = 100;
}
printf("child quit...\n");
exit(123);
}
//father
int status = 0;
pid_t ret = waitpid(-1, &status, 0);
int code = (status >> 8) & 0xFF;
int sig = status & 0x7F;//0111 1111
printf("father wait done, ret: %d, exit code: %d, sig: %d\n", ret, code, sig);
return 0;
}
💨运行结果:

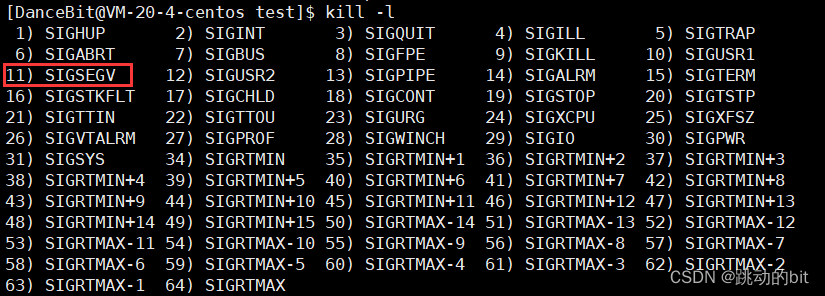
??子进程崩溃后,立马退出,变成僵尸,并不会影响父进程,这叫做父子具有独立性,父进程等待成功(不管你是正常还是非正常退出),随后进行回收。此时子进程的退出码是无意义的,子进程的异常终止导致父进程获得了子进程退出时的退出信号,我们发现它的信号是第 11 号信号(SIGSEGV),它一般都是段错误。
? 测试用例五:
模拟异常终止 ―― 使用kill -9信号亲手杀死子进程。
#include<stdio.h>
#include<stdlib.h>
#include<unistd.h>
#include<sys/types.h>
#include<sys/wait.h>
int main()
{
pid_t id = fork();
if(id == 0)
{
int count = 50;
while(count)
{
printf("child is running: %d, ppid: %d, pid: %d\n", count--, getppid(), getpid());
sleep(1);
}
printf("child quit...\n");
exit(123);
}
//father
int status = 0;
pid_t ret = waitpid(-1, &status, 0);
int code = (status >> 8) & 0xFF;
int sig = status & 0x7F;//0111 1111
printf("father wait done, ret: %d, exit code: %d, sig: %d\n", ret, code, sig);
return 0;
}
💨运行结果:

??当我们把正在运行的子进程亲手杀掉后,父进程立马做回收工作,此时退出码是什么已经不重要了,父进程拿到的信号是第 9 号信号(SIGKILL),此时我们就知道子进程连代码都没跑完,是被别人杀掉才退出的。
? 测试用例五:
父进程完整的等待子进程的全过程。
#include<stdio.h>
#include<stdlib.h>
#include<unistd.h>
#include<sys/types.h>
#include<sys/wait.h>
int main()
{
pid_t id = fork();
if(id == 0)
{
int count = 5;
while(count)
{
printf("child is running: %d, ppid: %d, pid: %d\n", count--, getppid(), getpid());
//err
//int* p = 0x12345;
//*p = 100;
sleep(1);
}
printf("child quit...\n");
exit(123);
}
//father
int status = 0;
pid_t ret = waitpid(id, &status, 0);
if(ret > 0)
{
printf("wait success!\n");
if((status & 0x7F) == 0)
{
printf("process quit normal!\n");
printf("exit code: %d\n", (status >> 8) & 0xFF);
}
else
{
printf("process quit error!\n");
printf("sig: %d\n", status & 0x7F);
}
}
return 0;
}
💨运行结果:
正常,
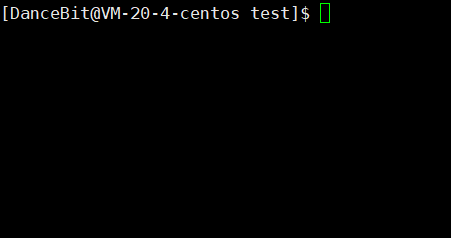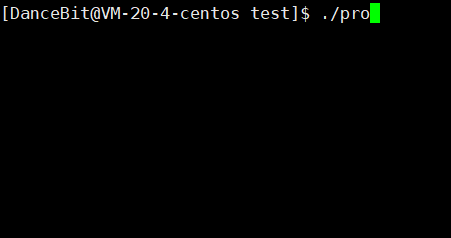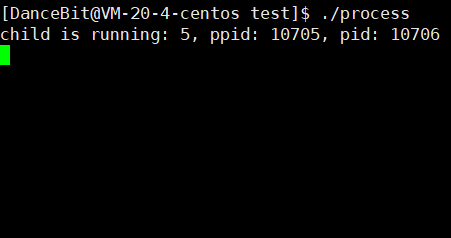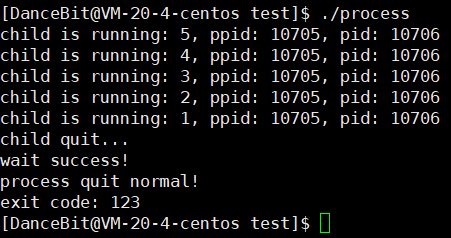
异常,
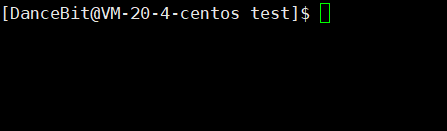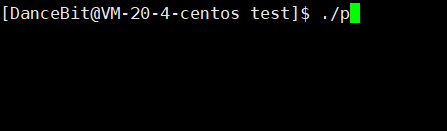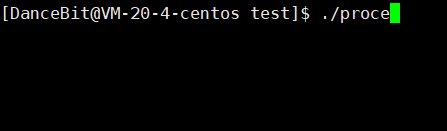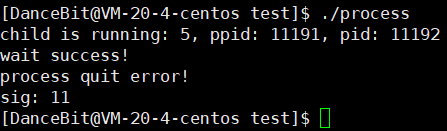
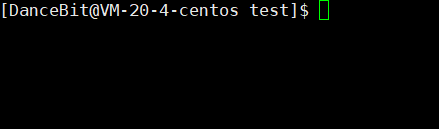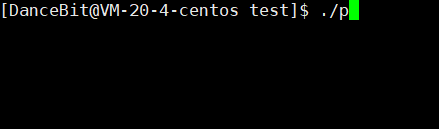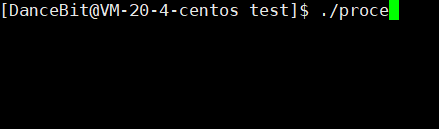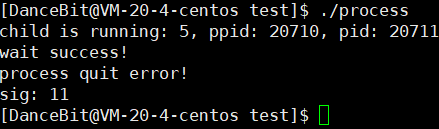
? 测试用例五:
可以看到需要对数据进行加工才可以获取退出码和退出信号,比较麻烦,我们一般也不会自己加工。其实系统有提供一些宏(函数),可以直接使用,我们主要学习 3 个 ―― WIFEXITED(status)、WEXITSTATUS(status)、WTERMSIG(status),其相关介绍可在 waitpid 手册里查找。

#include<stdio.h>
#include<stdlib.h>
#include<unistd.h>
#include<sys/types.h>
#include<sys/wait.h>
int main()
{
pid_t id = fork();
if(id == 0)
{
int count = 5;
while(count)
{
printf("child is running: %d, ppid: %d, pid: %d\n", count--, getppid(), getpid());
//err
//int* p = 0x12345;
//*p = 100;
sleep(1);
}
printf("child quit...\n");
exit(123);
}
//father
int status = 0;
pid_t ret = waitpid(id, &status, 0);
if(ret > 0)
{
printf("wait success!\n");
if(WIFEXITED(status))
{
printf("normal quit!\n");
printf("quit code: %d\n", WEXITSTATUS(status));
}
else
{
printf("process quit error!\n");
printf("sig: %d\n", WTERMSIG(status));
}
}
return 0;
}
💨运行结果:
正常,
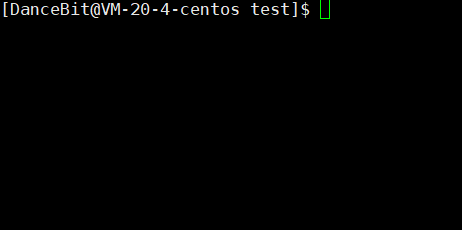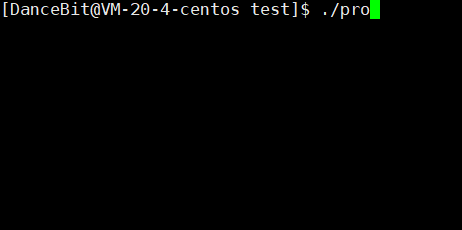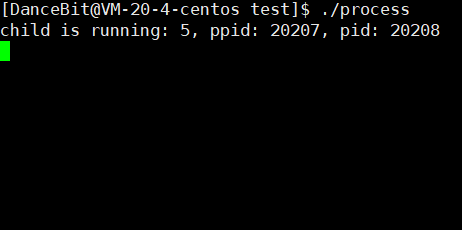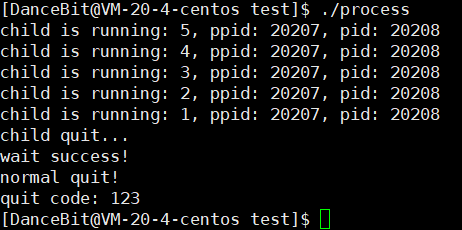
异常,
? 测试用例六:
非阻塞等待。
#include<stdio.h>
#include<stdlib.h>
#include<unistd.h>
#include<sys/types.h>
#include<sys/wait.h>
int main()
{
pid_t id = fork();
if(id == 0)
{
int count = 3;
while(count)
{
printf("child is running: %d, ppid: %d, pid: %d\n", count--, getppid(), getpid());
//err
//int* p = 0x12345;
//*p = 100;
sleep(1);
}
printf("child quit...\n");
exit(123);
}
//father 非阻塞等待
int status = 0;
while(1)
{
pid_t ret = waitpid(id, &status, WNOHANG);
if(ret == 0)
{
printf("wait next!\n");
printf("father do other thing!\n");
}
else if(ret > 0)
{
printf("wait success, ret: %d, pid: %d\n", ret, WEXITSTATUS(status));
break;
}
else
{
printf("wait failed!\n");
break;
}
}
//father 阻塞等待
//int status = 0;
//pid_t ret = waitpid(id, &status, 0);
//if(ret > 0)
//{
// printf("wait success!\n");
// if(WIFEXITED(status))
// {
// printf("normal quit!\n");
// printf("quit code: %d\n", WEXITSTATUS(status));
// }
// else
// {
// printf("process quit error!\n");
// printf("sig: %d\n", WTERMSIG(status));
// }
//}
return 0;
}
💨运行结果:
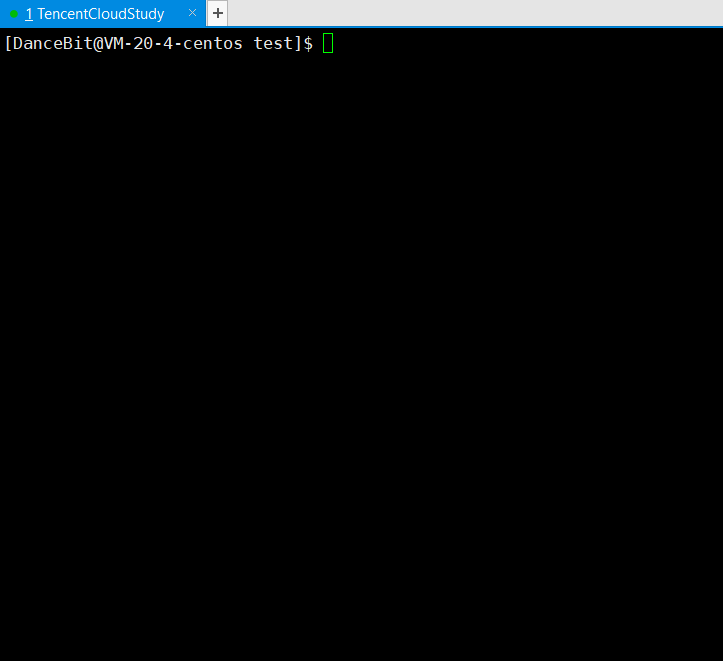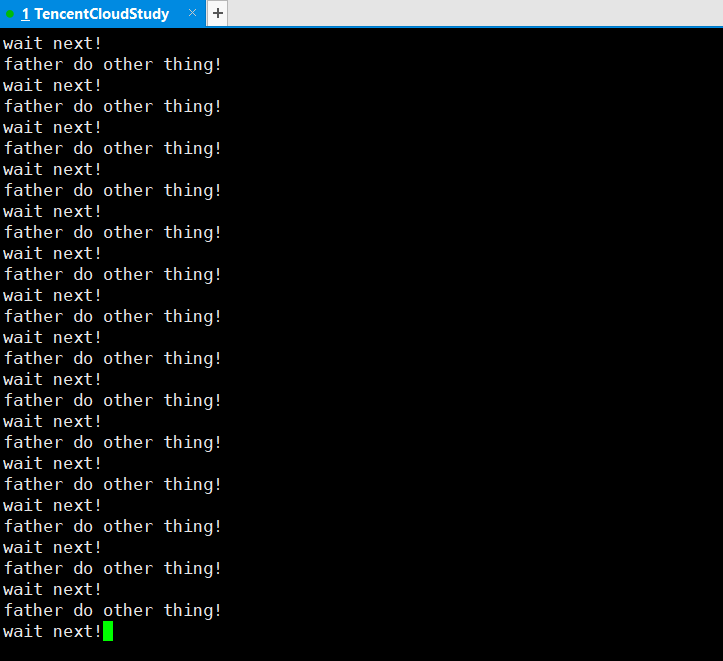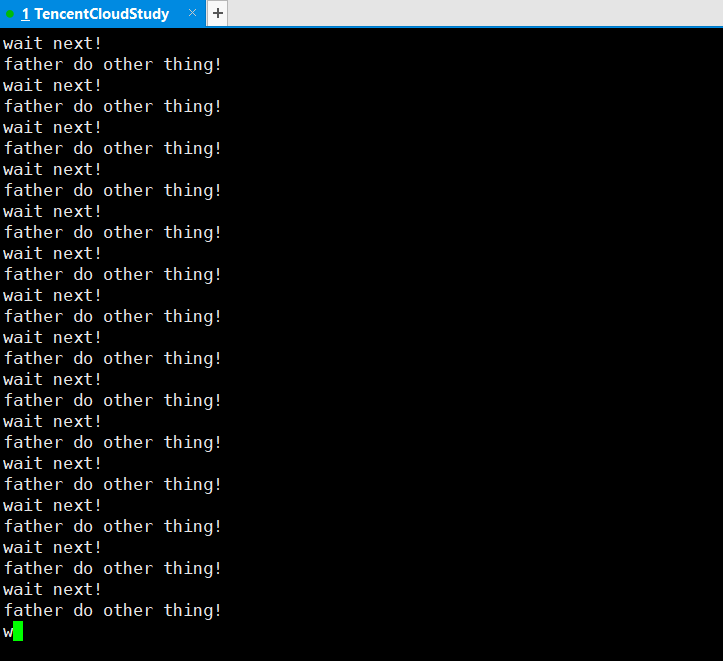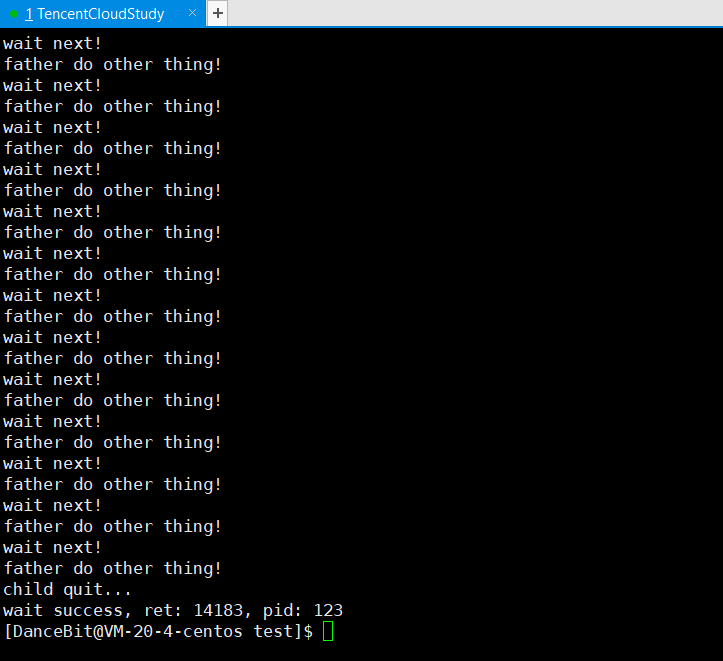
三、进程替换
💦 为什么要进程替换 && 什么是进程替换
创建子进程的目的:
-
执行父进程的部分代码。
我们之前所写的代码都属于这种情况。
-
执行其它程序的代码。
不要父进程的代码和数据。所以我们要学习进程替换。
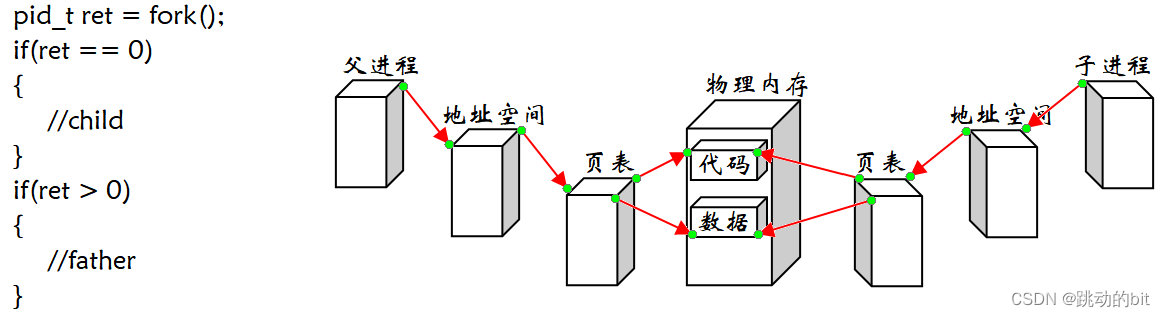
所以进程替换是为了子进程能够执行其它程序的代码;进程替换就是以写时拷贝的策略,让第三方进程的代码和数据替换到父进程的代码和数据,给子进程用,因为进程间具有独立性,所以不会影响父进程。以前我们说数据是可写的,代码是不可写的,现在看来,确实如此。但是接下来要把其它程序的代码通过进程替换放在内存里让子进程与之关联,此时就要给代码进行写时拷贝。99% 的情况是对数据进行写时拷贝,1% 的情况是代码依旧是只读,本质就是对父进程不可写,子进程后续调用某些系统调用,实际给子进程重新开辟空间把新进程的代码加载,不让子进程执行父进程的代码。
💦 替换原理
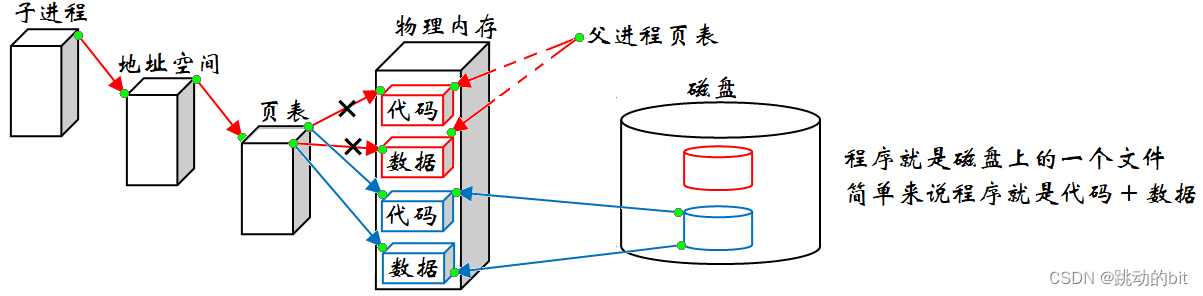
??我们想让子进程里执行新的程序,可以一步到位在内存里重新开辟两块空间以加载新程序的代码和数据,再修改子进程页表的映射关系,之后父子就彻底脱离了。
系统是如何做到重新建立映射关系的呢 ???
??当子进程里要加载新进程时,操作系统可以设置一些特殊信号让该进程对全部代码和数据的写入,子进程会自动触发写时拷贝,重新开辟空间,再重新把代码和数据加载。
在进行进程替换时,有没有创建新的进程 ??
??我们并不需要重新开辟新的 PCB、地址空间、页表,没有创建新进程的最有力证据是 pid 没变。所以我们曾经说过,程序要运行起来,必须先加载到内存,这句话当然没问题。但是反过来,程序只要加载到内存了,一定是变成一个进程,这句话有纰漏,因为进程是否是新创建是不一定的。不过大部分情况下是创建新进程的,进程替换是属于少数。
??所以进程替换不会改变进程内核的数据结构,只会修改部分页表数据,然后把新进程的代码和数据加载至内存,重新构建页表映射关系,和父进程彻底脱离。
💦 替换函数
其实严格来说有7种以exec开头的系列函数,统称exec函数:
#include<unistd.h>
int execl(const chaar* path, const char* arg, ...);
int execlp(const char* file, const chr* arg, ...);
int execv(const char* path, char* const argv[]);
int execvp(const char* file, char* const argv[]);
int execle(const chra* path, const char* arg, ..., char* const envp[]);
int execve(const char* path, char* const argv[], char* const envp[]);
int execvpe(const char* file, char* const argv[], char* const envp[]);
这些函数的功能都是一样的,如果用 C++ 去设计这样的接口,一定是重载。这里是使用 C 去设计的,函数名的命名也有区分。下面我们会对这些接口进行演示,但实际在后面常用的也只是部分而已。
为什么 execve 要单独拎出来 ?
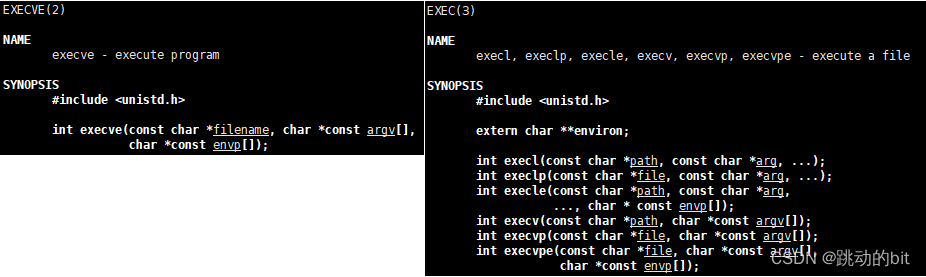
??虽然头文件都是 <unistd.h>,但实际上真正是系统提供函数只有 execve,其余的 6 个都是封装的,最后底层调用的依旧是 execve,这样做的原因是需要根据不同的用户来定制不同的使用场景。
??好比,大家最后吃的米饭都会转换成能量,但是有的人喜欢蛋炒饭、有的人喜欢肉丝炒饭。
💦 函数解释及使用
- 这些函数如果调用成功则加载新的程序从启动代码开始执行,不再返回。
- 如果调用出错则返回 -1。
- 所以 exec 函数只有出错的返回值而没有成功的返回值。
? 测试用例一:

单进程,父进程亲自干活。
#include<stdio.h>
#include<unistd.h>
int main()
{
printf("my process begin!\n");
execl("/usr/bin/ls", "ls", "-a", "-l", "-i", NULL);
printf("my process end!\n");
return 0;
}
多进程,父进程创建子进程干活。
#include<stdio.h>
#include<stdlib.h>
#include<unistd.h>
#include<sys/types.h>
#include<sys/wait.h>
int main()
{
pid_t id = fork();
if(id == 0)
{
printf("I am child, pid: %d, ppid: %d\n", getpid(), getppid());
execl("/usr/bin/ls", "ls", "-a", "-l", "-i", NULL);
exit(1);
}
//father
int status = 0;
pid_t ret = waitpid(id, &status, 0);
if(ret > 0)
{
printf("child status -> sig: %d, code: %d\n", status & 0x7F, (status >> 8) & 0xFF);
}
else
{
printf("wait error!\n");
}
return 0;
}
💨运行结果:
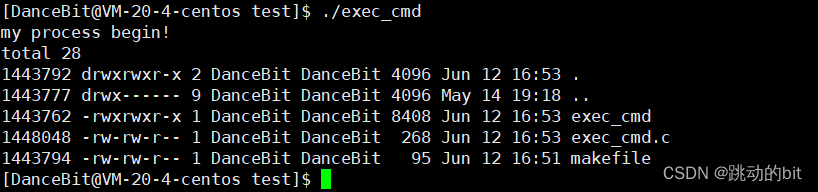
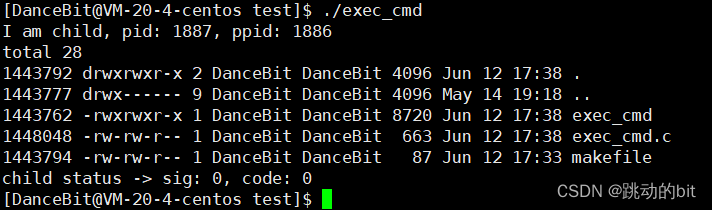
为什么图一没有输出 my process end ! && 图二的退出码是 0 ?
??因为在这之前 execl 已经程序替换了,所以 execl 后面的代码已经不是当前进程的代码了,所以图二获取到的退出码 0 是 ls 的退出码。换言之,一旦程序替换,你到底执行正确与否是取决于 ls 程序。
??所以 exec 系列的函数不用考虑返回值,只要返回了,一定是这个函数调用或程序替换失败了。
??注意编程规范是父进程创建子进程干活。
加载器 ?
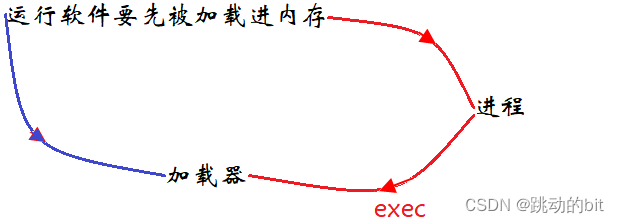
??一个完整的集成开发环境的组件肯定包括编辑器、编译器、调试器、加载器等。一个软件被加载到内存里,肯定是运行起来,形成进程,进程再调用 exec 系列的函数就可以完成加载的过程。所以 exec 可以理解成一种特殊的加载器。
? 测试用例二:

execv 与 execl 较为类似,它们的唯一差别是,如果需要传多个参数,那么:execl 是以可变参数的形式进行列表传参;execv 是以指针数组的形式传参。
#include<stdio.h>
#include<stdlib.h>
#include<unistd.h>
#include<sys/types.h>
#include<sys/wait.h>
int main()
{
pid_t id = fork();
if(id == 0)
{
//const char* const my_argv[] = {"ls", "-l", "-a", "-i", NULL};//err,注意要与函数原型的参数类型匹配
char* const my_argv[] = {"ls", "-l", "-a", "-i", NULL};
printf("I am child, pid: %d, ppid: %d\n", getpid(), getppid());
execv("/usr/bin/ls", my_argv);
exit(1);
}
//father
int status = 0;
pid_t ret = waitpid(id, &status, 0);
if(ret > 0)
{
printf("child status -> sig: %d, code: %d\n", status & 0x7F, (status >> 8) & 0xFF);
}
else
{
printf("wait error!\n");
}
return 0;
}
💨运行结果:
? 测试用例三:

execlp 相比 execl 在命名上多了 1 个 p,且参数只有第 1 个不同:不同点在于 execlp 不需要带路径,execlp 在执行时,它会拿着你要执行的程序自动的在系统 PATH 环境变量中查找你要执行的目标程序。
#include<stdio.h>
#include<stdlib.h>
#include<unistd.h>
#include<sys/types.h>
#include<sys/wait.h>
int main()
{
pid_t id = fork();
if(id == 0)
{
printf("I am child, pid: %d, ppid: %d\n", getpid(), getppid());
execlp("ls", "ls", "-a", "-i", "-l", NULL);
exit(1);
}
//father
int status = 0;
pid_t ret = waitpid(id, &status, 0);
if(ret > 0)
{
printf("child status -> sig: %d, code: %d\n", status & 0x7F, (status >> 8) & 0xFF);
}
else
{
printf("wait error!\n");
}
return 0;
}
💨运行结果:
带 p 的含义就是不用带路径,系统会自动搜索你要执行的程序,不带 p 则相反。所以你要执行哪个程序,背后的含义是 a) 你在哪 b) 你是谁。可见 execlp 就是 b,execl 就是 ab。当然这里的搜索默认只有系统的命令才能找到,如果需要执行自己的命令,需要提前把自己的命令与 PATH 关联。
? 测试用例四:

所以 execvp 无非就是不带路径,使用指针数组传参。
#include<stdio.h>
#include<stdlib.h>
#include<unistd.h>
#include<sys/types.h>
#include<sys/wait.h>
int main()
{
pid_t id = fork();
if(id == 0)
{
char* const my_argv[] = {"ls", "-l", "-a", "-i", NULL};
printf("I am child, pid: %d, ppid: %d\n", getpid(), getppid());
execvp("ls", my_argv);
exit(1);
}
//father
int status = 0;
pid_t ret = waitpid(id, &status, 0);
if(ret > 0)
{
printf("child status -> sig: %d, code: %d\n", status & 0x7F, (status >> 8) & 0xFF);
}
else
{
printf("wait error!\n");
}
return 0;
}
💨运行结果:
? 测试用例五:
e 表示传入默认的或者自定义的环境变量给目标可执行程序。

子进程跑自己的程序 mycmd.c。

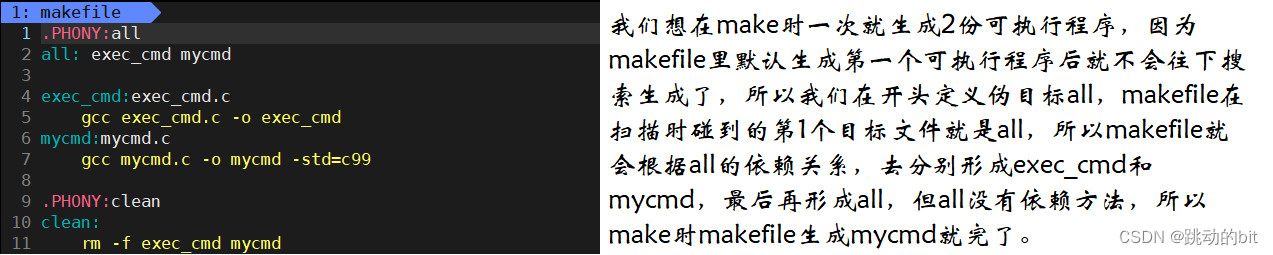
makefile 里需要 make 时一次生成 2 份可执行程序。
#include<stdio.h>
#include<stdlib.h>
#include<unistd.h>
#include<sys/types.h>
#include<sys/wait.h>
int main(int argc, char* argv[], char* env[])
{
pid_t id = fork();
if(id == 0)
{
char* const my_env[] = {"MYENV=hellobit!", NULL};
printf("I am child, pid: %d, ppid: %d\n", getpid(), getppid());
//测试1
//execle("./mycmd", "mycmd", NULL, my_env);
//测试2
//char* const my_argv[] = {"mycmd", NULL};
//execve("./mycmd", my_argv, my_env);
//测试3
//execvpe("mycmd", my_argv, my_env);
//测试4
execle("./mycmd", "mycmd", NULL, env);
exit(1);
}
//father
int status = 0;
pid_t ret = waitpid(id, &status, 0);
if(ret > 0)
{
printf("child status -> sig: %d, code: %d\n", status & 0x7F, (status >> 8) & 0xFF);
}
else
{
printf("wait error!\n");
}
return 0;
}
💨运行结果:
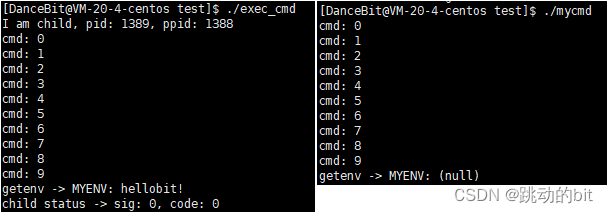
-
测试 1 && 测试 2
-
测试 3

??execvpe 并没有替换成功,因为它带了 p,所以它会在环境变量里查找目标程序,但是此时目标程序就在当前路径。所以当前场景是不适合使用带 p 的函数的。如果想让 execvpe 查找到目标程序,就只能将当前路径添加到环境变量中,或将目标程序添加到任意环境变量的路径下。
-
测试 4
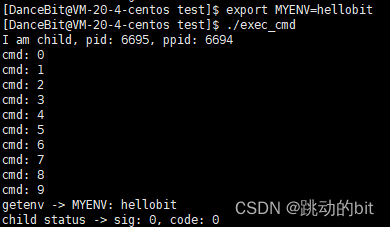
??main 函数可以获得环境变量,环境变量再传给子进程。所以现在我们就能理解环境变量是怎么被子进程继承的,本质是通过 exec 函数将环境变量传入的。
💦 命名理解
这些函数原型看起来很容易混淆,但只要掌握了规律就很好记。
- l(list),表示参数采用列表。
- v(vector),表示参数使用数组。
- p(path),自动搜索环境变量 PATH。
- e(env),表示自己维护环境变量。
💦 简单模拟shell解释器
子进程执行新程序的需求 ?
??在之前,我们举过 1 个例子:你是村长家的儿子,是程序员,你不擅长和女生打交道,所以你去通过王婆去找如花表达你的爱意,村里人都知道如花已经心有所属了,而你又是村长家的儿子。王婆心想,这趟浑水我可不不趟,万一搞砸了,可能会影响到自己以后的职业发展,但又碍于你是村长家的儿子,不敢得罪。所以,机智的王婆说:呀!最近的活太多了,这样吧,我给你找我们公司的销冠(其实是实习生,比较好欺负),你自己跟销冠对接。就算谈不成,王婆也可以周旋(再给你找业务好的实习生)。王婆会根据工作的难易程度,简单的自己做,复杂的交给其它人。
??这里你是用户;王婆是命令行解释器中的 bash;销冠(实习生)是子进程;如花是操作系统;销冠(实习生)谈砸了,不影响王婆就如子进程崩了不会影响父进程。
? 测试用例一:
#include<stdio.h>
#include<stdlib.h>
#include<string.h>
#include<unistd.h>
#include<sys/types.h>
#include<sys/wait.h>
#define NUM 128
#define SIZE 32
char command_line[NUM];
char* command_parse[SIZE];
int main()
{
while(1)
{
//1.获取命令
memset(command_line, '\0', sizeof(command_line));
printf("[DanceBit@myhost myshell]$ ");
fflush(stdout);
if(fgets(command_line, NUM - 1, stdin))
{
command_line[strlen(command_line) - 1] = '\0';//\n = '\0'
//2.加工命令
int index = 0;
command_parse[index] = strtok(command_line, " ");//strtok以空格分割"ls -a -l"于指针数组,strtok可以适用于"ls -a -l"。
while(1)
{
index++;
command_parse[index] = strtok(NULL, " ");
if(command_parse[index] == NULL)
{
break;
}
}
//3.执行非内置命令
if(fork() == 0)
{
//child
execvp(command_parse[0], command_parse);//我们选择v、p。
exit(1);//父进程拿到1,说明execvp替换失败。
}
//father
int status = 0;
pid_t ret = waitpid(-1, &status, 0);
if(ret > 0 && WIFEXITED(status))
{
printf("Exit Code: %d\n", WEXITSTATUS(status));
}
}
}
return 0;
}
💨运行结果:
??可以看到我们自己模拟的 shell 可以支持大部分命令,但有部分命令是不支持的,如 ll、>、| 。不支持的原因也很好理解,重定向和管道是需要我们理解了它的原理,然后才能实现的,后面我们再对 myshell 进行完善。
myshell 和 mini_shell 中使用的 echo 是同一个 echo 吗 ?

??不一定,如果感觉有些抽象的话,可以这么理解:有些命令实际让子进程去运行,子进程是不影响父进程的,此时有可能就会出现一些奇怪的现象,如。

为什么 ???
-
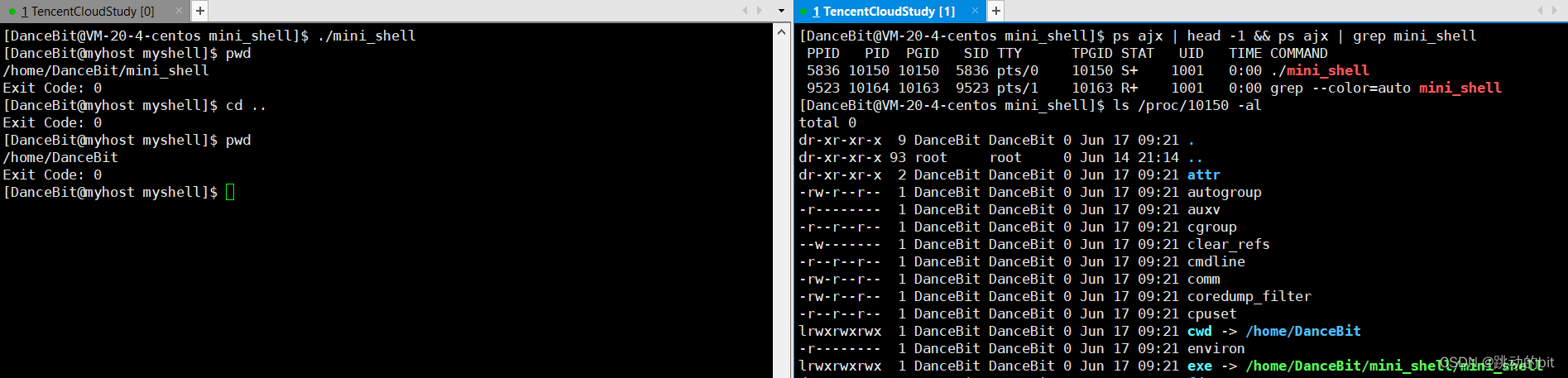
ps ajx | head -1 && ps ajx | grep mini_shell查看 mini_shell 进程信息。
-
ls /proc/20339 -al查看 mini_shell 20339 进程相关资源。
??其中 cwd 是当前所处的目录,exe 是执行程序的名字。我们发现在 myshell 中
cd ../../../执行是成功的,但路径并没有任何变化。这里的 cd 更改的是父进程所在路径还是子进程所在路径 ??
??我们需要明确一件事,在 cd.. 时,是期望更改子进程还是父进程的路径呢。子进程是目标程序,父进程是 shell。实际上我们想改的并不是子进程,因为子进程的路径一改,子进程就退出了,改就没有意义了。所以我们要改的是父进程的路径,换言之,你要改父进程的路径的前提是不能创建子进程执行 cd。父进程也不能执行 cd,因为父进程一旦替换就会把父进程的代码替换成 cd 的代码,父进程不仅越俎代庖,自己的本职工作也没做好。
??其实虽然 cd 像命令,但实际上在 shell 中就压根不能使用程序替换执行,它使用系统接口来完成 “ 命令的执行 ”,这个接口是 chdir。
#include<unistd.h> int chdir(const char* path);
? 测试用例二:
支持 cd。
#include<stdio.h>
#include<stdlib.h>
#include<string.h>
#include<unistd.h>
#include<sys/types.h>
#include<sys/wait.h>
#define NUM 128
#define SIZE 32
char command_line[NUM];
char* command_parse[SIZE];
int main()
{
while(1)
{
//1.获取命令
memset(command_line, '\0', sizeof(command_line));
printf("[DanceBit@myhost myshell]$ ");
fflush(stdout);
if(fgets(command_line, NUM - 1, stdin))
{
command_line[strlen(command_line) - 1] = '\0';//\n = '\0'
//2.加工命令
int index = 0;
command_parse[index] = strtok(command_line, " ");//strtok以空格分割"ls -a -l"于指针数组,strtok可以适用于"ls -a -l"。
while(1)
{
index++;
command_parse[index] = strtok(NULL, " ");
if(command_parse[index] == NULL)
{
break;
}
}
//3.执行第三方命令(内置命令)
if(strcmp(command_parse[0], "cd") == 0 && chdir(command_parse[1]) == 0)
{
continue;
}
//4.执行非内置命令
if(fork() == 0)
{
//child
execvp(command_parse[0], command_parse);//我们选择v、p。
exit(1);//父进程拿到1,说明execvp替换失败。
}
//father
int status = 0;
pid_t ret = waitpid(-1, &status, 0);
if(ret > 0 && WIFEXITED(status))
{
printf("Exit Code: %d\n", WEXITSTATUS(status));
}
}
}
return 0;
}
💨运行结果:
??可以看到这样的 cd 命令并没有创建子进程去执行,本质 cd 是内置命令,它是 shell 内的一个函数调用。所以这里简单的工作,shell 自己做,复杂的就交给子进程做。