һ.�ļ��������
1. �鿴�ļ����ݾ���ʹ�õ�����
cat : �ɵ�һ����ʾ�ļ�����
tac: ?�����һ���_ʼ��ʾ����cat�෴
nl : ?�ļ����ݺ��к�һ�����
more: һҳһҳ��ʾ
less: ��more����,�ܹ���ǰ��ҳ
head: ȡͷ������
tail: ?ȡβ������
od: ����������ʽ��ȡ�ļ�����
2. cat����
�鿴cat�ą��� cat --h
$ cat --h
Usage: cat [OPTION] [FILE]...
Concatenate FILE(s), or standard input, to standard output.
-A, --show-all equivalent to -vET
��-vET�ȼ�
-b, --number-nonblank number nonblank output lines
����к�,������Էǿհ���
-e equivalent to -vE
��-vE�ȼ�
-E, --show-ends display $ at end of each line
�ļ�ĩβչʾ$
-n, --number number all output lines
����к�
-s, --squeeze-blank never more than one single blank line
�ϲ�����հ���,�������һ��
-t equivalent to -vT
-T, --show-tabs display TAB characters as ^I
�� TAB չʾΪ^I
-v, --show-nonprinting use ^ and M- notation, except for LFD and TAB
չʾһЩ�����������ַ�$ cat 1
hello world
hello linux�鿴�кź��������
$ cat -n 1
1 hello world
2
3
4 hello linux
5
$ cat -A 1
hello^Iworld^M$
^M$
^M$
hello^Ilinux^M$
^M$-A���� ��β�� $����, TAB ��^Iչʾ�� ^M��ʾwindiows�µĻس�����
catһ��ȫչʾ�ļ�,���ļ����^��ʱ�����������ͷ������ˡ�
�Ƽ�ʹ��more��less���鿴�ļ���
3. more����
more�ɷ�ҳ�鿴��
$ more filename����ʹ������:
�ո� space : ���·�ҳ
Enter : ? ? ? ? ? ���¹���һ��
/�ַ���?: ? ? ? ���²�ѯ�ַ���
:f ?:? ? ? ? ? ? ? ? ?��ʾ��ǰ�к�
q : ? ? ? ? ? ? ? ? �˳�
b : ? ? ? ? ? ? ? ? ���ط�ҳ���������ļ������á��Թܵ������á�
4. less����
lessҲ��һҳһҳ�IJ鿴,��more��ͬ�����ܹ����Ϸ�ҳ
$ less filename����ʹ������:
�ո� space : ? ? ? ? ?���·�һҳ
Enter : ? ? ? ? ? ? ? ? ? ? ����һ��
[PageDown] : ? ? ? ?����һҳ:
[PageUp] : ? ? ? ? ? ? ����һҳ
/�ַ���: ? ? ? ? ? ? ? ? ?���²�ѯ
?
�ַ���: ? ? ? ? ? ? ? ?���ϲ�ѯ
n : ? ? ? ? ? ? ? ? ? ? ? ? ? ����ǰһ����ѯ / �� ?
N : ? ? ? ? ? ? ? ? ? ? ? ? ?����ǰһ����ѯ / �� ?
q : ? ? ? ? ? ? ? ? ? ? ? ? ? �˳�
less�ą�����man����ą�������,����man������ǵ���less��ʾ˵���ĵ��ġ�
5.grep����
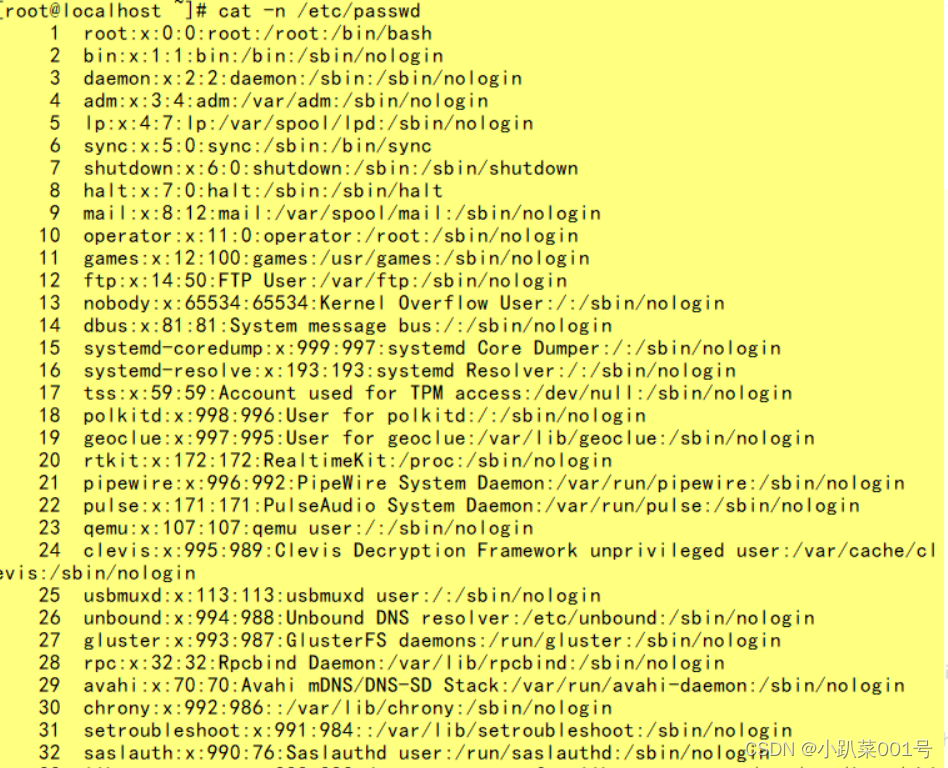
grep -n root /etc/passwd
cat -n /etc/passwd | awk -F: '{print $1}' ? ��ȡ/etc/passwd�ĵ�һ��������,����ʾ�к�
���:
? ? ?1 ?root
? ? ?2 ?bin
? ? ?3 ?daemon
? ? ?4 ?adm
? ? ?5 ?lp
? ? ?6 ?sync
? ? ?7 ?shutdown
? ? ?8 ?halt
? ? ?9 ?mail
? ? 10 ?news
? ? 11 ?uucp
? ? 12 ?operator
��ȡָ���кŵ���������,��ȡ/etc/passwd�ļ��е�10-15������
�Ȼ�ȡǰ15������,�ٴӽ�β��ȡ5�м�¼,��
head -n 15 /etc/passwd | tail -n 5
��: ��awk�����и����ñ��� ?NR��ʾ�к�awk 'NR>=10 && NR<=15' /etc/passwd?
����,���� ��1�����ڶ���
[root@localhost webapps]# awk 'NR>=1 && NR<=2 && match($0,"root"){print $0}' /etc/passwd
root:x:0:0:root:/root:/bin/bash
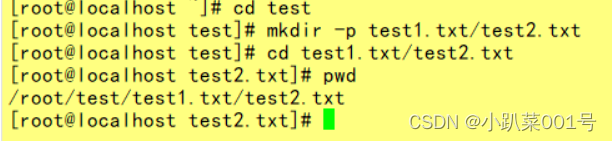
��.����Ŀ¼test
1.ʹ�����ַ�ʽ��testĿ¼�д����ı��ļ�text1.txt, text2.txt
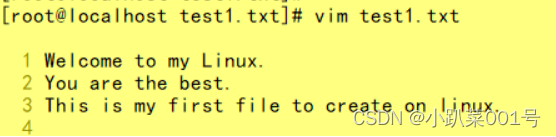
ʹ��Vim���ļ�text1.txt��д��
?Welcome to my Linux.
?You are the best.
?This is my first file to create on linux
�����к�,�����ı���my�滻��your,���ļ�����Ϊnew_test1.txt
?

��test�е��ļ�������test2Ŀ¼

��test2Ŀ¼�е�test1.txt������Ϊtest111.txt?

ɾ��testĿ¼��test1.txt? ɾ��testĿ¼?
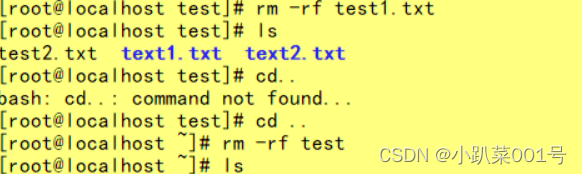
2.��echo "This is my first time to use pipe"�����������Ļ��,�ұ��浽pipe_data.txt��?

![]()
?��.cut����ʹ��
1.cut�����ѡ��
1)cut�����:
cut OPTION... [FILE]...
ѡ��:
-f : ͨ��ָ����һ���ֶν�����ȡ��cut����ʹ�á�TAB����ΪĬ�ϵ��ֶηָ�����
-d : ��TAB����Ĭ�ϵķָ���,ʹ�ô�ѡ����Ը���Ϊ�����ķָ�����
--complement : ��ѡ�������ų���ָ�����ֶΡ�
--output-delimiter : ����������ݵķָ�����
2)��ηָ�
cut��õ�ѡ����-d��-f����ϡ��������ϻ�����ض��ķָ������г����ֶ���ȡ���ݡ�
����Ĵ����ʹ�÷ָ���:��ӡ/etc/passwd�ļ���ÿһ�еĵ�һ���ֶΡ�
[root@localhost ~]# cut -d ':' -f 1 /etc/passwd
root
bin
daemon
adm
lp
sync
shutdown
��
����Ĵ����/etc/passwd�ļ���ȡ��һ�͵������ֶ�:
 ?
?
Ҫ��ʾ�ֶεķ�Χ,��ָ����-�ָ��Ŀ�ʼ�ֶκͽ����ֶ�,������ʾ:
 ?
?
3)�ų���ָ�����ֶ�
������Ĵ�����,��ӡ�����ֶ�,����/etc/passwd�ļ��еĵڶ����ֶ�:
[root@localhost ~]# grep '/bin/bash' /etc/passwd|cut -d ':' --complement -f 2
root:0:0:root:/root:/bin/bash
bob:1000:1001::/home/bob:/bin/bash
user01:1001:1002::/home/user01:/bin/bash
?4)���ָ��һ��������ݵķָ���
Ҫָ������ָ���,��ʹ�èCoutput-delimiterѡ�����ָ�����-dѡ��ָ��,Ĭ�����������ָ���������ָ�����ͬ��
�ȿ�һ��û��ʹ�èCoutput-delimiterѡ��,��ʲô���ӵ�:
[root@localhost ~]# cut -d ':' -f1,7 /etc/passwd|sort
adm:/sbin/nologin
avahi:/sbin/nologin
bin:/sbin/nologin
bob:/bin/bash
chrony:/sbin/nologin
daemon:/sbin/nologin
dbus:/sbin/nologin
ftp:/sbin/nologin
games:/sbin/nologin
grafana:/sbin/nologin
halt:/sbin/halt
lp:/sbin/nologin
mail:/sbin/nologin
nfsnobody:/sbin/nologin
nobody:/sbin/nologin
ntp:/sbin/nologin
operator:/sbin/nologin
��
����ʹ�èCoutput-delimiterѡ��,����ָ���ʹ�á� ���ո�ָ�,��һ����ʲô���ӵ�:
[root@localhost ~]# cut -d ':' -f1,7 --output-delimiter=' ' /etc/passwd|sort
adm /sbin/nologin
avahi /sbin/nologin
bin /sbin/nologin
bob /bin/bash
chrony /sbin/nologin
daemon /sbin/nologin
dbus /sbin/nologin
ftp /sbin/nologin
games /sbin/nologin
grafana /sbin/nologin
halt /sbin/halt
lp /sbin/nologin
mail /sbin/nologin
nfsnobody /sbin/nologin
nobody /sbin/nologin
ntp /sbin/nologin
operator /sbin/nologin
��.uniq����ʹ��
�÷�:uniq [OPTION]... [INPUT [OUTPUT]]
ѡ��:
-c, --count ? ? ? ?��ӡÿ�г��ֵĴ���
-d, --repeated ? ? ? ?ֻ��ӡ�ظ����ֵ���
-D ? ? ? ? ? ? ? ? ? ? ? ?��ӡ�����ظ���
--all-repeated[=METHOD]
? ? ? ? ? ? ? ? ? ? ? ? ���� -D,ʹ�ÿ��зָ�ÿ����,METHOD=none,prepend,separate
-f, --skip-fields=N ? ? ? ?���Ƚ�ǰ N ���ֶ�
--group[=METHOD]
? ? ? ? ? ? ? ? ? ? ? ? ʹ�ÿ��зָ�ÿ����,METHOD=separate,prepend,append,both
-i, --ignore-case ? ? ? ?���Դ�Сд
-s, --skip-chars=N ? ? ? ?���Ƚ�ǰ N ���ַ�
-u, --unique ? ? ? ? ? ? ? ?ֻ��ӡ����һ�ε���
-z, --zero-terminated ? ? ? ?�зָ����� NUL �����ǻ��з�
-w, --check-chars=N ? ? ? ?�Ƚϲ����� N ���ַ�
--help ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ?�����ĵ�
--version ? ? ? ? ? ? ? ? ? ? ? ? ? �汾��Ϣ
1.ʹ��ʾ��:
1)ʹ���±ߵ��ı��ļ�������:
[root@server dir]# cat uniq_test
Happy Birthday
Happy Birthday
Merry Christmas
Merry Christmas
Merry Christmas
Happy Valentine's Day
Happy Valentine's Day
Happy Birthday
2)��ִ��Ĭ������:
[root@server dir]# uniq uniq_test
Happy Birthday
Merry Christmas
Happy Valentine's Day
Happy Birthday
3)��ӡ����еĵ�1�к͵�4����һ����,Ϊʲô��?ԭ���� uniq �Ĺ����Ƕ��������ظ���ֻ��ʾһ��,�������һ�в�����������,����û��������,���Ǵ�ӡ�����ˡ���ô����ӡ����?������ sort �������ʹ��:
[root@server dir]# sort uniq_test | uniq
Happy Birthday
Happy Valentine's Day
Merry Christmas
4)ʹ�� -c ѡ�����ͳ��:
[root@server dir]# sort uniq_test | uniq -c
? ? ? 3 Happy Birthday
? ? ? 2 Happy Valentine's Day
? ? ? 3 Merry Christmas
5)--all-repeated ��ʹ��Ч��:
[root@server dir]# sort uniq_test | uniq --all-repeated
Happy Birthday
Happy Birthday
Happy Birthday
Happy Valentine's Day
Happy Valentine's Day
Merry Christmas
Merry Christmas
Merry Christmas
[root@server dir]# sort uniq_test | uniq --all-repeated=prepend
Happy Birthday
Happy Birthday
Happy Birthday
?
Happy Valentine's Day
Happy Valentine's Day
?
Merry Christmas
Merry Christmas
Merry Christmas
[root@server dir]# sort uniq_test | uniq --all-repeated=separate
Happy Birthday
Happy Birthday
Happy Birthday
?
Happy Valentine's Day
Happy Valentine's Day
?
Merry Christmas
Merry Christmas
Merry Christmas
6)�������Ѳ����ļ���Ϊ�±ߵ���ʽ:
[root@server dir]# cat uniq_test
Happy Birthday
Happy Birthday
Merry Christmas
Merry ChrIstmas
Merry Christmas
Happy Christmas
Happy Valentine's Day
Happy Valentine's Day
Happy Birthday
7)ʹ�� -f ѡ��,�ڹ����ظ���ʱ���Ƚ�ijЩ�ֶ�:
[root@server dir]# uniq -f 1 uniq_test
Happy Birthday
Merry Christmas
Merry ChrIstmas
Merry Christmas
Happy Valentine's Day
Happy Birthday
���Կ���,�ļ���� "Happy Christmas"?û�д�ӡ,��Ϊ�ڲ��Ƚϵ�һ���ֶε������,"Happy Christmas" �� "Merry Christmas" ����ͬ�ġ�
8)�±߿�һ�� -i ѡ��,�����Ǻ��Դ�Сд:
[root@server dir]# uniq -i uniq_test
Happy Birthday
Merry Christmas
Happy Christmas
Happy Valentine's Day
Happy Birthday
���Կ���,"Merry ChrIstmas" û�д�ӡ��
9)�±߿�һ�� -u ѡ��,ֻ��ӡ����һ�ε���:
[root@server dir]# uniq -u uniq_test
Merry Christmas
Merry ChrIstmas
Merry Christmas
Happy Christmas
Happy Birthday
10)��������ֹ����ַ��Ƚϵ�ѡ��,-s �DZȽ� N ���ַ��������,-w �DZȽ�ǰ N ���ַ�������:
# �Ƚϵ�5���ַ�֮�������
[root@server dir]# uniq -s5 uniq_test
Happy Birthday
Merry Christmas
Merry ChrIstmas
Merry Christmas
Happy Valentine's Day
Happy Birthday
# �Ƚ�ǰ5���ַ�
[root@server dir]# uniq -w5 uniq_test
Happy Birthday
Merry Christmas
Happy Christmas
��.sort����
sort��������Linux��dz�����,�����ļ���������,�����������������sort����ȿ��Դ��ض����ļ�,Ҳ���Դ�stdin�л�ȡ���롣
�:
sort(ѡ��)(����)
ѡ��:
-b:����ÿ��ǰ�濪ʼ���Ŀո��ַ�; -c:����ļ��Ƿ��Ѿ�����˳������; -d:����ʱ,����Ӣ����ĸ�����ּ��ո��ַ���,�����������ַ�; -f:����ʱ,��Сд��ĸ��Ϊ��д��ĸ; -i:����ʱ,����040��176֮���ASCII�ַ���,�����������ַ�; -m:����������ŵ��ļ����кϲ�; -M:��ǰ��3����ĸ�����·ݵ���д��������; -n:������ֵ�Ĵ�С����; -o<����ļ�>:�������Ľ�������ƶ����ļ�; -r:���෴��˳��������; -t<�ָ��ַ�>:ָ������ʱ���õ���λ�ָ��ַ�; +<��ʼ��λ>-<������λ>:��ָ������λ������,��Χ����ʼ��λ��������λ��ǰһ��λ��
����:�ļ�:ָ����������ļ��б���
ʵ��:sort���ļ�/�ı���ÿһ����Ϊһ����λ,��Ƚ�,�Ƚ�ԭ���Ǵ����ַ����,���ΰ�ASCLL��ֵ���бȽ�,������ǰ����������
[root@mail text]# cat sort.txt aaa:10:1.1 ccc:30:3.3 ddd:40:4.4 bbb:20:2.2 eee:50:5.5 eee:50:5.5 [root@mail text]# sort sort.txt aaa:10:1.1 bbb:20:2.2 ccc:30:3.3 ddd:40:4.4 eee:50:5.5 eee:50:5.5
������ͬ��ʹ��-uѡ�����uniq:
[root@mail text]# cat sort.txt aaa:10:1.1 ccc:30:3.3 ddd:40:4.4 bbb:20:2.2 eee:50:5.5 eee:50:5.5 [root@mail text]# sort -u sort.txt aaa:10:1.1 bbb:20:2.2 ccc:30:3.3 ddd:40:4.4 eee:50:5.5 ���� [root@mail text]# uniq sort.txt aaa:10:1.1 ccc:30:3.3 ddd:40:4.4 bbb:20:2.2 eee:50:5.5
sort��-n��-r��-k��-tѡ���ʹ��:
[root@mail text]# cat sort.txt AAA:BB:CC aaa:30:1.6 ccc:50:3.3 ddd:20:4.2 bbb:10:2.5 eee:40:5.4 eee:60:5.1 #��BB�а������ִ�С����˳������: [root@mail text]# sort -nk 2 -t: sort.txt AAA:BB:CC bbb:10:2.5 ddd:20:4.2 aaa:30:1.6 eee:40:5.4 ccc:50:3.3 eee:60:5.1 #��CC�����ִӴ�С˳������: [root@mail text]# sort -nrk 3 -t: sort.txt eee:40:5.4 eee:60:5.1 ddd:20:4.2 ccc:50:3.3 bbb:10:2.5 aaa:30:1.6 AAA:BB:CC # -n�ǰ������ִ�С����,-r�����෴˳��,-k��ָ����Ҫ���������λ,-tָ����λ�ָ���Ϊð��
-kѡ������ʽ:
FStart.CStart Modifie,FEnd.CEnd Modifier -------Start--------,-------End-------- FStart.CStart ѡ�� , FEnd.CEnd ѡ��
������ʽ���Ա����еĶ���,��Ϊ����,Start���ֺ�End���֡�Start����Ҳ�����������,���е�Modifier���־�������֮ǰ˵��������n��r��ѡ��֡������ص�˵˵Start���ֵ�FStart��C.Start��C.StartҲ�ǿ���ʡ�Ե�,ʡ�ԵĻ��ͱ�ʾ�ӱ���Ŀ�ͷ���ֿ�ʼ��FStart.CStart,����FStart���DZ�ʾʹ�õ���,��CStart���ʾ��FStart���дӵڼ����ַ���ʼ�㡰�������ַ�����ͬ��,��End������,������趨FEnd.CEnd,�����ʡ��.CEnd,���ʾ��β������β��,����������һ���ַ�������,����㽫CEnd�趨Ϊ0(��),Ҳ�DZ�ʾ��β������β����
�ӹ�˾Ӣ�����Ƶĵڶ�����ĸ��ʼ��������:
$ sort -t ' ' -k 1.2 facebook.txt baidu 100 5000 sohu 100 4500 google 110 5000 guge 50 3000
ʹ����-k 1.2,��ʾ�Ե�һ����ĵڶ����ַ���ʼ����������һ���ַ�Ϊֹ���ַ�������������ᷢ��baidu��Ϊ�ڶ�����ĸ��a�����а��ס�sohu�� google�ڶ����ַ�����o,��sohu��h��google��oǰ��,�������߷ֱ����ڵڶ��͵�����gugeֻ�����ӵ����ˡ�
ֻ��Թ�˾Ӣ�����Ƶĵڶ�����ĸ��������,�����ͬ�İ���Ա�����ʽ��н�������:
$ sort -t ' ' -k 1.2,1.2 -nrk 3,3 facebook.txt baidu 100 5000 google 110 5000 sohu 100 4500 guge 50 3000
����ֻ�Եڶ�����ĸ��������,��������ʹ����-k 1.2,1.2�ı�ʾ��ʽ,��ʾ���ǡ�ֻ���Եڶ�����ĸ��������(������ʡ���ʹ��-k 1.2��ô����?��,��Ȼ����,��Ϊ��ʡ����End����,�����ζ���㽫�Դӵڶ�����ĸ�������һ���ַ�Ϊֹ���ַ�����������)������Ա�����ʽ����� ��,����Ҳʹ����-k 3,3,������ȷ�ı���,��ʾ���ǡ�ֻ���Ա����������,��Ϊ�����ʡ���˺����3,�ͱ�������ǡ��Ե�3����ʼ�����һ����λ�õ����ݽ������� �ˡ�
��.
1.��hello 123 world 456�е������滻�ɿ��ַ�

2.��26��Сд��ĸ�ĺ�13����ĸ�滻�ɴ�д��ĸ
 ?
?
3.��hello 123 world 456����ĸ�Ϳո��滻��,ֻ��������
 ?
?
?