���̼�ͨ�Ž���
���̼�ͨ�ŵĸ���
���̼�ͨ�ż��IPC(Interprocess communication),���̼�ͨ�ž����ڲ�ͬ����֮�䴫������Ϣ��
���̼�ͨ�ŵ�Ŀ��
- ���ݴ���: һ��������Ҫ���������ݷ�����һ�����̡�
- ��Դ����: �������֮�乲��ͬ������Դ��
- ֪ͨ�¼�: һ��������Ҫ����һ����һ����̷�����Ϣ,֪ͨ��(����)������ij���¼�,���������ֹʱ��Ҫ֪ͨ�丸���̡�
- ���̿���: ��Щ����ϣ����ȫ������һ�����̵�ִ��(��Debug����),��ʱ���ƽ���ϣ���ܹ�������һ�����̵�����������쳣,���ܹ���ʱ֪������״̬�ı䡣
���̼�ͨ�ŵı���
������ʵ��Ӧ�ó�����,����֮����ܻ�����ض���Эͬ�����ij���,����һ������Ҫ���Լ������ݽ�����һ������,������д���,�������ν�Ľ��̼�ͨ�š���������֪�����ڸ������н���֮����ж�����,һ�����̿�������һ�����̵���Դ,���Ҫ��������,�ɱ�һ���ܸ�, ��˸�������֮��Ҫʵ��ͨ���Ƿdz����ѵġ�
��������֮������ʵ��ͨ��,һ��Ҫ������������Դ,��Щ���̾Ϳ���ͨ���������������Դд����Ƕ�ȡ����,����ʵ�ֽ���֮���ͨ��,�����������Դʵ���Ͼ�������ϵͳ�ṩ��һ���ڴ�����(�������ļ���ʽ�ṩ,Ҳ�����Զ��еķ�ʽ,Ҳ�����ṩ�ľ���ԭʼ���ڴ��)��
���,���̼�ͨ�ŵı��ʾ���,�ò�ͬ�Ľ��̿���ͬһ����Դ�� ���������Դ�����ɲ���ϵͳ�еIJ�ͬģ���ṩ,��˳����˲�ͬ�Ľ��̼�ͨ�ŷ�ʽ��
���̼�ͨ�ŷ�չ
- �ܵ�
- System V���̼�ͨ��
- POSIX���̼�ͨ��
���̼�ͨ�ŵķ���
- �ܵ�
�����ܵ� �����ܵ�
- System V IPC
System V ��Ϣ����
System V �����ڴ�
System V �ź���
- POSIX IPC
��Ϣ����
�����ڴ�
�ź���
������
��������
���
�ܵ�
ʲô�ǹܵ�
�ܵ���Unix������ϵĽ��̼�ͨ�ŵ���ʽ,���ǰѴ�һ���������ӵ���һ�����̵���������Ϊһ�����ܵ�����
����,ͳ�����ǵ�ǰʹ���Ʒ������ϵĵ�¼�û�������
who�������ڲ鿴��ǰ�Ʒ������ĵ�¼�û�(һ����ʾһ���û�),wc -l����ͳ�Ƶ�ǰ��������
����,who�����wc�������������,����������������ͱ������������,who����ͨ������������ݴ��ܵ�������,wc������ͨ��������ӡ��ܵ������ж�ȡ����,���˱���������ݵĴ���.
�����ܵ�
�����ܵ����ڽ��̼�ͨ��,�ҽ����ڱ��ظ��ӽ���֮���ͨ�š�
���������ܵ�����pipe
pipe�������ڴ��������ܵ�
����ԭ��:
#include <unistd> int pipe(int pipefd[2])����:
fd:�ļ�����������,����һ������Ͳ���,fd[0]��ʾ����,fd[1]��ʾд������ֵ: �����ܵ��ɹ�����0,ʧ�ܷ���-1
����pipe������,OS����fd_array�����з��������ļ����������ܵ�,һ���Ƕ�,һ����д,
�����ܵ�ԭ��
�����̵���pipe���������ܵ���
1.�����̴����ܵ�
�����ܵ��Ĵ���,��Ҫͨ���������ϵͳ����:
int pipe(int fd[2])
�����ʾ����һ�������ܵ�,������������������,һ���ǹܵ��Ķ�ȡ�������� fd[0],��һ���ǹܵ���д��������� fd[1]��ע��,��������ܵ���������ļ�,ֻ�������ڴ�,�������ļ�ϵͳ�С�
�����ø������Զ���д�ķ�ʽ��ͬһ���ļ�,��������Ϊ�Զ���ʽ��һ��,��д��ʽ��һ�Ρ��൱�ڸ����̴�һ���ļ�,��������ļ�������ֻ��һ��,�����Զ���ʽ����д��ʽ��,�����Ļ��Զ���ʽ���ļ�����һ���ļ�������,��д��ʽ���ļ�����һ���ļ�������,�������ļ�������ָ��ͬһ���ļ����������൱�����˶�������д��,������̿��Գ�֮Ϊ�����ܵ��Ĺ��̡�
ʲô���������ܵ�һ�仰����:�ֱ��Զ���ʽ����д��ʽ������ͬһ���ļ���
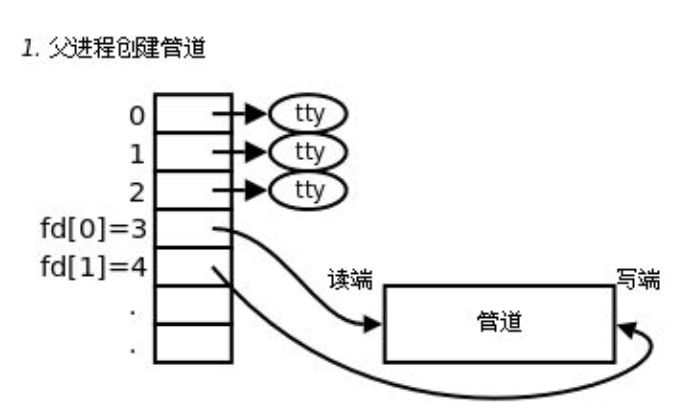
2.������fork���ӽ���
��ʵ,��ν�Ĺܵ�,�����ں������һ���������ӹܵ���һ��д�������,ʵ�����ǻ������ں��е�,��һ�˶�ȡ,Ҳ���Ǵ��ں��ж�ȡ������ݡ�����,�ܵ��������������ʽ�����Ҵ�С���ޡ�
������,����ܻ���������,������������������һ����������,��û�����̼�ͨ�ŵ�����,��ô������ʹ�ùܵ��ǿ���������̵���?
���ǿ���ʹ�� fork �����ӽ���,�������ӽ��̻Ḵ�Ƹ����̵��ļ�������,�������������������̸��������� fd[0] �� fd[1]��,�������̾Ϳ���ͨ�����Ե� fd д��Ͷ�ȡͬһ���ܵ��ļ�ʵ�ֿ����ͨ���ˡ�
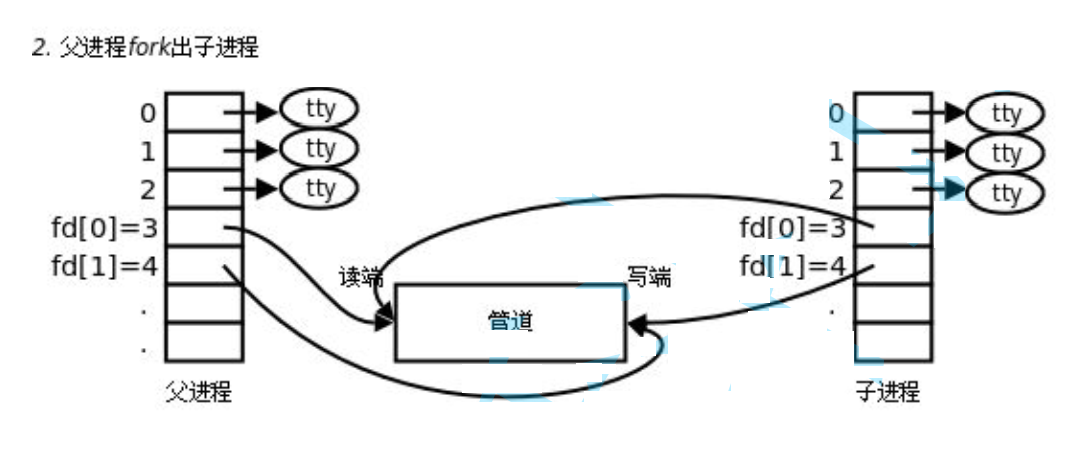
3.���ӽ��̸��Թرղ���Ҫ���ļ�������
���ǹܵ�ֻ�ܽ��е�������ͨ�š�Ҳ����ζ��Ҫô������д�ӽ��̶�,Ҫô�ӽ���ȥд������ȥ������֮һ���ܵ�ֻ�ܽ��е�������ͨ��,�����˫��ͨ�ſ��Խ�������ܵ���
�ܵ�ֻ�ܽ��е���ͨ��,���Ծ�Ҫ������˭����˭д��
- ������ø����̶�,�رո����̵�д��,��������ӽ��̶�,�ر��ӽ��̵�д�ˡ�
- ������ø�����д,�رո����̵Ķ���,��������ӽ���д,�ر��ӽ��̵Ķ��ˡ�
Ҳ����˵�ø��ӽ��̸��Թر����Dz���Ҫ���ļ����������ﵽ���������ŵ��Ĺ��ܡ�
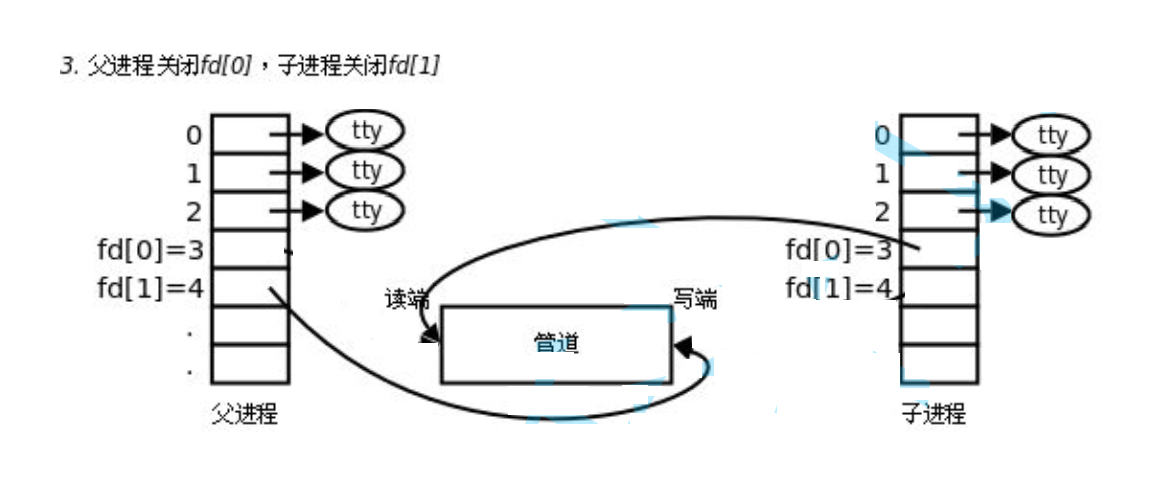
Ϊʲô���ӽ��̳���Ҫ�ص�һ��,����Ҫ����?
- 1.���������ֻ�Զ���ʽ��,�ӽ��̼̳���ȥ���ļ���������Ӧ���ļ�Ҳֻ�Ƕ���ʽ,����������ͨ�š����ֻ��д��ʽ��,fork֮���ӽ��̱����ļ��ǿ�д��,���ӽ��̶�ֻ��д,��������ͨ�š����Բ���rw,�ӽ����õ����ļ���ʽ�ض�������һ��,��ͨ�š�
- 2.���Ŀ��Ƹ��ӽ�����ɶ�дͨ��,�����Ǹ����̶������ӽ���д,��ȫȡ������ij���,���Ѷ�д�˶���,����Ҫ���ĸ��Լ�������
��������������������������������
ע��:
- �ܵ�ֻ�ܹ����е���ͨ��,��˵������̴������ӽ��̺�,��Ҫȷ�ϸ��ӽ���˭��˭д,Ȼ��ر���Ӧ�Ķ�д�ˡ�
- �ӹܵ�д��д������ݻᱻ�ں˻���,ֱ���ӹܵ��Ķ��˱���ȡ��
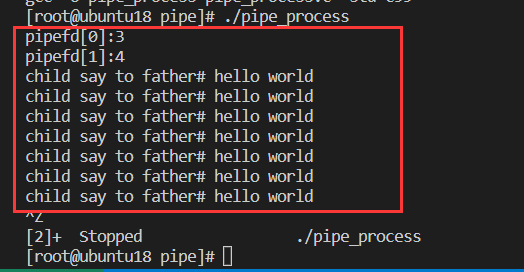
����:
�����´��뵱��,�ӽ����������ܵ�����д������,�����̴������ܵ����н����ݶ�����
#include<stdio.h>
#include<unistd.h>
#include<stdlib.h>
#include<string.h>
int main()
{
int pipefd[2]={0};
if(pipe(pipefd)!=0)
{
//��ʧ��
perror("pipe error!");
return 1;
}
//�ɹ�
printf("pipefd[0]:%d\n",pipefd[0]);//3
printf("pipefd[1]:%d\n",pipefd[1]);//4
if(fork()==0)
{
//�ӽ���--д��
close(pipefd[0]);
const char *msg="hello world";
while(1)
{
write(pipefd[1],msg,strlen(msg));
sleep(1);
}
exit(0);
}
//������--��ȡ
close(pipefd[1]);
while(1)
{
//����û���ø�����sleep,Ҳ����˵д����,���Ŀ�
char buffer[64]={0};
//���read�ķ���ֵ��0,��ζ���ӽ��̹ر��ļ���������
ssize_t s=read(pipefd[0],buffer,sizeof(buffer));
if(s==0)
{
printf("child quit...\n");
break;
}
else if(s>0)
{
buffer[s]=0;
printf("child say to father# %s\n",buffer);
}
else
{
printf("read error...\n");
break;
}
}
return 0;
}
//pipefd[2]:��һ������Ͳ���,������ͨ�����������ȡ��������fd
// int pipe(int pipefd[2]);
�ܵ���д����
pipe2������pipe��������,Ҳ�����ڴ��������ܵ�,�亯��ԭ������:
int pipe2(int pipefd[2], int flags);
pipe2�����ĵڶ���������������ѡ�
1����û�����ݿɶ�ʱ:
- O_NONBLOCK disable:read��������,��������ִͣ��,һֱ�ȵ���������Ϊֹ��
- O_NONBLOCK enable:read���÷���-1,errnoֵΪEAGAIN��
2�����ܵ�����ʱ��:
- O_NONBLOCK disable:write��������,ֱ���н��̶������ݡ�
- O_NONBLOCK enable:write���÷���-1,errnoֵΪEAGAIN��
3��������йܵ�д�˶�Ӧ���ļ����������ر�,��read����0��
4��������йܵ����˶�Ӧ���ļ����������ر�,��write����������ź�SIGPIPE,�������ܵ���write�����˳���
5����Ҫд���������������PIPE_BUFʱ,Linux����֤д���ԭ���ԡ�
6����Ҫд�������������PIPE_BUFʱ,Linux�����ٱ�֤д���ԭ���ԡ�

�ܵ����ص�
1���ܵ��ڲ��Դ�ͬ���뻥����ơ�
���ǽ�һ��ֻ����һ������ʹ�õ���Դ,��Ϊ�ٽ���Դ���ܵ���ͬһʱ��ֻ����һ�����̶������д����Ƕ�ȡ����,��˹ܵ�Ҳ����һ���ٽ���Դ��
�ٽ���Դ����Ҫ��������,�������Dz��Թܵ������ٽ���Դ�����κα�������,��ô�Ϳ��ܳ���ͬһʱ���ж�����̶�ͬһ�ܵ����в��������,��������ͬʱ��д�������д�Լ���ȡ�������ݲ�һ�µ����⡣
Ϊ�˱�����Щ����,�ں˻�Թܵ���������ͬ���뻥��:
- ͬ��: �������������ϵĽ��������й�����Эͬ����,��Ԥ�����Ⱥ�������С�����,A���������������B������������ݡ�
- ����: һ��������Դͬһʱ��ֻ�ܱ�һ������ʹ��,������̲���ͬʱʹ�ù�����Դ��
Ҳ����˵,�������Ψһ�Ժ�������,�����Ⲣ���������������˳��.
2���ܵ���������������̡�
�ܵ���������ͨ���ļ�����ͨ�ŵ�,Ҳ����˵�ܵ��������ļ�ϵͳ,��ô�����д��ļ��Ľ��̶��˳���,���ļ�Ҳ�ͻᱻ�ͷŵ�,����˵�ܵ���������������̡�
3���ܵ��ṩ������ʽ����
���ڽ���Aд��ܵ����е�����,����Bÿ�δӹܵ���ȡ�����ݵĶ����������,���ֱ���Ϊ��ʽ����,��֮���Ӧ�������ݱ�����:
- ��ʽ����: ����û����ȷ�ķָ�,����һ���ı��ĶΡ�
- ���ݱ�����: ��������ȷ�ķָ�,�����ݰ����Ķ��á�
4���ܵ��ǰ�˫��ͨ�ŵġ�
������ͨ����,��������·�ϵĴ��ͷ�ʽ���Է�Ϊ��������:
- ����ͨ��(Simplex Communication):����ģʽ�����ݴ����ǵ���ġ�ͨ��˫����,һ���̶�Ϊ���Ͷ�,��һ���̶�Ϊ���նˡ�
- ��˫��ͨ��(Half Duplex):��˫�����ݴ���ָ���ݿ�����һ���ź���������������ϴ���,���Dz���ͬʱ���䡣
- ȫ˫��ͨ��(Full Duplex):ȫ˫��ͨ����������������������ͬʱ����,���������൱����������ͨ�ŷ�ʽ�Ľ�ϡ�ȫ˫������ͬʱ(˲ʱ)�����źŵ�˫���䡣
�ܵ��ǰ�˫����,����ֻ����һ����������,��Ҫ˫��ͨ��ʱ,��Ҫ�����������ܵ���
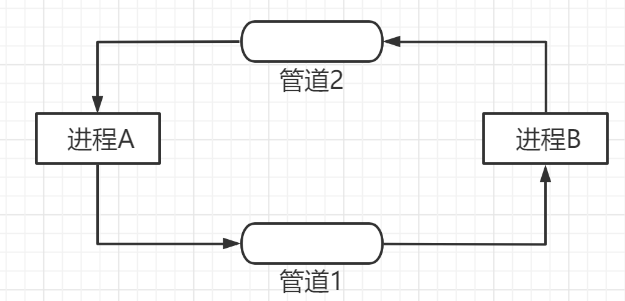
�ܵ��������������
��ʹ�ùܵ�ʱ,���ܳ������������������:
- д�˽��̲�д,���˽���һֱ��,��ô��ʱ����Ϊ�ܵ�����û�����ݿɶ�,��Ӧ�Ķ��˽��̻ᱻ����(����),ֱ���ܵ����������ݺ�,���˽��̲Żᱻ���ѡ�
- ���˽��̲���,д�˽���һֱд,��ô���ܵ���д����,��Ӧ��д�˽��̻ᱻ����(����),ֱ���ܵ����е����ݱ����˽��̶�ȡ��,д�˽��̲Żᱻ���ѡ�
- д�˽��̽�����д���д�˹ر�,��ô���˽��̽��ܵ����е����ݶ����,�ͻ����ִ�иý���֮��Ĵ�����,�����ᱻ����(Ҳ����˵����һֱ��,д�˲�д���ҹر�,��ȡ��0,�����ļ�������)
- ���˽��̽����˹ر�,��д�˽��̻���һֱ��ܵ�д������,��ô����ϵͳ�Ὣд�˽���ɱ��(д�˱�OS����13���ź�SIGPIPEɱ��)��
����ǰ������������ܹ��ܺõ�˵��,�ܵ����Դ�ͬ���뻥����Ƶ�,���˽��̺�д�˽�������һ������Э���Ĺ��̵�,����˵���ܵ�û�������˶��˻��ڶ�ȡ,�����ܵ��Ѿ�����д�˻���д�롣���˽��̶�ȡ���ݵ������ǹܵ�����������,д�˽���д�����ݵ������ǹܵ����л��пռ�,��������������,����Ӧ�Ľ��̾ͻᱻ����,ֱ�����������Żᱻ�ٴλ��ѡ�
���������Ҳ�ܺ�����,���˽����Ѿ����ܵ����е��������ݶ���ȡ������,���Ҵ˺�Ҳ������д���ٽ���д����,��ô��ʱ���˽���Ҳ�Ϳ���ִ�иý��̵���������,�����ᱻ����
�������������˵:��Ȼ�ܵ����е������Ѿ�û�н��̻��ȡ��,��ôд�˽��̵�д�뽫û������,��˲���ϵͳֱ�ӽ�д�˽���ɱ����(�����ӽ�����д��)����ʱ�ӽ��̴��붼��û����ͱ���ֹ��,�����쳣�˳�,��ô�ӽ��̱�Ȼ�յ���ij���źš�
���ǿ���ͨ�����´��뿴���������,�ӽ����˳�ʱ�������յ���ʲô�źš�
#include <stdio.h>
#include <unistd.h>
#include <string.h>
#include <stdlib.h>
#include <sys/types.h>
#include <sys/wait.h>
int main()
{
int fd[2] = { 0 };
if (pipe(fd) < 0){ //ʹ��pipe���������ܵ�
perror("pipe");
return 1;
}
pid_t id = fork(); //ʹ��fork�����ӽ���
if (id == 0){
//child
close(fd[0]); //�ӽ��̹رն���
//�ӽ�����ܵ�д������
const char* msg = "hello father, I am child...";
int count = 10;
while (count--){
write(fd[1], msg, strlen(msg));
sleep(1);
}
close(fd[1]); //�ӽ���д�����,�ر��ļ�
exit(0);
}
//father
close(fd[1]); //�����̹ر�д��
close(fd[0]); //������ֱ�ӹرն���(�����ӽ��̱�����ϵͳɱ��)
int status = 0;
waitpid(id, &status, 0);
printf("child get signal:%d\n", status & 0x7F); //��ӡ�ӽ����յ����ź�
return 0;
}
���н����ʾ,�ӽ����˳�ʱ�յ�����13���źš�

ͨ��kill -l������Բ鿴13��Ӧ�ľ����źš�
$ kill -l
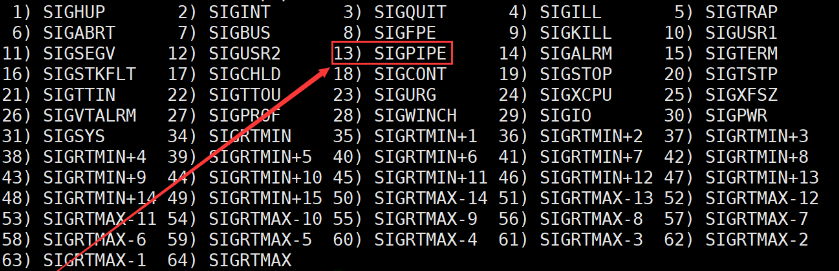
�ɴ˿�֪,�����������ʱ,����ϵͳ���ӽ��̷��͵���SIGPIPE�źŽ��ӽ�����ֹ�ġ�
�ܵ��Ĵ�С
�ܵ�������������,����ܵ�����,��ôд�˽�������ʧ��,��ô�ܵ�����������Ƕ�����?��ô�鿴��?
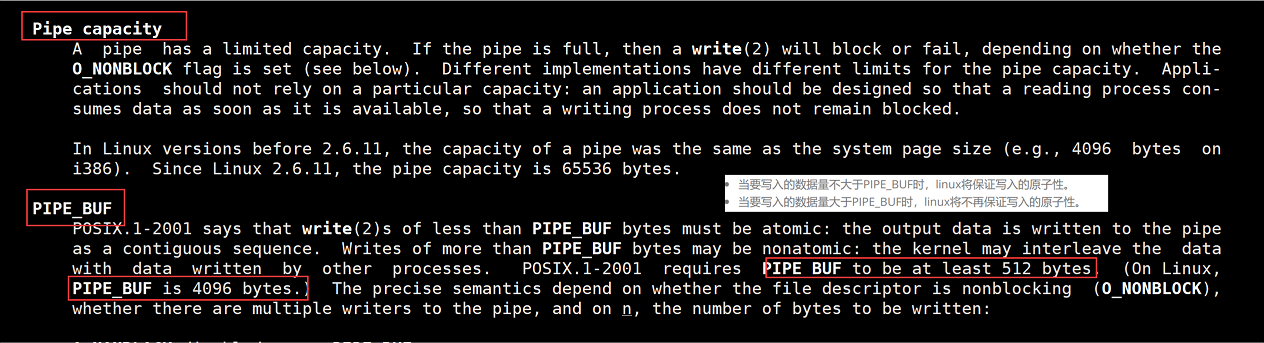
����һ:ʹ��man�ֲ�
����man�ֲ�,��2.6.11֮ǰ��Linux�汾��,�ܵ������������ϵͳҳ���С��ͬ,��Linux 2.6.11����,�ܵ������������65536�ֽڡ�
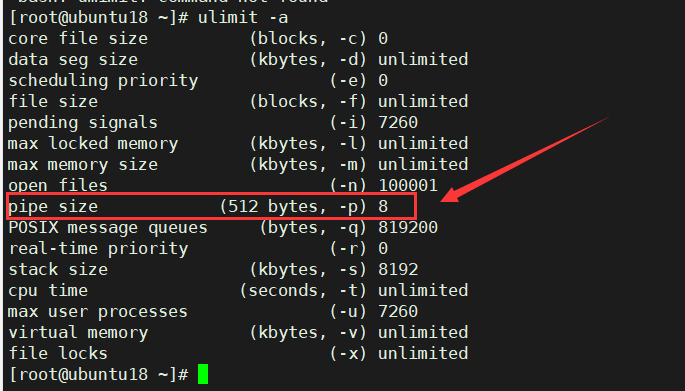
������:ʹ��ulimit����
���ǻ�����ʹ��ulimit -a����,�鿴��ǰ��Դ���Ƶ��趨��
�ܵ������������ 512 �� 8=4096 �ֽڡ�
������:�����
ǰ��˵��,���Ƕ��˽���һֱ����ȡ�ܵ����е�����,д�˽���һֱ��ܵ�д������,���ܵ���д����,д�˽��̾ͻᱻ���𡣾ݴ�,���ǿ���д�����´��������Թܵ������������
#include <unistd.h>
#include <stdio.h>
#include <stdlib.h>
#include <sys/wait.h>
int main()
{
int fd[2] = { 0 };
if (pipe(fd) < 0){ //ʹ��pipe���������ܵ�
perror("pipe");
return 1;
}
pid_t id = fork(); //ʹ��fork�����ӽ���
if (id == 0){
//child
close(fd[0]); //�ӽ��̹رն���
char c = 'a';
int count = 0;
//�ӽ���һֱ����д��,һ��д��һ���ֽ�
while (1){
write(fd[1], &c, 1);
count++;
printf("%d\n", count); //��ӡ��ǰд����ֽ���
}
close(fd[1]);
exit(0);
}
//father
close(fd[1]); //�����̹ر�д��
//�����̲����ж�ȡ
waitpid(id, NULL, 0);
close(fd[0]);
return 0;
}
���Կ���,�ڶ��˽��̲����ж�ȡ�������,д�˽������д65536�ֽڵ����ݾͱ�����ϵͳ������,Ҳ����˵,�ҵ�ǰLinux�汾�йܵ������������65536�ֽڡ�
�����ܵ�
�����ܵ���ԭ��
�����ܵ�ֻ�����ھ��й�ͬ���ȵĽ���(������Ե��ϵ�Ľ���)֮���ͨ��,ͨ��,һ���ܵ���һ�����̴���,Ȼ��ý��̵���fork,�˺��ӽ���֮��Ϳ�Ӧ�øùܵ���
���Ҫʵ������������ؽ���֮���ͨ��,����ʹ�������ܵ��������������ܵ�����һ���������͵��ļ�,��������ͨ��·��+�ļ�����ͬһ���ܵ��ļ�(�˹ܵ��ļ�����Ψһ��,��Ϊ·�������ļ�������Ψһ��ʶһ���ļ�),��ʱ����������Ҳ�Ϳ�����ͬһ����Դ,�����Ϳ��Խ���ͨ���ˡ�
ע��
1.�����ܵ�Ҳ�ǹܵ�,��Ҳ���عܵ��������ֽ���,ͬ������,ֻ�ܵ���ͨ��,������������̵ȵ���Щ�ص�������,Ψһ�������ܵ���ͬ�����������ò�ͬ�Ľ���(������ؽ���)ͨ�š�
2.��ͨ�ļ���Ҫ������ˢ�µ�������,�־û��洢�����ǹܵ��ļ�����Ҫ������ˢ�µ����̡�
����һ�������ܵ�
1.�����ܵ����Դ��������ϴ���
�����з�����ʹ�������������:
mkfifo fifo

���Կ���,�����������ļ���������p,�������ļ��������ܵ��ļ���
2.�����ܵ�Ҳ���Դӳ����ﴴ��
��غ�����:
#include <sys/types.h>
#include <sys/stat.h>
int mkfifo(const char *filename, mode_t mode);
- ��һ��������ʾҪ�����������ܵ��ļ�����·���ķ�ʽ����,�������ܵ��ļ�������ָ��·����,���ļ����ķ�ʽ����,�������ܵ��ļ�Ĭ�ϴ����ڵ�ǰ·���¡�
- �ڶ���������ʾ��Ҫ�����������ܵ�����Ȩ�ޡ�
����ֵ�ɹ�����0,ʧ�ܷ���-1��
��������������������������������
ע��ڶ���������Ȩ������:
����,��mode����Ϊ0666,����˵�����ܵ��ļ�����������Ȩ������:
prw-rw-rw-
��ʵ���ϴ��������ļ���Ȩ��ֵ�����ܵ�umask(�ļ�Ĭ������)��Ӱ��,ʵ�ʴ��������ļ���Ȩ��Ϊ:mode&(~umask)��
umask��Ĭ��ֵһ��Ϊ0002,����������modeֵΪ0666ʱʵ�ʴ��������ļ���Ȩ��Ϊ0664����
prw-rw-r-
���봴�����������ܵ��ļ���Ȩ��ֵ����umask��Ӱ��,����Ҫ�ڴ����ļ�ǰʹ��umask�������ļ�Ĭ����������Ϊ0��
umask(0); //���ļ�Ĭ����������Ϊ0
��������������������������������
�ӳ����ﴴ�������ܵ�ʾ��:
//�ڵ�ǰ·����,������һ����Ϊmyfifo�������ܵ���
1 #include<stdio.h>
2 #include<sys/stat.h>
3 #include<sys/types.h>
4
5 #define My_FIFO "./fifo"
6
7 int main()
8 {
9 umask(0); //���ļ�Ĭ����������Ϊ0
10 if(mkfifo(My_FIFO,0666)<0)
11 {
12 perror("mkfifo");
13 return 1;
14 }
15 return 0;
16 }
���д����,�����ܵ�fifo���ڵ�ǰ·���±������ˡ�
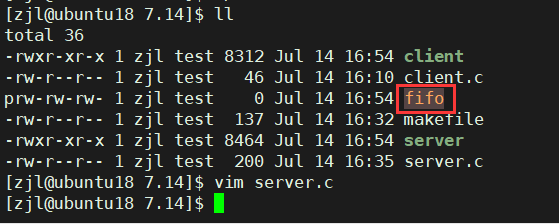
�����ܵ��Ĵ���
1�������ǰ������Ϊ������FIFOʱ��
- O_NONBLOCK disable:����ֱ������Ӧ����Ϊд����FIFO��
- O_NONBLOCK enable:���̷��سɹ���
2�������ǰ������Ϊд����FIFOʱ��
- O_NONBLOCK disable:����ֱ������Ӧ����Ϊ������FIFO��
- O_NONBLOCK enable:���̷���ʧ��,������ΪENXIO��
�������ܵ�ʵ��serve&clientͨ��
ʵ�ַ����(server)�Ϳͻ���(client)֮���ͨ��֮ǰ,������Ҫ���÷������������,������Ҫ�÷�������к�һ�������ܵ��ļ�,Ȼ�����Զ��ķ�ʽ�������ܵ��ļ�,֮�����˾Ϳ��ԴӸ������ܵ����ж�ȡ�ͻ��˷�����ͨ����Ϣ�ˡ�
����˵Ĵ�������:
server.c
#include "comm.h"
int main()
{
umask(0); //���ļ�Ĭ����������Ϊ0
if (mkfifo(FILE_NAME, 0666) < 0){ //ʹ��mkfifo���������ܵ��ļ�
perror("mkfifo");
return 1;
}
int fd = open(FILE_NAME, O_RDONLY); //�Զ��ķ�ʽ�������ܵ��ļ�
if (fd < 0){
perror("open");
return 2;
}
char msg[128];
while (1){
msg[0] = '\0'; //ÿ�ζ�֮ǰ��msg���
//�������ܵ����ж�ȡ��Ϣ
ssize_t s = read(fd, msg, sizeof(msg)-1);
if (s > 0){
msg[s] = '\0'; //�ֶ�����'\0',�������
printf("client# %s\n", msg); //����ͻ��˷�������Ϣ
}
else if (s == 0){
printf("client quit!\n");
break;
}
else{
printf("read error!\n");
break;
}
}
close(fd); //ͨ�����,�ر������ܵ��ļ�
return 0;
}
�����ڿͻ�����˵,��Ϊ��������������������ܵ��ļ����Ѿ���������,���Կͻ���ֻ����д�ķ�ʽ�������ܵ��ļ�,֮��ͻ��˾Ϳ��Խ�ͨ����Ϣд�뵽�����ܵ��ļ�����,����ʵ�ֺͷ���˵�ͨ�š�
�ͻ��˵Ĵ�������:
//client.c
#include "comm.h"
int main()
{
int fd = open(FILE_NAME, O_WRONLY); //��д�ķ�ʽ�������ܵ��ļ�
if (fd < 0){
perror("open");
return 1;
}
char msg[128];
while (1){
msg[0] = '\0'; //ÿ�ζ�֮ǰ��msg���
printf("Please Enter# "); //��ʾ�ͻ�������
fflush(stdout);
//�ӿͻ��˵ı���������ȡ��Ϣ
ssize_t s = read(0, msg, sizeof(msg)-1);
if (s > 0){
msg[s - 1] = '\0';
//����Ϣд�������ܵ�
write(fd, msg, strlen(msg));
}
}
close(fd); //ͨ�����,�ر������ܵ��ļ�
return 0;
}
��������ÿͻ��˺ͷ����ʹ��ͬһ�������ܵ��ļ�,�������ǿ����ÿͻ��˺ͷ���˰���ͬһ��ͷ�ļ�,��ͷ�ļ������ṩ������õ������ܵ��ļ����ļ���,�����ͻ��˺ͷ���˾Ϳ���ͨ������ļ���,��ͬһ�������ܵ��ļ�,��������ͨ���ˡ�
����ͷ�ļ��Ĵ�������:
comm.h
#pragma once
#include <stdio.h>
#include <unistd.h>
#include <sys/types.h>
#include <sys/stat.h>
#include <string.h>
#include <fcntl.h>
#define FILE_NAME "myfifo" //�ÿͻ��˺ͷ����ʹ��ͬһ�������ܵ�
�����д��Ϻ�,�Ƚ�����˽�����������,֮�����Ǿ��ܿ�������Ѿ��������������ܵ��ļ���
�����ٽ��ͻ���Ҳ��������,��ʱ���Ǵӿͻ���д�����Ϣ���ͻ���д�뵽�����ܵ�����,������ٴ������ܵ����н���Ϣ��ȡ������ӡ�ڷ���˵���ʾ����,��ʱ����������֮�����ܹ�ͨ�ŵġ�
����˺Ϳͻ���֮����˳���ϵ:
���ͻ����˳���,����˽��ܵ����е����ݶ�������Ҳ������������,��ô��ʱ�����Ҳ�ͻ�ȥִ����������������(�ڵ�ǰ��������ֱ���˳���)��
��������˳���,�ͻ���д��ܵ������ݾͲ��ᱻ��ȡ��,Ҳ��û��������,��ô���ͻ�����һ������ܵ�д������ʱ,�ͻ��յ�����ϵͳ������13���ź�(SIGPIPE),��ʱ�ͻ��˾ͱ�����ϵͳǿ��ɱ���ˡ�
ͨ�������ڴ浱�н��е�
��������ֻ�ÿͻ�����ܵ�д������,������˲��ӹܵ���ȡ����,��ô����ܵ��ļ��Ĵ�С��ᷢ���仯��?
//server.c
#include "comm.h"
int main()
{
umask(0); //���ļ�Ĭ����������Ϊ0
if (mkfifo(FILE_NAME, 0666) < 0){ //ʹ��mkfifo���������ܵ��ļ�
perror("mkfifo");
return 1;
}
int fd = open(FILE_NAME, O_RDONLY); //�Զ��ķ�ʽ�������ܵ��ļ�
if (fd < 0){
perror("open");
return 2;
}
while (1){
//����˲���ȡ�ܵ���Ϣ
}
close(fd); //ͨ�����,�ر������ܵ��ļ�
return 0;
}
��ʱ,�ֱ����пͻ��˺ͷ����,�ڿͻ���д������,����˲�����ȡ�ܵ����е�����,��ʱʹ��ll����������ܵ��ļ��Ĵ�С����Ϊ0,Ҳ���ǹܵ����е����ݲ�û�б�ˢ�µ�����,Ҳ��˵����˫������֮���ͨ�����������ڴ浱�н��е�,�������ܵ�ͨ����һ���ġ�
�����ܵ��������ܵ�������
- �����ܵ���pipe������������
- �����ܵ���mkfifo��������,��open������
- FIFO(�����ܵ�)��pipe(�����ܵ�)֮��Ψһ�������������Ǵ�����ķ�ʽ��ͬ,һ����Щ�������֮��,���Ǿ�����ͬ�����塣
��չ:�������е��еĹܵ�(��|��)�����������ܵ����������ܵ���?
���������ܵ�ֻ����������Ե��ϵ�Ľ���֮���ͨ��,�������ܵ�������������������صĽ���֮���ͨ��,������ǿ����ȿ��������е����ùܵ�(��|��)���������ĸ�������֮���Ƿ������Ե��ϵ��
�������ͨ���ܵ�(��|��)��������������,ͨ��ps����鿴���������̾Ϳ��Է���,���������̵�PPID����ͬ��,Ҳ����˵��������ͬһ�������̴������ӽ��̡������ǵĸ�����ʵ���Ͼ��������н�����,����Ϊbash��
Ҳ����˵,�ɹܵ�(��|��)���������ĸ�������������Ե��ϵ��,����֮�以Ϊ�ֵܽ��̡�
system V���̼�ͨ��
�ܵ�ͨ�ű����ǻ����ļ���,Ҳ����˵����ϵͳ��û��Ϊ�����������ƹ���,��system V IPC�Dz���ϵͳ�ص���Ƶ�һ��ͨ�ŷ�ʽ�����Dz�����ô��,���ǵı��ʶ���һ����,�������뾡�취�ò�ͬ�Ľ��̿���ͬһ���ɲ���ϵͳ�ṩ����Դ��
system V IPC�ṩ��ͨ�ŷ�ʽ����������:
- system V�����ڴ�
- system V��Ϣ����
- system V�ź���
����,system V�����ڴ��system V��Ϣ�������Դ�������ΪĿ�ĵ�,��system
V�ź�����Ϊ�˱�֤���̼��ͬ���뻥�����Ƶ�,��Ȼsystem V�ź�����ͨ�ź���û��ֱ�ӹ�ϵ,������ͨ�ŷ��롣
system V�����ڴ�
�����ڴ�Ļ���ԭ��
�ִ�����ϵͳ,�����ڴ����,���õ��������ڴ漼��,Ҳ����ÿ�����̶����Լ������������ڴ�ռ�,��ͬ���̵������ڴ�ӳ�䵽��ͬ�������ڴ��С�����,��ʹ���� A �� ���� B �������ַ��һ����,��ʵ���ʵ��Dz�ͬ�������ڴ��ַ,�������ݵ���ɾ��Ļ���Ӱ�졣
�����ڴ�Ļ���,�����ó�һ�������ַ�ռ���,ӳ�䵽��ͬ�������ڴ��С�
�����������д��Ķ���,����һ���������Ͼ��ܿ�����,������Ҫ����������ȥ,������ȥ,�������˽��̼�ͨ�ŵ��ٶȡ�
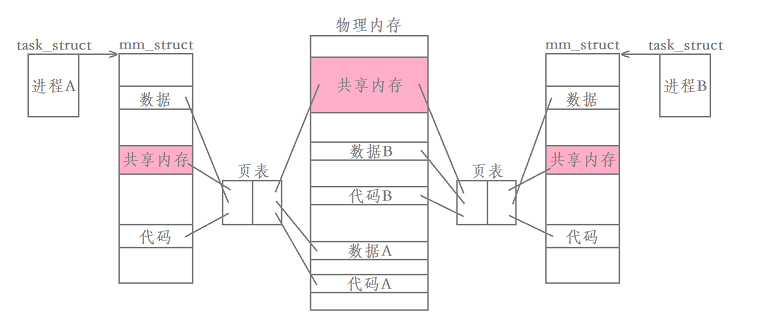
������˵�Ŀ��������ռ䡢����ӳ��Ȳ������ǵ���ϵͳ�ӿ���ɵ�,Ҳ����˵��Щ�������ɲ���ϵͳ����ɡ�
�����ڴ�Ľ���:
1.���빲���ڴ�
2.��ͬ�Ľ��̷ֱ�ҽӶ�Ӧ�Ĺ����ڴ浽�Լ��ĵ�ַ�ռ�(������ӳ���ϵ)
3.˫���Ϳ�����ͬһ����Դ�������Խ�������ͨ���ˡ�
�����ڴ���ͷ�:
1.�������ڴ����ַ�ռ�ȥ����,��ȡ��ӳ���ϵ��
2.�ͷŹ����ڴ�ռ�,���������ڴ�黹��ϵͳ��
�����ڴ����ݽṹ
��ϵͳ���п��ܻ��д����Ľ����ڽ���ͨ��,���ϵͳ���оͿ��ܴ��ڴ����Ĺ����ڴ�,��ô����ϵͳ��ȻҪ������й���,���Թ����ڴ�������ڴ浱���������ٿռ�֮��,ϵͳһ����ҪΪ�����ڴ�ά����ص��ں����ݽṹ��
�����ڴ�����ݽṹ����:
struct shmid_ds {
struct ipc_perm shm_perm; /* operation perms */
int shm_segsz; /* size of segment (bytes) */
__kernel_time_t shm_atime; /* last attach time */
__kernel_time_t shm_dtime; /* last detach time */
__kernel_time_t shm_ctime; /* last change time */
__kernel_ipc_pid_t shm_cpid; /* pid of creator */
__kernel_ipc_pid_t shm_lpid; /* pid of last operator */
unsigned short shm_nattch; /* no. of current attaches */
unsigned short shm_unused; /* compatibility */
void *shm_unused2; /* ditto - used by DIPC */
void *shm_unused3; /* unused */
};
������������һ�鹲���ڴ��,Ϊ����Ҫʵ��ͨ�ŵĽ����ܹ�����ͬһ�������ڴ�,���ÿһ�������ڴ汻����ʱ����һ��keyֵ,���keyֵ���ڱ�ʶϵͳ�й����ڴ��Ψһ�ԡ�
���Կ������湲���ڴ����ݽṹ�ĵ�һ����Ա��shm_perm,shm_perm��һ��ipc_perm���͵Ľṹ�����,ÿ�������ڴ��keyֵ�洢��shm_perm����ṹ���������,����ipc_perm�ṹ��Ķ�������:
struct ipc_perm{
__kernel_key_t key;
__kernel_uid_t uid;
__kernel_gid_t gid;
__kernel_uid_t cuid;
__kernel_gid_t cgid;
__kernel_mode_t mode;
unsigned short seq;
};
�����ڴ�����ݽṹshmid_ds��ipc_perm�ṹ��ֱ���/usr/include/linux/shm.h��/usr/include/linux/ipc.h�ж��塣
�����ڴ�Ĵ���
���������ڴ�������Ҫ��shmget����,shmget�����ĺ���ԭ������:
int shmget(key_t key, size_t size, int shmflg);
shmget����������˵��:
- ��һ������key,��ʾ�����������ڴ���ϵͳ���е�Ψһ��ʶ��
- �ڶ�������size,��ʾ�����������ڴ�Ĵ�С��(�����С�����Ͽ�������ȥָ��,��������4KB�ı�����С��)
��Ϊϵͳ�ڷ��乲���ڴ��ʱ��,����4KBΪ������λ��,������Ҫ4097,����ϵͳ�ڷ����ʱ����4096+4096��8kb����������Ȼֻ����4097,�ͻ��˷���4095���ֽڡ����Խ���4kb��������,�����Ͳ����ڹ����ڴ�ռ��˷ѵ����⡣
- ����������shmflg,��ʾ���������ڴ�ķ�ʽ��
shmget����������ֵ˵��:
- shmget���óɹ�,����һ����Ч�Ĺ����ڴ��ʶ��(�û����ʶ��)��
- shmget����ʧ��,����-1��
ע��: ���ǰѾ��б궨ij����Դ�����Ķ����������,������shmget�����ķ���ֵʵ���Ͼ��ǹ����ڴ�ľ��,�������������û����ʶ�����ڴ�,�������ڴ汻������,�����ں���ʹ�ù����ڴ����ؽӿ�ʱ,������Ҫͨ����������ָ�������ڴ���и��ֲ�����
����shmget�����ĵ�һ������key,��Ҫ����ʹ��ftok�������л�ȡ
ftok�����ĺ���ԭ������:
key_t ftok(const char *pathname, int proj_id);
ftok���������þ���,��һ���Ѵ��ڵ�·����pathname��һ��������ʶ��proj_idת����һ��keyֵ,��ΪIPC��ֵ,��ʹ��shmget������ȡ�����ڴ�ʱ,���keyֵ�ᱻ����ά�������ڴ�����ݽṹ���С���Ҫע�����,pathname��ָ�����ļ���������ҿɴ�ȡ��
ע��:
- ʹ��ftok��������keyֵ���ܻ������ͻ,��ʱ���ԶԴ���ftok�����IJ��������ġ�
- ��Ҫ����ͨ�ŵĸ�������,��ʹ��ftok������ȡkeyֵʱ,����Ҫ����ͬ����·�����ͺ�������ʶ��,��������ͬһ��keyֵ,Ȼ������ҵ�ͬһ��������Դ��
����shmget�����ĵ���������shmflg,���õ���Ϸ�ʽ����������:
| ��Ϸ�ʽ | ���� |
|---|---|
| IPC_CREAT | ����ں��в����ڼ�ֵ��key��ȵĹ����ڴ�,���½�һ�������ڴ沢���ظù����ڴ�ľ��;������������Ĺ����ڴ�,��ֱ�ӷ��ظù����ڴ�ľ�� |
| IPC_EXCL | ���������key��ȹ����ڴ�ͻ��������,�������ʹ����û���κ������ |
- ʹ�����IPC_CREAT,һ������һ�������ڴ�ľ��,����ȷ�ϸù����ڴ��Ƿ����½��Ĺ����ڴ档
- ʹ�����IPC_CREAT | IPC_EXCL,ֻ��shmget�������óɹ�ʱ�Ż��ù����ڴ�ľ��,���Ҹù����ڴ�һ�����½��Ĺ����ڴ档
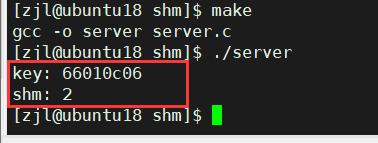
�������ǾͿ���ʹ��ftok��shmget��������һ�鹲���ڴ���,���������ǿ��Խ������ڴ��keyֵ�;�����д�ӡ,�Ա�۲�,��������:
#include <stdio.h>
#include <sys/types.h>
#include <sys/ipc.h>
#include <sys/shm.h>
#include <unistd.h>
#define PATHNAME "/home/cl/Linuxcode/IPC/shm/server.c" //·����
#define PROJ_ID 0x6666 //������ʶ��
#define SIZE 4096 //�����ڴ�Ĵ�С
int main()
{
key_t key = ftok(PATHNAME, PROJ_ID); //ת������keyֵ
if (key < 0){
perror("ftok");
return 1;
}
int shm = shmget(key, SIZE, IPC_CREAT | IPC_EXCL); //�����µĹ����ڴ�
if (shm < 0){
perror("shmget");
return 2;
}
printf("key: %x\n", key); //��ӡkeyֵ
printf("shm: %d\n", shm); //��ӡ���
return 0;
}
��Linux����,���ǿ���ʹ��ipcs����鿴�йؽ��̼�ͨ����ʩ����Ϣ��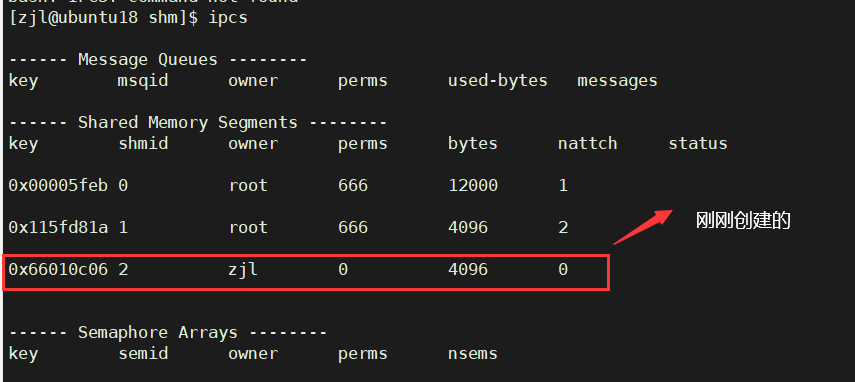
����ʹ��ipcs����ʱ,��Ĭ���г���Ϣ���С������ڴ��Լ��ź�����ص���Ϣ,��ֻ��鿴����֮��ijһ���������Ϣ,����ѡ��Я������ѡ��:
-q:�г���Ϣ���������Ϣ��
-m:�г������ڴ������Ϣ��
-s:�г��ź��������Ϣ��
ipcs���������ÿ����Ϣ�ĺ�������:
| ���� | ���� |
|---|---|
| key | ϵͳ������������ڴ��Ψһ��ʶ |
| shmid | �����ڴ���û���id(���) |
| owner | �����ڴ��ӵ���� |
| perms | �����ڴ��Ȩ�� |
| bytes | �����ڴ�Ĵ�С |
| nattch | ���������ڴ�Ľ����� |
| status | �����ڴ��״̬ |
ע��: key�����ں˲����ϱ�֤�����ڴ�Ψһ�Եķ�ʽ,��shmid�����û������ϱ�֤�����ڴ��Ψһ��.
- key:��һ���û������ɵ�Ψһ��ֵ,����������Ϊ�����ֹ����ڴ�ġ�Ψһ�ԡ�,������������IPC��Դ�IJ������������ļ���inode�š�
- shmid:��һ��ϵͳ�����Ƿ��ص�IPC��Դ��ʶ��,�������в���IPC��Դ���������ļ���fd��
�����ڴ���ͷ�
�����ǵĽ���������Ϻ�,����Ĺ����ڴ����ɴ���,��û�б�����ϵͳ�ͷš�ʵ����,�ܵ�����������������̵�,�������ڴ���������������ں˵�,Ҳ����˵������Ȼ�Ѿ��˳�,�������������Ĺ����ڴ治�����Ž��̵��˳����ͷš�
��˵��,������̲�����ɾ�������Ĺ����ڴ�,��ô�����ڴ�ͻ�һֱ����,ֱ���ػ�����(system V IPC�������),ͬʱҲ˵����IPC��Դ�����ں��ṩ��ά���ġ�
��ʱ��������Ҫ�������Ĺ����ڴ��ͷ�,����������,һ����ʹ�������ͷŹ����ڴ�,�������ڽ���ͨ����Ϻ�����ͷŹ����ڴ�ĺ��������ͷš�
1.ʹ�������ͷŹ����ڴ���Դ
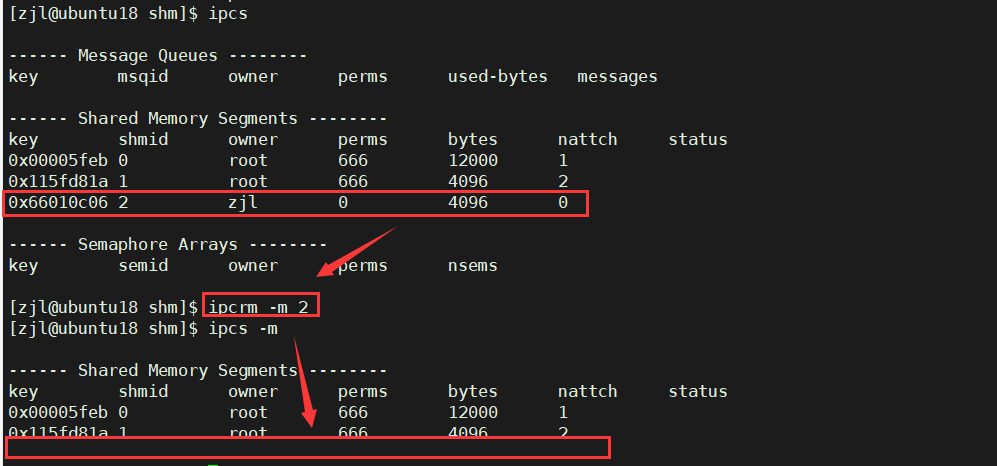
���ǿ���ʹ��ipcrm -m shmid�����ͷ�ָ��id�Ĺ����ڴ���Դ��
$ ipcrm -m 2
2.ʹ�ó����ͷŹ����ڴ���Դ
���ƹ����ڴ�������Ҫ��shmctl����,shmctl�����ĺ���ԭ������:
int shmctl(int shmid, int cmd, struct shmid_ds *buf);
shmctl�����IJ���˵��:
- ��һ������shmid,��ʾ�����ƹ����ڴ���û�����ʶ����
- �ڶ�������cmd,��ʾ����Ŀ��ƶ�����
- ����������buf,���ڻ�ȡ�����������ƹ����ڴ�����ݽṹ��
shmctl�����ķ���ֵ˵��:
- shmctl���óɹ�,����0��
- shmctl����ʧ��,����-1��
����,��Ϊshmctl�����ĵڶ�����������ij��õ�ѡ������������:
| ѡ�� | ���� |
|---|---|
| IPC_STAT | ��ȡ�����ڴ�ĵ�ǰ����ֵ,��ʱ����buf��Ϊ����Ͳ��� |
| IPC_SET | �ڽ������㹻Ȩ��ǰ����,�������ڴ�ĵ�ǰ����ֵ����Ϊbuf��ָ�����ݽṹ�е�ֵ |
| IPC_RMID | ɾ�������ڴ�� |
��Ҫ�ͷŹ����ڴ����ѡ������ѡ��IPC_RMID��
����ֵ:�����ɹ�ʱ���� 0,����ʱ���� -1��
���������ڴ��ȥ���������ڴ�
�������ڴ����ӵ����̵�ַ�ռ�������Ҫ��shmat����,shmat�����ĺ���ԭ������:
void *shmat(int shmid, const void *shmaddr, int shmflg);
shmat�����IJ���˵��:
- ��һ������shmid,��ʾ�����������ڴ���û�����ʶ����
- �ڶ�������shmaddr,ָ�������ڴ�ӳ�䵽���̵�ַ�ռ��ijһ��ַ,ͨ������ΪNULL,��ʾ���ں��Լ�����һ�����ʵĵ�ַλ�á�
- ����������shmflg,��ʾ���������ڴ�ʱ���õ�ijЩ���ԡ�
shmat�����ķ���ֵ˵��:
- shmat���óɹ�,���ع����ڴ�ӳ�䵽���̵�ַ�ռ��е���ʼ��ַ��
- shmat����ʧ��,����(void*)-1��
����,��Ϊshmat�����ĵ�������������ij��õ�ѡ������������:
| ѡ�� | ���� |
|---|---|
| SHM_RDONLY | ���������ڴ��ֻ���ж�ȡ���� |
| SHM_RND | ��shmaddr��ΪNULL,�������ַ�Զ����µ���ΪSHMLBA������������ʽ:shmaddr-(shmaddr%SHMLBA) |
| 0 | Ĭ��Ϊ��дȨ�� |
��ʱ���ǿ��Գ���ʹ��shmat�����Թ����ڴ���й���:
#include <stdio.h>
#include <sys/types.h>
#include <sys/ipc.h>
#include <sys/shm.h>
#include <unistd.h>
#define PATHNAME "/home/cl/Linuxcode/IPC/shm/server.c" //·����
#define PROJ_ID 0x6666 //������ʶ��
#define SIZE 4096 //�����ڴ�Ĵ�С
int main()
{
key_t key = ftok(PATHNAME, PROJ_ID); //��ȡkeyֵ
if (key < 0){
perror("ftok");
return 1;
}
int shm = shmget(key, SIZE, IPC_CREAT | IPC_EXCL); //�����µĹ����ڴ�
if (shm < 0){
perror("shmget");
return 2;
}
printf("key: %x\n", key); //��ӡkeyֵ
printf("shm: %d\n", shm); //��ӡ���
printf("attach begin!\n");
sleep(2);
char* mem = shmat(shm, NULL, 0); //���������ڴ�
if (mem == (void*)-1){
perror("shmat");
return 1;
}
printf("attach end!\n");
sleep(2);
shmctl(shm, IPC_RMID, NULL); //�ͷŹ����ڴ�
return 0;
}
�������к��ֹ���ʧ��,��Ҫԭ��������ʹ��shmget�������������ڴ�ʱ,��û�жԴ����Ĺ����ڴ�����Ȩ��,���Դ��������Ĺ����ڴ��Ĭ��Ȩ��Ϊ0,��ʲôȨ��û��,���server����û��Ȩ�����ù����ڴ档
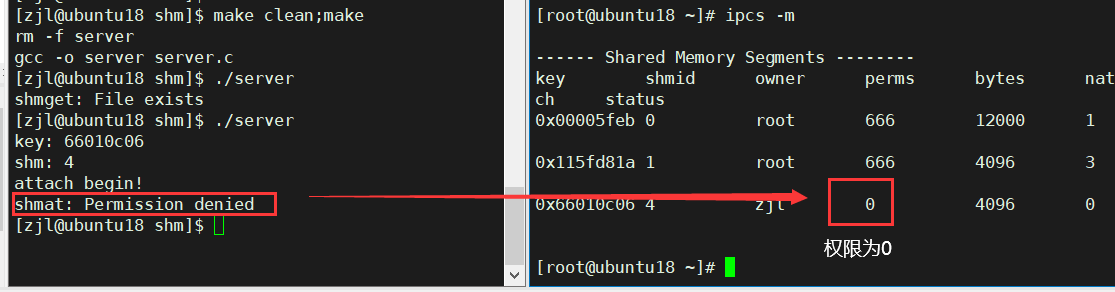
����Ӧ����ʹ��shmget�������������ڴ�ʱ,������������������ù����ڴ洴�����Ȩ��,Ȩ�����ù����������ļ�Ȩ�Ĺ�����ͬ��
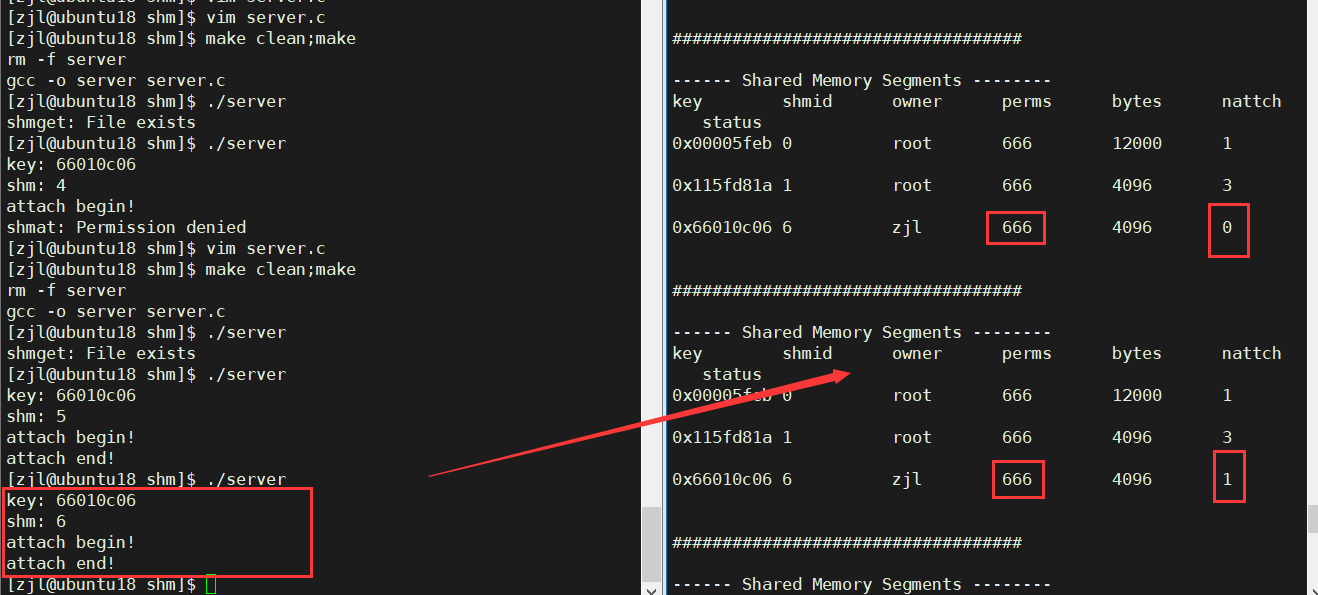
int shm = shmget(key, SIZE, IPC_CREAT | IPC_EXCL | 0666); //����Ȩ��Ϊ0666�Ĺ����ڴ�
��ʱ�����г���,���ɷ��ֹ����ù����ڴ�Ľ�������0�����1,�������ڴ��Ȩ����ʾҲ������0,�����������õ�666Ȩ�ޡ�
ȡ�������ڴ�����̵�ַ�ռ�֮��Ĺ���������Ҫ��shmdt����
shmdt�����ĺ���ԭ������:
int shmdt(const void *shmaddr);
shmdt�����IJ���˵��:
- ��ȥ���������ڴ����ʼ��ַ,������shmat����ʱ�õ�����ʼ��ַ��
shmdt�����ķ���ֵ˵��:
- shmdt���óɹ�,����0��
- shmdt����ʧ��,����-1��
����������ȡ�������ڴ������֮��Ĺ���:
#include <stdio.h>
#include <sys/types.h>
#include <sys/ipc.h>
#include <sys/shm.h>
#include <unistd.h>
#define PATHNAME "/home/cl/Linuxcode/IPC/shm/server.c" //·����
#define PROJ_ID 0x6666 //������ʶ��
#define SIZE 4096 //�����ڴ�Ĵ�С
int main()
{
key_t key = ftok(PATHNAME, PROJ_ID); //��ȡkeyֵ
if (key < 0){
perror("ftok");
return 1;
}
int shm = shmget(key, SIZE, IPC_CREAT | IPC_EXCL | 0666); //�����µĹ����ڴ�
if (shm < 0){
perror("shmget");
return 2;
}
printf("key: %x\n", key); //��ӡkeyֵ
printf("shm: %d\n", shm); //��ӡ���
printf("attach begin!\n");
sleep(2);
char* mem = shmat(shm, NULL, 0); //���������ڴ�
if (mem == (void*)-1){
perror("shmat");
return 1;
}
printf("attach end!\n");
sleep(2);
printf("detach begin!\n");
sleep(2);
shmdt(mem); //�����ڴ�ȥ����
printf("detach end!\n");
sleep(2);
shmctl(shm, IPC_RMID, NULL); //�ͷŹ����ڴ�
return 0;
}
���г���,ͨ����ؼ��ɷ��ָù����ڴ�Ĺ�������1��Ϊ0�Ĺ���,��ȡ���˹����ڴ���ý���֮��Ĺ�����
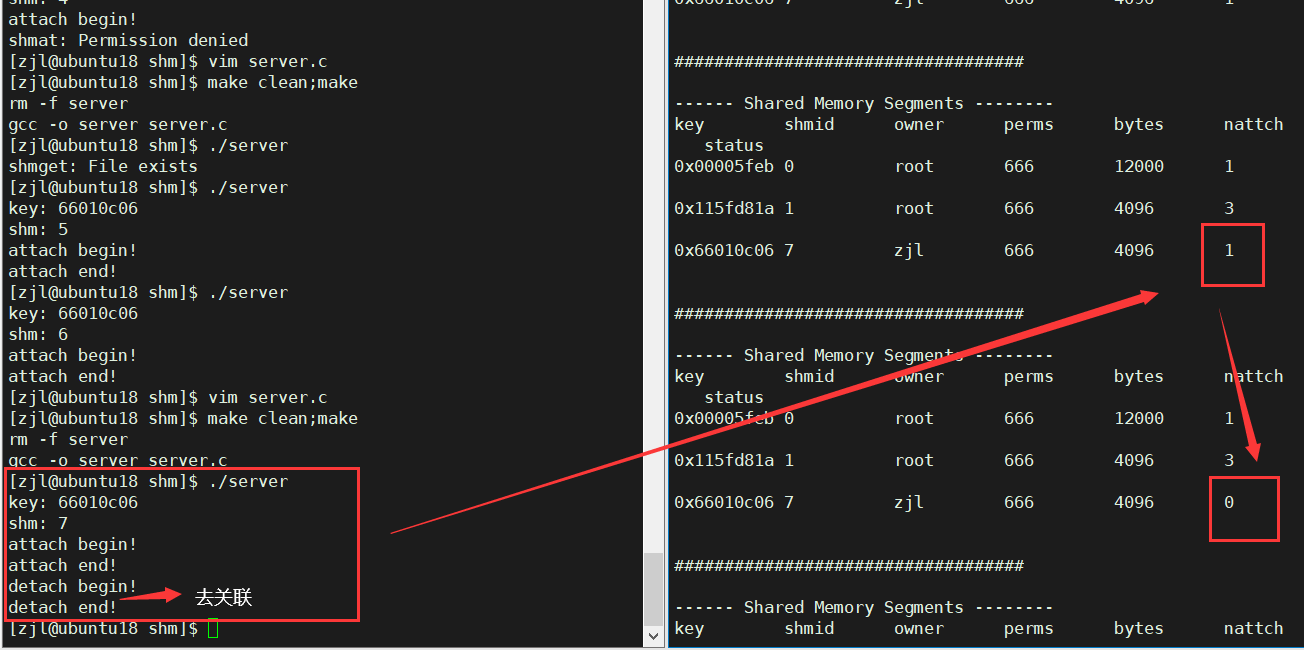
ע��: �������ڴ���뵱ǰ�������벻����ɾ�������ڴ�,ֻ��ȡ���˵�ǰ������ù����ڴ�֮�����ϵ��
�ù����ڴ�ʵ��serve&clientͨ��
��֪���˹����ڴ�Ĵ�����������ȥ�����Լ��ͷź�,���ڿ��Գ�������������ͨ�������ڴ����ͨ���ˡ������������̽���ͨ��֮ǰ,���ǿ����Ȳ���һ�������������ܷ�ɹ��ҽӵ�ͬһ�������ڴ��ϡ�
����˸��������ڴ�,�����ú����ڴ�ͷ���˽��й���,֮�������ѭ��,���ڹ۲������Ƿ�ҽӳɹ���
//server.c
#include "comm.h"
int main()
{
key_t key = ftok(PATHNAME, PROJ_ID); //��ȡkeyֵ
if (key < 0){
perror("ftok");
return 1;
}
int shm = shmget(key, SIZE, IPC_CREAT | IPC_EXCL | 0666); //�����µĹ����ڴ�
if (shm < 0){
perror("shmget");
return 2;
}
printf("key: %x\n", key); //��ӡkeyֵ
printf("shm: %d\n", shm); //��ӡ�����ڴ��û���id
char* mem = shmat(shm, NULL, 0); //���������ڴ�
while (1){
//�������
}
shmdt(mem); //�����ڴ�ȥ����
shmctl(shm, IPC_RMID, NULL); //�ͷŹ����ڴ�
return 0;
}
�ͻ���ֻ��Ҫֱ�Ӻͷ���˴����Ĺ����ڴ���й�������,֮��Ҳ������ѭ��,���ڹ۲�ͻ����Ƿ�ҽӳɹ���
//client.c
#include "comm.h"
int main()
{
key_t key = ftok(PATHNAME, PROJ_ID); //��ȡ��server������ͬ��keyֵ
if (key < 0){
perror("ftok");
return 1;
}
int shm = shmget(key, SIZE, IPC_CREAT); //��ȡserver���̴����Ĺ����ڴ���û���id
if (shm < 0){
perror("shmget");
return 2;
}
printf("key: %x\n", key); //��ӡkeyֵ
printf("shm: %d\n", shm); //��ӡ�����ڴ��û���id
char* mem = shmat(shm, NULL, 0); //���������ڴ�
int i = 0;
while (1){
//�������
}
shmdt(mem); //�����ڴ�ȥ����
return 0;
}
Ϊ���÷���˺Ϳͻ�����ʹ��ftok������ȡkeyֵʱ,�ܹ��õ�ͬһ��keyֵ,��ô����˺Ϳͻ��˴���ftok������·�����ͺ�������ʶ��������ͬ,������������ͬһ��keyֵ,�����ҵ�ͬһ��������Դ���йҽӡ��������ǿ��Խ���Щ��Ҫ���õ���Ϣ����һ��ͷ�ļ�����,����˺Ϳͻ��˹������ͷ�ļ����ɡ�
//comm.h
#include <stdio.h>
#include <stdio.h>
#include <sys/types.h>
#include <sys/ipc.h>
#include <sys/shm.h>
#include <unistd.h>
#define PATHNAME "/home/cl/Linuxcode/IPC/shm/server.c" //·����
#define PROJ_ID 0x6666 //������ʶ��
#define SIZE 4096 //�����ڴ�Ĵ�С
�Ⱥ����з���˺Ϳͻ��˺�,ͨ����ؽű����Կ�������˺Ϳͻ�������������ͬһ�������ڴ�,�����ڴ�����Ľ�����Ҳ��2,��ʾ����˺Ϳͻ��˹ҽӹ����ڴ�ɹ���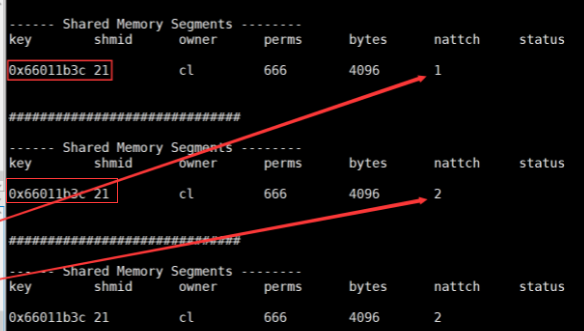
��ʱ���ǾͿ����÷���˺Ϳͻ��˽���ͨ����,�����Լķ����ַ���Ϊ����
�ͻ��˲��������ڴ�д������:
//client.c
int i = 0;
while (1){
mem[i] = 'A' + i;
i++;
mem[i] = '\0';
sleep(1);
}
����˲��϶�ȡ�����ڴ浱�е����ݲ����:
//server.c
while (1){
printf("%s\n", mem);
sleep(1);
}
��ʱ�����з���˴��������ڴ�,Ȼ���������пͻ���,����˾Ϳ�ʼ�����������,˵������˺Ϳͻ������ܹ�����ͨ�ŵġ�
�����ڴ���ܵ����жԱ�
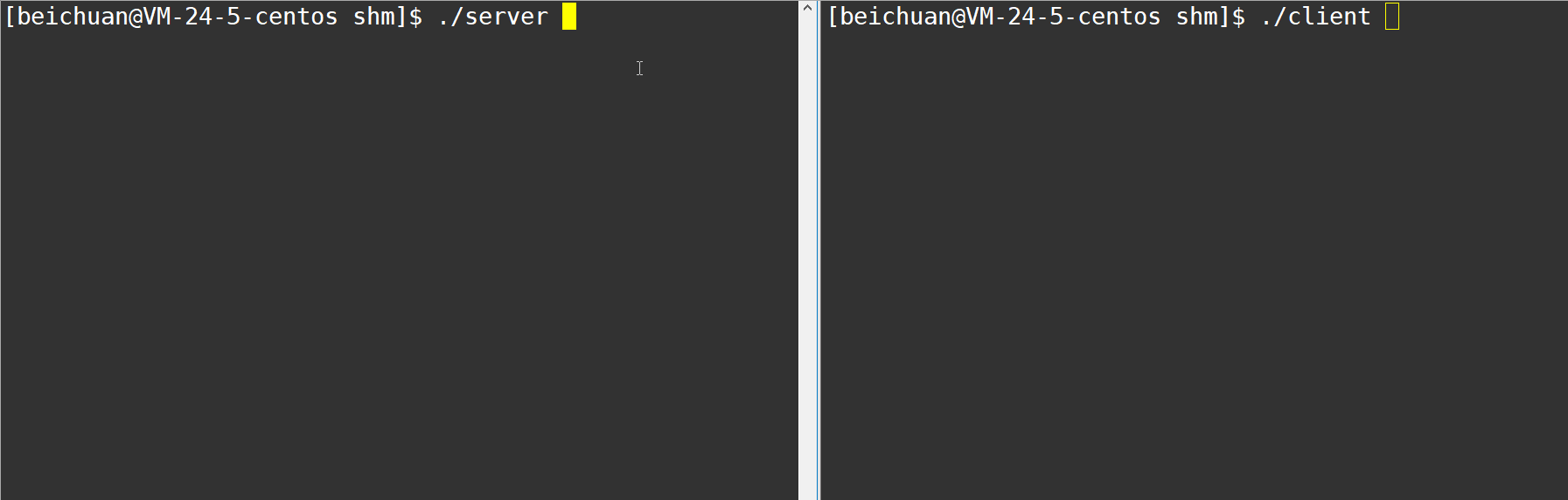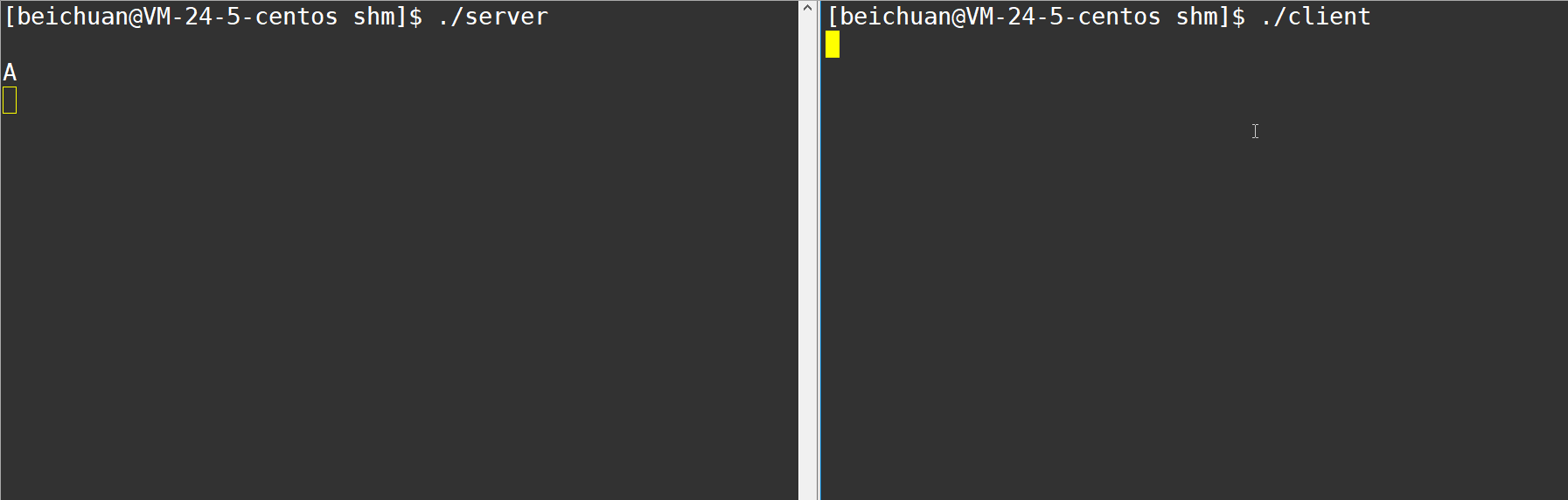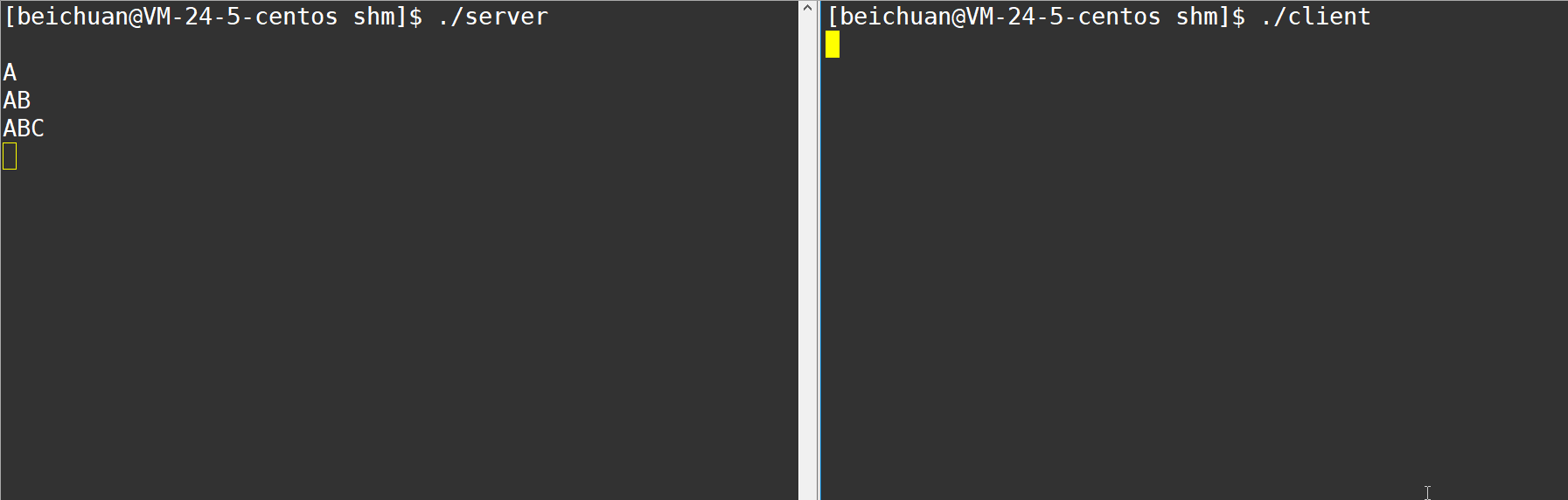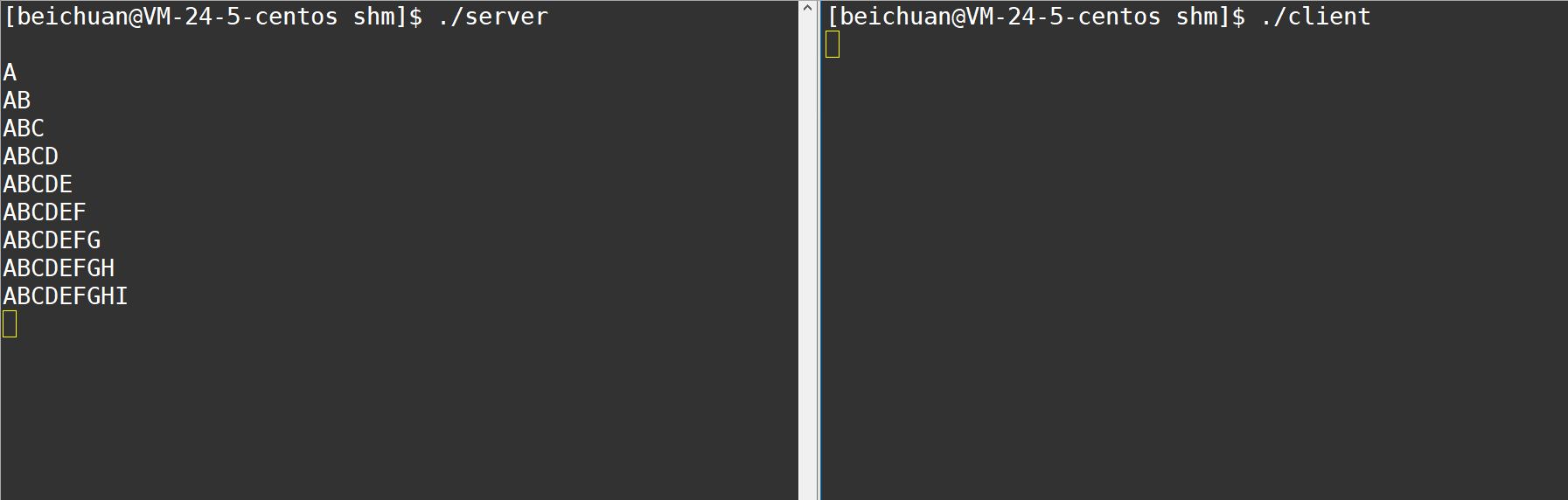
�������ڴ洴���ú�Ͳ�����Ҫ����ϵͳ�ӿڽ���ͨ����,���ܵ������ú�����Ҫread��write��ϵͳ�ӿڽ���ͨ�š������ڴ������н��̼�ͨ�ŷ�ʽ������һ��ͨ�ŷ�ʽ��
�������������ܵ�ͨ��:
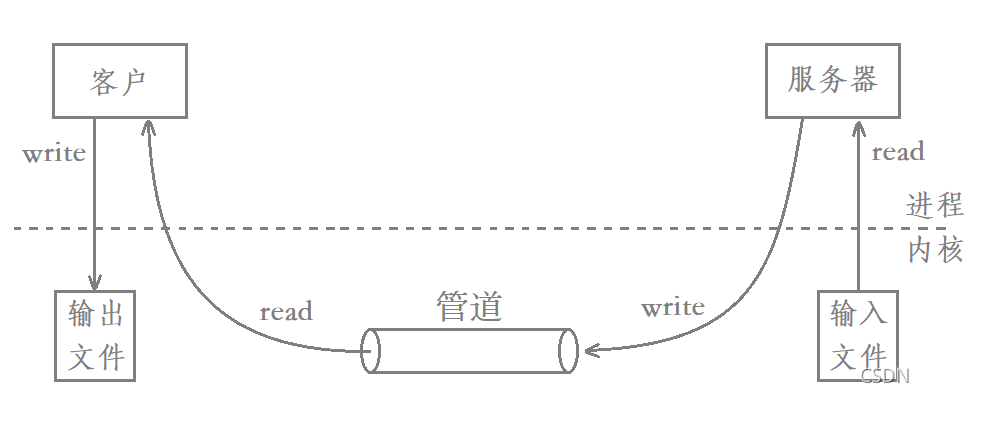
������ͼ���Կ���,ʹ�ùܵ�ͨ�ŵķ�ʽ,��һ���ļ���һ�����̴��䵽��һ��������Ҫ�����Ĵο�������:
- 1.����˽���Ϣ�������ļ����Ƶ�����˵���ʱ�������С�
- 2.���������ʱ����������Ϣ���Ƶ��ܵ��С�
- 3.�ͻ��˽���Ϣ�ӹܵ����Ƶ��ͻ��˵Ļ������С�
- 4.���ͻ�����ʱ����������Ϣ���Ƶ�����ļ��С�
�����������������ڴ�ͨ��:
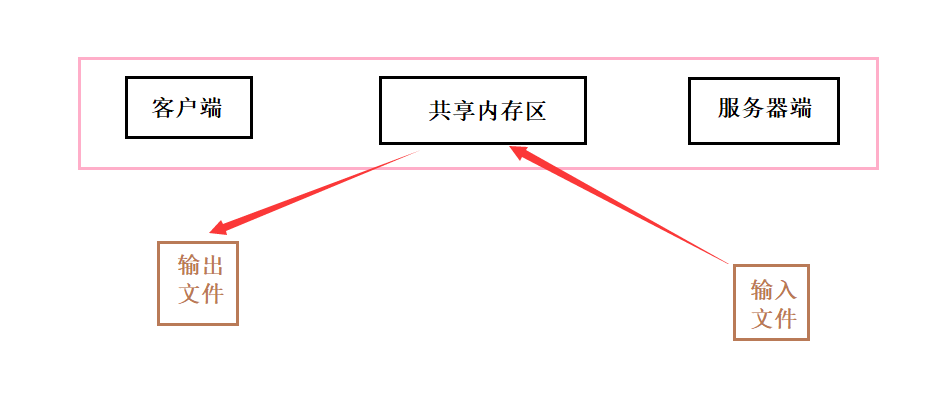
������ͼ���Կ���,ʹ�ù����ڴ����ͨ��,��һ���ļ���һ�����̴��䵽��һ������ֻ��Ҫ�������ο�������:
- �������ļ��������ڴ档
- �ӹ����ڴ浽����ļ���
���Թ����ڴ������н��̼�ͨ�ŷ�ʽ������һ��ͨ�ŷ�ʽ,��Ϊ��ͨ�ŷ�ʽ��Ҫ���еĿ����������١�
���ǹ����ڴ�Ҳ����ȱ���,����֪���ܵ����Դ�ͬ���뻥����Ƶ�,���ǹ����ڴ沢û���ṩ�κεı�������,��Ҫ����Ա�Լ�ȷ�����ݵİ�ȫ�ԡ�
System V��Ϣ����
��Ϣ���еĻ���ԭ��
��Ϣ�����DZ������ں��е���Ϣ����,�ڷ�������ʱ,��ֳ�һ��һ�����������ݵ�Ԫ,Ҳ������Ϣ��(���ݿ�),��Ϣ�����û��Զ������������,��Ϣ�ķ��ͷ��ͽ��շ�ҪԼ������Ϣ�����������,����ÿ����Ϣ�嶼�ǹ̶���С�Ĵ洢��,����ܵ�����ʽ���ֽ������ݡ�������̴���Ϣ�����ж�ȡ����Ϣ��,�ں˾ͻ�������Ϣ��ɾ����������������Է�������ʱ,������Ϣ���еĶ�β�������ݿ�,���������̻�ȡ���ݿ�ʱ,������Ϣ���еĶ�ͷȡ���ݿ顣
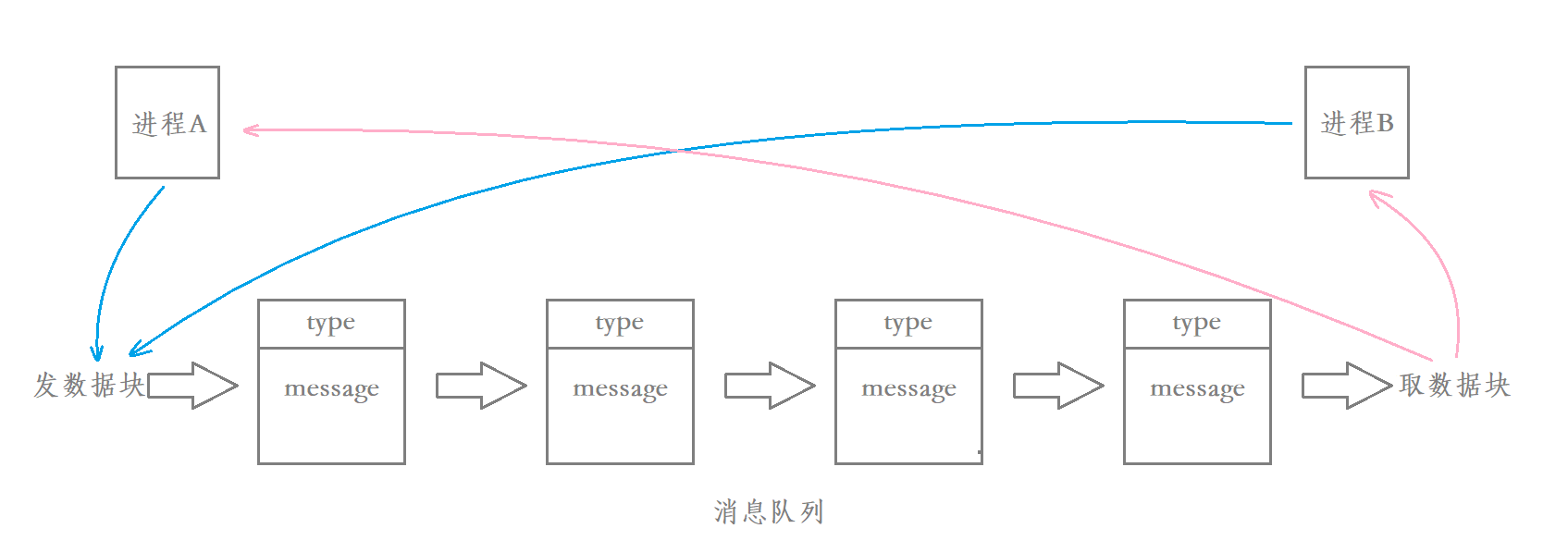
��Ϣ���������������ں�,���û���ͷ���Ϣ���л���û�йرղ���ϵͳ,��Ϣ���л�һֱ����,��ǰ���ᵽ�������ܵ�����������,������̵Ĵ���������,����̵Ľ��������١�
��Ϣ����ģ��,��������֮���ͨ�ž���ƽʱ���ʼ�һ��,����һ��,�һ�һ��,����Ƶ����ͨ�ˡ�
���ʼ���ͨ�ŷ�ʽ���ڲ���ĵط�������,һ��ͨ�Ų���ʱ,���Ǹ���Ҳ�д�С����,��ͬ��Ҳ����Ϣ����ͨ�Ų���ĵ㡣
��Ϣ���в��ʺϱȽϴ����ݵĴ���,��Ϊ���ں���ÿ����Ϣ�嶼��һ����ȵ�����,ͬʱ���ж�����������ȫ����Ϣ����ܳ���Ҳ�������ޡ��� Linux �ں���,���������궨�� MSGMAX �� MSGMNB,�������ֽ�Ϊ��λ,�ֱ�����һ����Ϣ����Ⱥ�һ�����е���ȡ�
��Ϣ����ͨ�Ź�����,�����û�̬���ں�̬֮������ݿ�������,��Ϊ����д�����ݵ��ں��е���Ϣ����ʱ,�ᷢ�����û�̬�������ݵ��ں�̬�Ĺ���,ͬ����һ���̶�ȡ�ں��е���Ϣ����ʱ,�ᷢ�����ں�̬�������ݵ��û�̬�Ĺ��̡�
��Ϣ�������ݽṹ
��Ȼ,ϵͳ����Ҳ���ܻ���ڴ�������Ϣ����,ϵͳһ��ҲҪΪ��Ϣ����ά����ص��ں����ݽṹ��
��Ϣ���е����ݽṹ����:
struct msqid_ds {
struct ipc_perm msg_perm;
struct msg *msg_first; /* first message on queue,unused */
struct msg *msg_last; /* last message in queue,unused */
__kernel_time_t msg_stime; /* last msgsnd time */
__kernel_time_t msg_rtime; /* last msgrcv time */
__kernel_time_t msg_ctime; /* last change time */
unsigned long msg_lcbytes; /* Reuse junk fields for 32 bit */
unsigned long msg_lqbytes; /* ditto */
unsigned short msg_cbytes; /* current number of bytes on queue */
unsigned short msg_qnum; /* number of messages in queue */
unsigned short msg_qbytes; /* max number of bytes on queue */
__kernel_ipc_pid_t msg_lspid; /* pid of last msgsnd */
__kernel_ipc_pid_t msg_lrpid; /* last receive pid */
};
���Կ�����Ϣ�������ݽṹ�ĵ�һ����Ա��msg_perm,����shm_perm��ͬһ�����͵Ľṹ�����,ipc_perm�ṹ��Ķ�������:
struct ipc_perm{
__kernel_key_t key;
__kernel_uid_t uid;
__kernel_gid_t gid;
__kernel_uid_t cuid;
__kernel_gid_t cgid;
__kernel_mode_t mode;
unsigned short seq;
};
�����ڴ�����ݽṹmsqid_ds��ipc_perm�ṹ��ֱ���/usr/include/linux/msg.h��/usr/include/linux/ipc.h�ж��塣
��Ϣ���еĴ���
������Ϣ����������Ҫ��msgget����,msgget�����ĺ���ԭ������:
int msgget(key_t key, int msgflg);
˵��һ��:
- ������Ϣ����Ҳ��Ҫʹ��ftok��������һ��keyֵ,���keyֵ��Ϊmsgget�����ĵ�һ��������
- msgget�����ĵڶ�������,�봴�������ڴ�ʱʹ�õ�shmget�����ĵ�����������ͬ��
- ��Ϣ���д����ɹ�ʱ,msgget�������ص�һ����Ч����Ϣ���б�ʶ��(�û����ʶ��)��
��Ϣ���е��ͷ�
�ͷ���Ϣ����������Ҫ��msgctl����,msgctl�����ĺ���ԭ������:
int msgctl(int msqid, int cmd, struct msqid_ds *buf);
˵��һ��:
- msgctl�����IJ������ͷŹ����ڴ�ʱʹ�õ�shmctl����������������ͬ,ֻ����msgctl�����ĵ������������������Ϣ���е�������ݽṹ��
����Ϣ���з�������
����Ϣ���з�������������Ҫ��msgsnd����,msgsnd�����ĺ���ԭ������:
int msgsnd(int msqid, const void *msgp, size_t msgsz, int msgflg);
msgsnd�����IJ���˵��:
- ��һ������msqid,��ʾ��Ϣ���е��û�����ʶ����
- �ڶ�������msgp,��ʾ�����͵����ݿ顣
- ����������msgsz,��ʾ���������ݿ�Ĵ�С
- ���ĸ�����msgflg,��ʾ�������ݿ�ķ�ʽ,һ��Ĭ��Ϊ0���ɡ�
msgsnd�����ķ���ֵ˵��:
- msgsnd���óɹ�,����0��
- msgsnd����ʧ��,����-1��
����msgsnd�����ĵڶ�����������Ϊ���½ṹ:
struct msgbuf{
long mtype; /* message type, must be > 0 */
char mtext[1]; /* message data */
};
ע��: �ýṹ���еĵڶ�����Աmtext��Ϊ�����͵���Ϣ,�����Ƕ���ýṹʱ,mtext�Ĵ�С�����Լ�ָ����
����Ϣ���л�ȡ����
����Ϣ���л�ȡ����������Ҫ��msgrcv����,msgrcv�����ĺ���ԭ������:
ssize_t msgrcv(int msqid, void *msgp, size_t msgsz, long msgtyp, int msgflg);
msgrcv�����IJ���˵��:
- ��һ������msqid,��ʾ��Ϣ���е��û�����ʶ����
- �ڶ�������msgp,��ʾ��ȡ�������ݿ�,��һ������Ͳ�����
- ����������msgsz,��ʾҪ��ȡ���ݿ�Ĵ�С
- ���ĸ�����msgtyp,��ʾҪ�������ݿ�����͡�
msgrcv�����ķ���ֵ˵��:
- msgsnd���óɹ�,����ʵ�ʻ�ȡ��mtext�����е��ֽ�����
- msgsnd����ʧ��,����-1��
System V�ź���
�ź���������
���˹����ڴ�ͨ�ŷ�ʽ,�����µ�����,�Ǿ�������������ͬʱ��ͬһ�������ڴ�,���п��ܾͳ�ͻ�ˡ������������̶�ͬʱдһ����ַ,����д���Ǹ����̻ᷢ�����ݱ����˸����ˡ�
Ϊ�˷�ֹ����̾���������Դ,����ɵ����ݴ���,������Ҫ��������,ʹ�ù�������Դ,������ʱ��ֻ�ܱ�һ�����̷��ʡ�����,�ź�����ʵ������һ�������ơ�
�ź�����ʵ��һ�����͵ļ�����,��Ҫ����ʵ�ֽ��̼�Ļ�����ͬ��,���������ڻ�����̼�ͨ�ŵ����ݡ�
�ź�����ʾ��Դ������,�����ź����ķ�ʽ������ԭ�Ӳ���:
- һ���� P ����,�����������ź�����ȥ -1,���������ź��� < 0,�������Դ�ѱ�ռ��,�����������ȴ�;���������ź��� >= 0,�����������Դ��ʹ��,���̿���������ִ�С�
- ��һ���� V ����,�����������ź������� 1,��Ӻ�����ź��� <= 0,�������ǰ�������еĽ���,���ǻὫ�ý��̻�������;��Ӻ�����ź��� > 0,�������ǰû�������еĽ���;
P ���������ڽ��빲����Դ֮ǰ,V �����������뿪������Դ֮��,�����������DZ���ɶԳ��ֵġ�
������,�ٸ�����,���Ҫʹ���������̻�����ʹ����ڴ�,���ǿ��Գ�ʼ���ź���Ϊ 1��
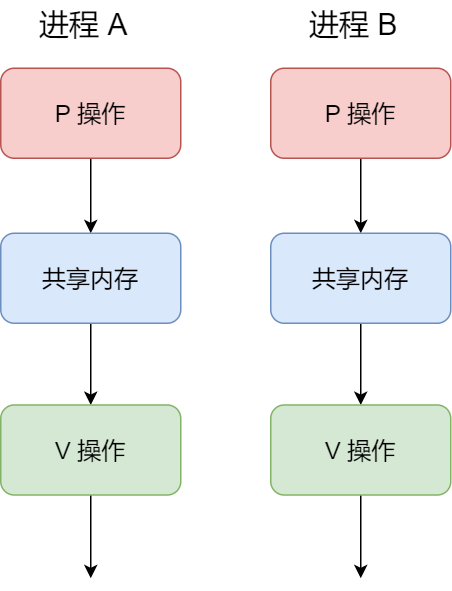
�����������:
- ���� A �ڷ��ʹ����ڴ�ǰ,��ִ���� P ����,�����ź����ij�ʼֵΪ 1,���ڽ��� A ִ�� P �������ź�����Ϊ 0,��ʾ������Դ����,���ǽ��� A �Ϳ��Է��ʹ����ڴ档
- ����ʱ,���� B Ҳ����ʹ����ڴ�,ִ���� P ����,����ź�����Ϊ�� -1,�����ζ���ٽ���Դ�ѱ�ռ��,��˽��� B ��������
- ֱ������ A �����깲���ڴ�,�Ż�ִ�� V ����,ʹ���ź����ָ�Ϊ 0,���žͻỽ�������е��߳� B,ʹ�ý��� B ���Է��ʹ����ڴ�,�����ɹ����ڴ�ķ��ʺ�,ִ�� V ����,ʹ�ź����ָ�����ʼֵ 1��
���Է���,�źų�ʼ��Ϊ 1,�ʹ������ǻ����ź���,�����Ա�֤�����ڴ����κ�ʱ��ֻ��һ�������ڷ���,��ͺܺõı����˹����ڴ档
����,�ڶ������,ÿ�����̲���һ����˳��ִ�е�,���ǻ������Ը��Զ����ġ�����Ԥ֪���ٶ���ǰ�ƽ�,����ʱ��������ϣ��������������к���,��ʵ��һ����ͬ������
����,���� A �Ǹ�����������,������ B �Ǹ����ȡ����,��������������������������,���� A ����������������,���� B ���ܶ�ȡ������,����ִ������ǰ��˳��ġ�
��ô��ʱ��,�Ϳ������ź�����ʵ�ֶ����ͬ���ķ�ʽ,���ǿ��Գ�ʼ���ź���Ϊ 0��
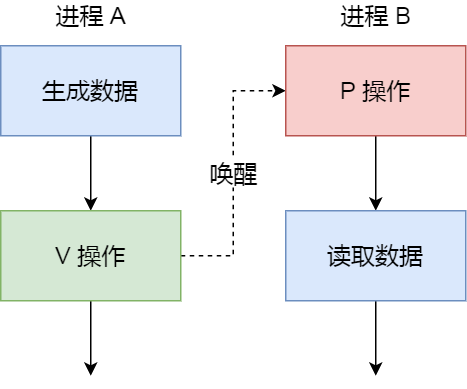
�������:
- ������� B �Ƚ��� A ��ִ����,��ôִ�е� P ����ʱ,�����ź�����ʼֵΪ 0,���ź������Ϊ -1,��ʾ���� A ��û��������,���ǽ��� B �������ȴ�;
- ����,������ A ���������ݺ�,ִ���� V ����,�ͻ�ʹ���ź�����Ϊ 0,���Ǿͻỽ�������� P �����Ľ��� B;
- ���,���� B �����Ѻ�,��ζ�Ž��� A �Ѿ�����������,���ǽ��� B �Ϳ���������ȡ�����ˡ�
���Է���,�źų�ʼ��Ϊ 0,�ʹ�������ͬ���ź���,�����Ա�֤���� A Ӧ�ڽ��� B ֮ǰִ�С�
�ź������ݽṹ
��ϵͳ����ҲΪ�ź���ά������ص��ں����ݽṹ��
�ź��������ݽṹ����:
struct semid_ds {
struct ipc_perm sem_perm; /* permissions .. see ipc.h */
__kernel_time_t sem_otime; /* last semop time */
__kernel_time_t sem_ctime; /* last change time */
struct sem *sem_base; /* ptr to first semaphore in array */
struct sem_queue *sem_pending; /* pending operations to be processed */
struct sem_queue **sem_pending_last; /* last pending operation */
struct sem_undo *undo; /* undo requests on this array */
unsigned short sem_nsems; /* no. of semaphores in array */
};
�ź������ݽṹ�ĵ�һ����ԱҲ��ipc_perm���͵Ľṹ�����,ipc_perm�ṹ��Ķ�������:
struct ipc_perm{
__kernel_key_t key;
__kernel_uid_t uid;
__kernel_gid_t gid;
__kernel_uid_t cuid;
__kernel_gid_t cgid;
__kernel_mode_t mode;
unsigned short seq;
};
�����ڴ�����ݽṹmsqid_ds��ipc_perm�ṹ��ֱ���/usr/include/linux/sem.h��/usr/include/linux/ipc.h�ж��塣
�ź�����غ���
�ź������Ĵ���
�����ź�����������Ҫ��semget����,semget�����ĺ���ԭ������:
int semget(key_t key, int nsems, int semflg);
˵��һ��:
- �����ź�����Ҳ��Ҫʹ��ftok��������һ��keyֵ,���keyֵ��Ϊsemget�����ĵ�һ��������
- semget�����ĵڶ�������nsems,��ʾ�����ź����ĸ�����
- semget�����ĵ���������,�봴�������ڴ�ʱʹ�õ�shmget�����ĵ�����������ͬ��
- �ź����������ɹ�ʱ,semget�������ص�һ����Ч���ź�������ʶ��(�û����ʶ��)��
�ź�������ɾ��
ɾ���ź�����������Ҫ��semctl����,semctl�����ĺ���ԭ������:
int semctl(int semid, int semnum, int cmd, ...);
�ź������IJ���
���ź��������в���������Ҫ��semop����,semop�����ĺ���ԭ������:
int semop(int semid, struct sembuf *sops, unsigned nsops);
�C the End �C
���Ͼ����ҷ����Ľ���ͨ���������,��л�Ķ�!
������¼��ר��:Linux
��ע����,�����Ķ����ߵ�����,ѧϰ����֪ʶ!
https://blog.csdn.net/weixin_53306029?spm=1001.2014.3001.5343
��������������������������������