接上一篇文章shell编程(九) : [shell基础] 呈现数据
目录
3.5 控制脚本
脚本的运行不只是手动执行命令,还有好多可以控制脚本运行的方法,下面将介绍这些方法。
3.5.1 利用信号控制脚本
Linux利用信号与运行在系统的进程进行通信。
常见Linux信号
| 信号 | 值 | 描述 |
|---|---|---|
| 1 | SIGHUP | 挂起进程 |
| 2 | SIGINT | 终止进程,Ctrl+C 触发 |
| 3 | SIGQUIT | 停止进程 |
| 9 | SIGKILL | 无条件终止进程,kill 命令触发 |
| 15 | SIGTERM | 尽可能终止进程 |
| 17 | SIGSTOP | 无条件停止进程,但不是终止进程 |
| 18 | SIGTSTP | 停止或暂停进程,但不终止进程,Ctrl+Z 触发 |
| 19 | SIGCONT | 继续运行停止的进程 |
使用 kill -l 指令可以查看更多的信号,
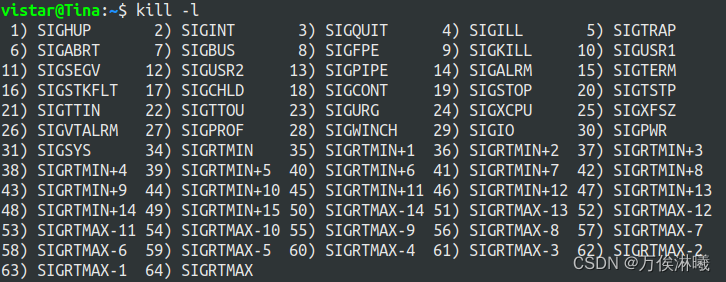
其中,1-31是普通信号(非可靠信号),34-64是实时信号(可靠信号)。
为了更好的运行脚本,默认情况下,bash shell会忽略这些信号,要在脚本中使用他们,可以利用一些命令。
trap
1. 监测系统信号
trap 命令可以拦截Linux信号,使信号不再由bash shell处理,而是由本地处理。
trap 命令格式:
trap commands signals
其中,commands 是收到信号后要执行的命令,signals 是监测的信号。
一个例子:
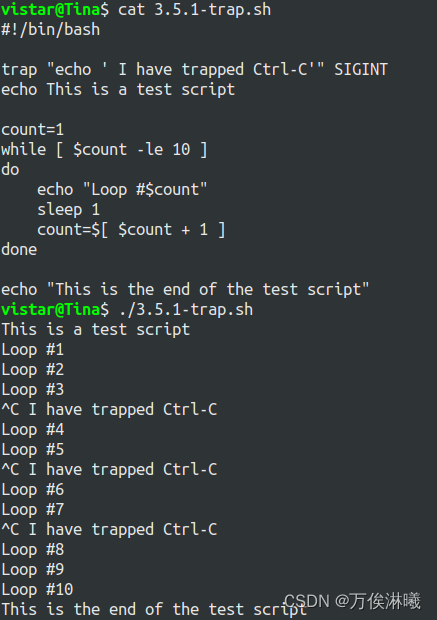
监测到 Ctrl-C 后并没有结束脚本,而是执行了 trap 设置的命令。
2. 监测脚本退出
如果想在脚本退出时执行一些任务,常做的方是在脚本最后添加相应语句,但如果脚本被中途退出,这些语句就不会被执行了。
trap 可以解决这一问题,无论脚本正常退出还是被中途退出,shell就会发出 EXIT 信号(函数结束或脚本退出),trap 会捕捉这一信号。这里的 EXIT 被称作伪信号,因为它由shell发出而不是操作系统发出的。

可以看到,无论脚本正常退出还是中途退出,都会打印 Goodbye...
3. 控制trap
有些情况下,需要在某个特定的作用域捕获特定的信号,这时就需要对上一句 trap 命令作修改,只需重新使用带有新选项的 trap命令即可,这一句会覆盖以前的 trap 命令。
如果想忽略某个信号,可以使用 trap "" signals 或 trap '' signals
恢复信号原有功能,trap signals 、trap - signals 或 trap -- signals
3.5.2 以后台模式运行脚本
使用 & 可以使命令或脚本在后台模式下运行,后台模式下,终端界面不再被占用,我们可以在该终端界面执行其他命令。
但后台模式的进程仍然会使用该终端界面显示 STDOUT 和 STDERR ,最好在脚本中将 STDOUT 和 STDERR 重定向。
虽然是后台模式,但进程还是依赖于该终端的,一旦退出该终端,后台进程也会随之退出。
3.5.3 脱离终端运行脚本
后台模式进程会随终端退出一起退出,但有时我们需要进程不依赖终端在后台运行,Linux提供了 nohup 命令来实现这一功能。
nohup 命令运行了另外一个命令来阻断所有发送给该进程的 SIGHUP 信号。这会在退出终端会话时阻止进程退出。退出终端时要注意,不能直接点 x 关掉终端,要输入exit 命令退出终端,否则后台进程仍然会结束掉。
由于进程不再同 STDOUT 和 STDERR 联系在一起,为了保存这些信息,nohup 命令会自动将 STDOUT和 STDERR 的消息重定向到一个名为 nohup.out 的文件中。
3.5.4 控制作业
作业是shell中的一个概念,每在shell中执行一条命令,就开启了一个作业。
启动、停止、终止以及恢复作业的这些功能统称为作业控制。
1. 查看作业
linux提供了 jobs 命令查看正在处理的作业情况。
先写一个测试用的脚本:
#!/bin/bash
# $$可以获取系统分配给该脚本的PID
echo "Script Process ID: $$"
count=1
while [ $count -le 10 ]
do
echo "Loop #$count"
sleep 10
count=$[ $count + 1 ]
done
echo "End of script..."
运行三次脚本,第一次当脚本进入循环,使用 Ctrl+Z 使脚本停止,第二次和第三次使用 ./jobs.sh > log & ,让脚本在后台运行,然后使用 jobs 命令,打印如下:

其中,带加号的作业会被当做默认作业。在使用作业控制命令时,如果未在命令行指定任何作业号,该作业会被当成作业控制命令的操作对象。当前的默认作业完成处理后,带减号的作业成为下一个默认作业。任何时候都只有一个带加号的作业和一个带减号的作业,不管shell中有多少个正在运行的作业。
jobs 命令还有一些选项,如下:
| 参数选项 | 描述 |
|---|---|
| -l | 列出进程的PID以及作业号 |
| -n | 只列出上次shell发出的通知后改变了状态的作业 |
| -p | 只列出作业的PID |
| -r | 只列出运行中的作业 |
| -s | 只列出已停止的作业 |
2. 重启停止的作业
在bash作业控制中,可以将已停止的作业作为后台进程或前台进程重启。
要以后台模式重启作业,可用 bg 命令加上作业号。
要以前台模式重启作业,可用 fg 命令加上作业号。
3.5.5 调度谦让度
在像Linux这样的多任务操作系统中,内核负责将CPU时间分配给每个运行在系统上的进程。这就涉及到优先级的问题,就像银行排队,军人的优先级最大一样,无论系统多繁忙,只要优先级高的进程来了就得先为其分配CPU时间。Linux定义了谦让度,其实就是优先级的相对属性,优先级高谦让度就低。Linux用整数来表示谦让度,从-20 到 19 ,数值越大谦让度越高,优先级越低。
Linux中由shell启动的进程的谦让度默认都是相同的,bash shell 启动进程的默认谦让度为 0。
1. 调整谦让度 - nice命令
nice 只有一个功能,就是调整进程的谦让度(niceness),格式如下:
nice -n 8 ./jobs.sh
nice -8 ./jobs.sh
两种格式是等效的,如果不指定谦让度,nice ./jobs.sh 默认谦让度是 10。
一个例子:

首先,执行脚本 jobs.sh ,然后用 ps 命令查看谦让度(NI)为0,bash shell 启动进程的默认谦让度为 0;
然后,为脚本指定谦让度为 8 ,用 ps 命令查看谦让度(NI)为8;
接下来用 nice 不指定谦让度,用 ps 命令查看谦让度(NI)为10。
2. 调整谦让度 - renice命令
有时需要改变正在运行的进程的谦让度,可以使用 renice 命令。格式如下:
renice -n [niceness] -p [PID]
注意,和 nice 不同的是,renice 只能通过 -n 选项指定谦让度, -p选项指定正在运行的进程的ID号。
另外,renice 还有一些限制:
- 只能操作属于你的进程,如想操作其他进程,需要使用root权限。
- 只能提高谦让度,即降低优先级。

3.5.6 定时运行作业
Linux提供了 at 指令和 cron 表来安排脚本的运行时间和频率。
1. at指令
at 指令会将作业提交到队列中,指定shell何时运行该作业。 at 的守护进程 atd 会以后台模式运行,检查作业队列来运行作业。大多数Linux发行版会在启动时运行此守护进程。
atd 守护进程会检查系统上的一个特殊目录(通常位于/var/spool/at)来获取用 at 命令提交的作业。默认情况下, atd 守护进程会每60秒检查一下这个目录(所以at设置时间的最小单位是1分钟)。有作业时, atd 守护进程会检查作业设置运行的时间,如果时间跟当前时间匹配, atd 守护进程就会运行此作业。
at命令格式如下:
at -f filename time
其中,filename 用于指定脚本文件,time 用于指定运行该脚本的时间点,time 的格式如下:
- 24小时制:13:14
- 12小时制,用AM/PM指示上午下午:01:14PM
- 特定的时间名称:now(现在)、noon(中午12:00)、midnight(午夜00:00)、teatime(下午4:00)
- 标准日期格式:MMDDYY、MM/DD/YY、YY-MM-DD或DD.MM.YY
- 特定的日期名称:today、tomorrow
- 英文简写日期:比如 Jul 12、Sep 10
- 指定时间增量:时间+3min(minute/minute)、hour(s)、day(s)、week(s)、month(s)、year(s)
其中有几个规则:
- 对于时间,如果不指定日期,则为当天的时间,如果已错过当天的该时间,则顺延为第二天;年相对与日期同理。
- 对于日期,如果不指定时间,则为当前时间,比如当前时间为13:14,指定日期为Sep 10,则脚本执行时间为13:14 Sep 10
那么,at设置的作业都去哪里了?他们被保存到了作业队列里,针对不同的优先级,有26种作业队列。26这个数字是不是很熟悉呢,没错,就是26个英文字母,这些用这26个英文字母表示,可以是大写也可以是小写,a/A的优先级最高。如不特殊设置,at命令设置的作业默认被保存到a队列,也就是优先级最高的队列。可以使用at的-q选项指定队列。
查看队列中等待的作业:使用 atq 命令,
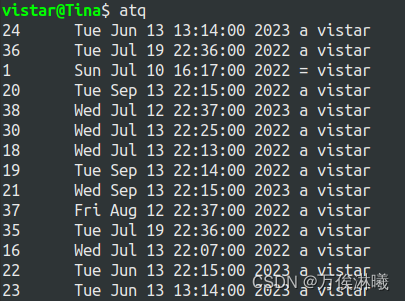
其中,
第一列:作业号
中间几列:日期和时间
倒数第二列:所属队列,其中= 是正在运行的作业队列
最后一列:作业所属用户
可以使用 -q 选项指定所查询的队列:

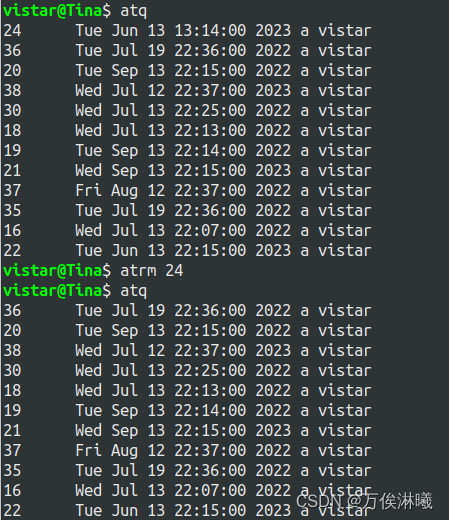
删除作业:atrm 作业号
注意,只能删除当前用户所属的作业,但root用户可以删除其他用户的作业。
2. cron时间表
at命令设置一次,脚本只能执行一次,如果想让脚本周期执行,可以使用cron时间表。
cron程序通过维护一个 cron时间表 来实现作业的周期执行。
cron时间表 格式如下:
min hour dayofmonth month dayofweek command
其中,前5个字段用于设置时间表,可以用特定值、取值范围或通配符(*)来设置时间表。
min 用于指定分钟;
hour 用于指定小时,注意是24小时制;
dayofmonth 用于指定每月的日期;
month 用于指定每年的月份;
dayofweek 用于指定每周的周几,可以使用mon、tue、wed、thu、fri、sat、sun等表示,也可以使用0-6的数值(0代表周日,1-6代表周一到周六);
command 用于设置需要周期执行的命令或脚本,这里注意,脚本必须使用绝对路径。
举几个例子:
# 每天的14:13
13 14 * * * command
# 每周一的早上8点
00 08 * * 1 command
# 每月第一天的午夜零点
00 00 1 * * command
这里有一个问题,由于每月的天数不同,如果想表示每月最后一天,就不能简单的通过dayofmonth设置了。
可以使用以下命令,检查明天是否是每月第一天,如果是,则今天是当月最后一天:
min hour * * * if [ `date +%d -d tomorrow` = 01 ] ; then ; command
其中,min 和 hour 可以自定义。
3. 构建cron时间表
cron 有四个预置的目录:hourly、daily、monthly、weekly,分别是每小时、每天、每月、每周执行一次,可以将需要的脚本放到对应的目录下,他们的具体位置如下:
/etc/cron.daily
/etc/cron.hourly
/etc/cron.monthly
/etc/cron.weekly
如果需要其他的 cron 时间表,可以使用 crontab 命令,他会创建一个cron时间表,其格式如下:
crontab [ -u user ] file
或
crontab [ -u user ] { -l | -r | -e }
其中,
-u user 用来指定用户,不指定用户会默认当前用户;
file 是要执行的脚本文件;
-l 列出当前的cron 时间表;
-r 删除当前的cron 时间表;
-e 编辑 cron 时间表,第一次运行会让你选择默认编辑器。

但还有一个问题,如果在需要执行脚本的时间,Linux机器没有开机怎么办?
Linux提供了anacron命令,如果由于关机错过了执行脚本,在开机后,anacron命令会尽快执行错过的脚本。他通过维护自己的时间表来监测脚本有没有执行,但anacron只会处理cron目录中的脚本,他的时间表格式如下:
period delay identifer command
其中,
period :定义作业多久运行一次,单位:天;
delay :指定系统启动后,要等待多久运行错过的脚本,单位:分钟;
identifer :作业标识符,如指定,则anacron 只考虑所标识的作业,如不指定,考虑所有作业。
command :要执行的shell命令,可以是多条,用空格或制表符分隔。
另外由于anacron程序不会处理执行时间需求小于一天的脚本,所以位于/etc/cron.hourly目录的脚本不会被anacron处理。