GCC��������������
���������
https://mp.weixin.qq.com/s/-MhkY2FLZ3Tn4eWZZrZ2Ww
https://mp.weixin.qq.com/s/BaATGUQJii_YPwXpc5Dzow
https://mp.weixin.qq.com/s/Y3xyHoMmES_skOHgteB41g
https://mp.weixin.qq.com/s/1g4i64UklWybygT4CR5MTA
https://mp.weixin.qq.com/s/8QXCSrGdOrdzIcTa6VG1Hw
https://mp.weixin.qq.com/s/h6NY1aaxzBcws0c28cbrdQ
GCC��װ���
һ.������
linuxһ����Դ��������ȷ�ʽֱ�Ӱ�װgcc,����һ�㲻�����°�,������Ҫ֧��C++11
��ԭ��,����Ҫ��װ���°�gcc��
�Ȳ鿴���е�gcc�汾
witch gcc g++ ��gcc -v ��g+��v
���ϵͳ��û���κ�gcc����װ,����Ҫ�ӿ��������Ȱ�װĬ�ϵĵͰ汾��gcc
centos��Ҳ����װ��gcc�Ŀ�������:yum groupinstall ��Development Tools��
�����Ȱ�װ�ɰ汾�Ļ���װ���ܻ�������´���:
configure: error: no acceptable C compiler found in $PATH
��.��װ
��ֱ�Ӱ�װ��������´���:
configure: error: Building GCC requires GMP 4.2+, MPFR 2.3.1+ and MPC 0.8.0+. Try the --with-gmp, --with-mpfr and/or --with-mpc options to specify their locations.
��Ϊȱ��gcc������gmp��mpfr��mpc����������ͬʱgmp��mpfr��mpc֮�仹���������ϵ,����
Ҫ������˳��װ,���� configure�����ѡ��������������������·��.
1.��ѹ
t
a
r
?
z
x
f
g
c
c
?
10.2.0.
t
a
r
.
g
z
tar -zxf gcc-10.2.0.tar.gz
tar?zxfgcc?10.2.0.tar.gztar -jxvf gmp-4.3.2.tar.bz2
t
a
r
?
j
x
v
f
m
p
f
r
?
3.1.4.
t
a
r
.
b
z
2
tar -jxvf mpfr-3.1.4.tar.bz2
tar?jxvfmpfr?3.1.4.tar.bz2tar -zxf mpc-1.0.3.tar.gz
2.�¼���װĿ¼(root)
mkdir /usr/local/gcc-10.2.0mkdir /usr/local/gmp-4.3.2mkdir /usr/local/mpfr-3.1.4mkdir /usr/local/mpc-1.0.3
3.��װ����
KaTeX parse error: Expected 'EOF', got '#' at position 15: cd gmp-4.3.2 #? gmp��װ·��./configure --prefix=/usr/local/gmp-4.3.2 $make $make check $sudo make install
$cd mpfr-3.1.4 // congfigure������mpfr��װ·����������gmp·�� $./configure --prefix=/usr/local/mpfr-3.1.4 --with-gmp=/usr/local/gmp-4.3.2 $make $make check $sudo make install
$cd mpc-1.0.3 // congfigure������mpc��װ·����������gmp��mpfr·�� $./configure --prefix=/usr/local/mpc-1.0.3 --with-gmp=/usr/local/gmp-4.3.2 --with-mpfr=/usr/local/mpfr-3.1.4 $make $make check KaTeX parse error: Expected 'EOF', got '#' at position 62: ���ȵ�,������Ҫ����һϵ������ #?vi /etc/profile��LD_LIBRARY_PATH:/usr/local/gmp-4.3.2/lib: /usr/local/mpfr-3.1.4/lib:/usr/local/mpc-1.0.3/lib #source /etc/profile //ʹ��������Ч #echo $LD_LIBRARY_PATH //�鿴�����Ƿ�ɹ� /usr/local/gmp-4.3.2/lib:/usr/local/mpfr-3.1.4/lib:/usr/local/mpc-1.0.3/lib //��ʾ�����ʾ�ɹ� #vi /etc/ld.so.conf //�༭����ļ�,��������·�� /usr/local/mpc-1.0.3/lib /usr/local/gmp-4.3.2/lib /usr/local/mpfr-3.1.4/lib $sudo ldconfig
4.��װgcc
c
d
g
c
c
?
4.8.2
cd gcc-4.8.2
cdgcc?4.8.2./configure --prefix=/usr/local/gcc-10.2.0 --enable-threads=posix --disable-checking --disable-multilib --enable-languages=c,c++ --with-gmp=/usr/local/gmp-4.3.2 --with-mpfr=/usr/local/mpfr-3.1.4 --with-mpc=/usr/local/mpc-1.0.3 $make KaTeX parse error: Expected 'EOF', got '#' at position 27: ��nstall 5.����gcc #?vi /etc/profile��PATH:/usr/local/gcc-10.2.0 #source /etc/profile //ʹ��������Ч #rm /usr/bin/gcc //ɾ���ɵ������� #ln -s /usr/local/gcc4.8.2/bin/gcc /usr/bin/gcc //ʹ�°汾���������� //�����ͬ�� #rm /usr/bin/g++ #ln -s /usr/local/gcc-10.2.0/bin/g++ /usr/bin/g++
6.���
�鿴�Ƿ�װ���³ɹ�:
witch gcc g++ ��gcc -v ��g+��v
��.����sudo
��Щ������װʱ�������root�°�װ,��һ���û����п�����ʹ��,����һ������ͨ�û��°�װ,
����õ�sudo��
��һ���û���¼,Ȼ��su �л���root��
chmod 744 /etc/sudoersvi /etc/sudoers
�ҵ� :
root ALL(ALL) ALL
��һ��,����������
һ���û��� ALL(ALL) ALL
����
Ȼ����exit�˳���һ���û��½��а�װ���ɡ�
GCC����ʹ��
����GCC�ĸ����Ƕ��ʽ������GCC�Ļ���ʹ�á�
- GCC����
GCC������:
GCC(GNU Compiler Collection)���� GNU �����ı�����Ա�������GCC֧��C�� C++��Java �ȶ������ԡ�
Ubuntu��ϵͳĬ���Ѿ���װ��GCC������,����ͨ����������鿴ϵͳ��GCC�������İ汾����װ·��:
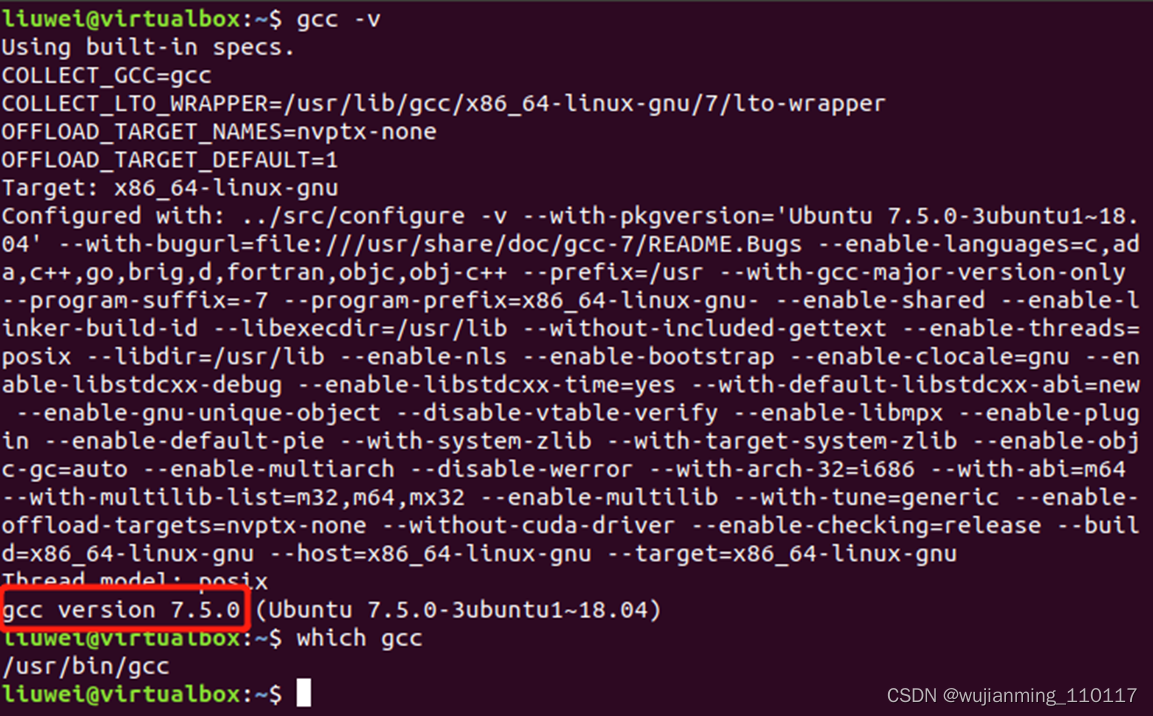
GCC���빤����:
GCC���빤����,��ָ��GCC������Ϊ���ĵ�һ�����ߡ���Ҫ������������������:
? gcc-core:GCC������,��Cת���ɻ�ࡣ
? Binutils :��GCC���������һϵ��С���ߡ�
? glibc:��Ҫ�� C���Ա������⡣
�ںܶೡ���»�ֱ����GCC��������ָ������GCC���빤������
Binutils����:
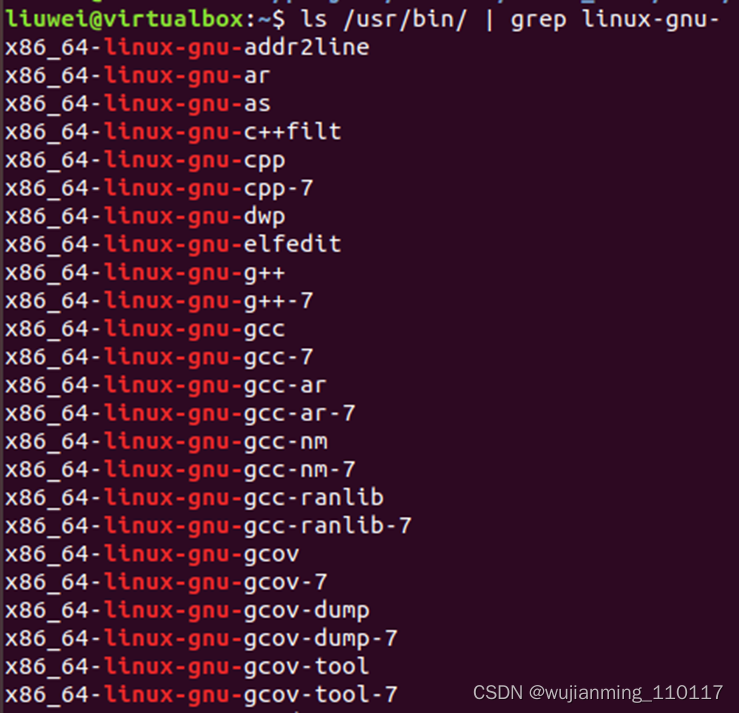
Binutils(bin utility),��GNU�����ƹ���,ͨ����GCC������һ������װ��ϵͳ ��
ϵͳĬ�ϵ�Binutils����λ��/usr/binĿ¼��,��ʹ����������鿴ϵͳ�д��ڵ�Binutils����:
��Ubantu��ִ���������� ls /usr/bin/ | grep linux-gnu-
glibc��:
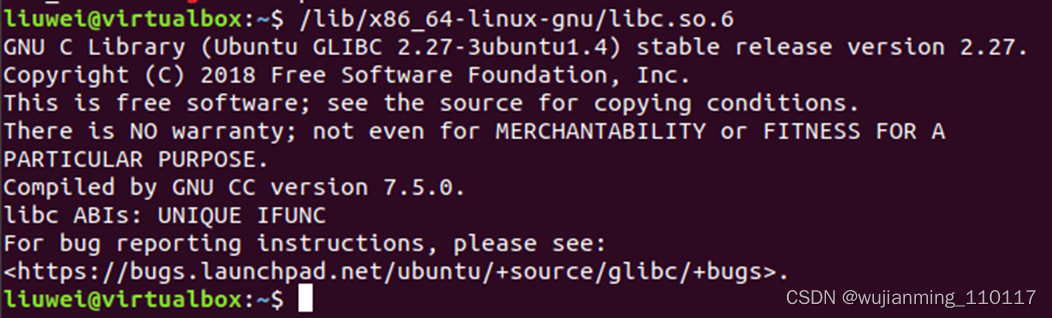
glibc����GNU��֯��д��C���Ա���,����C���������ú����⡣
��Ubuntuϵͳ��,libc.so.6��glibc�Ŀ��ļ�,��ֱ��ִ�иÿ��ļ��鿴�汾:
��Ubantu��ִ���������� /lib/x86_64-linux-gnu/libc.so.6
2. GCC����
��дHelloWorld�ļ�:
#include <stdio.h>int main() { printf(��hello, world! \n��); return 0;}
���벢ִ��:
д�ó�������ֱ�ӽ��б���,ִ����������:
��Ubantu��ִ���������� gcc hello.c �Co hello ls ./hello #ִ�����ɵij���
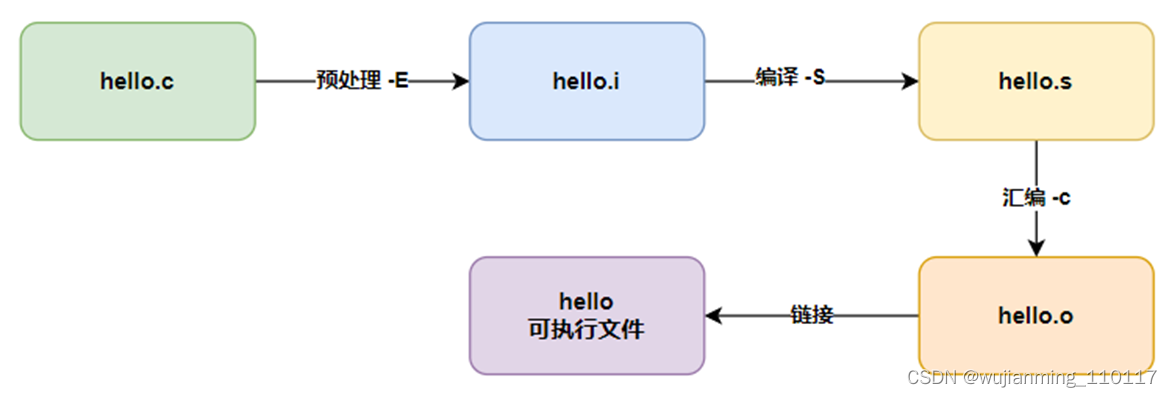
GCC ���빤�����ڱ���һ��CԴ�ļ�ʱ��Ҫ�������� 4 ��:
? Ԥ����
? ����
? ���
? ����
(1)Ԥ������
Ԥ����������,������Ϊ��ͷ�ļ��Ĵ��롢��֮�������ת���ɸ������C����,�������ɵ��ļ���.iΪ����
ʹ��GCC�IJ��� ��-E��,�����ñ��������� .i �ļ�,���� ��-o��,����ָ������ļ������֡�
Ԥ���� gcc �CE hello.c �Co hello.i
�������ɵ�hello.i�ļ���������:
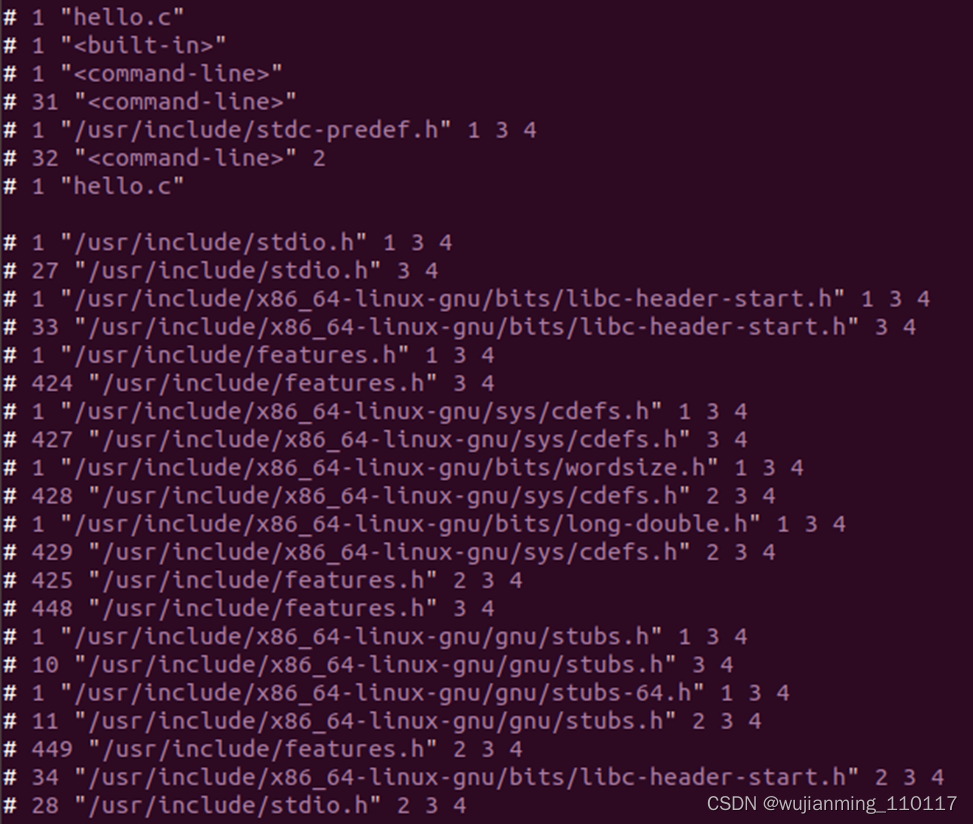
�൱�ڰ�ԭC�����а�����ͷ�ļ������õ����ݻ��ܵ�һ��, ���ԭC�����к궨��,�Ѻ궨��չ���ɾ�������ݡ�
(2)�����
��Ԥ�������.i�ļ�ͨ�������Ϊ�������,����.s�ļ���
GCC����ʹ��-Sѡ��,�ñ���������ɻ�����ԵĴ����ļ�(.s��)��
���� gcc �CS hello.i �Co hello.s # ������������ǵȼ۵� gcc �CS hello.c �Co hello.s
�������ɵ�hello.s�ļ���������:
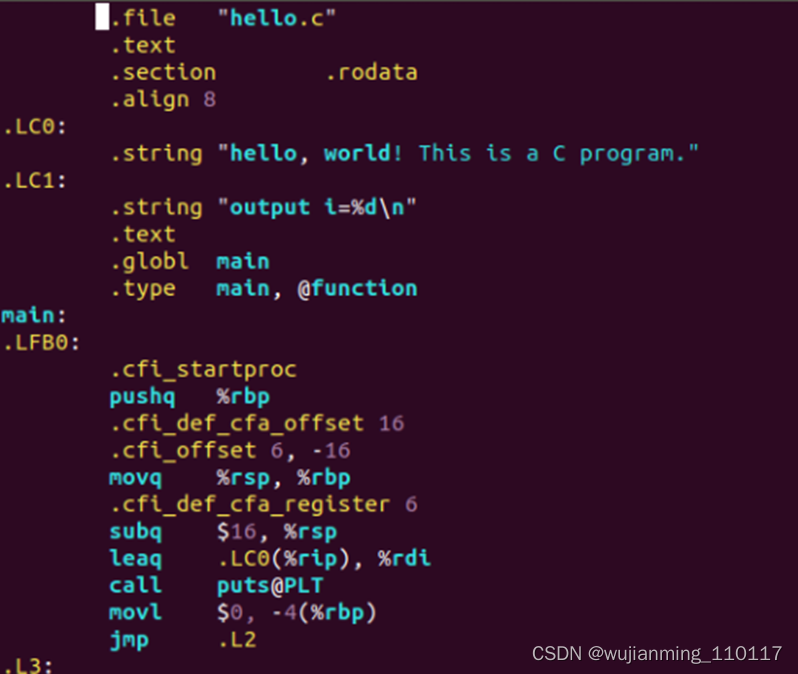
��������Ǹ�ƽ̨��ص�,���ڱ�ʾ����GCCĿ��ƽ̨��x86,���Դ˴����ɵĻ���ļ���x86�Ļ����롣
(3)����
����������ļ��������,����Ŀ���ļ�.o�ļ���
GCC�IJ��� ��c�� ��ʾֻ����(compile)Դ�ļ���������,�ὫԴ��������Ŀ���ļ�(.o��)��
��� gcc �Cc hello.s �Co hello.o # ������������ǵȼ۵� gcc �Cc hello.c �Co hello.o
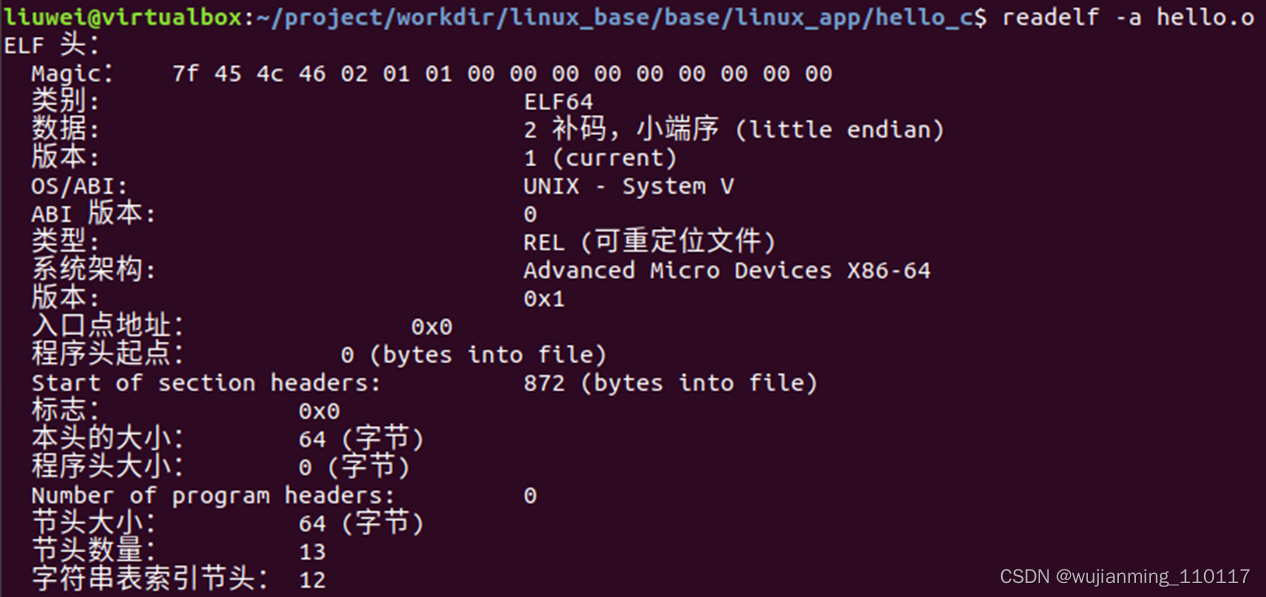
Linux�����ɵ� *.oĿ���ļ���*so��̬���ļ�����elf��ʽ��, ����ʹ�� ��readelf�� �������鿴���ݡ�
(4)���ӽ�
���ÿ��Դ�ļ���Ӧ��Ŀ��.o�ļ���������,������һ����ִ�г����ļ�,����������ld��ɵĹ�����
���ӷ�Ϊ����:
? ��̬����:��̬��ָ��Ӧ�ó�������ʱ��ȥ�����ⲿ�Ĵ����,���Զ�̬�������ɵij���Ƚ�С��
? ��̬����:�ڱ���ξͻ�������õ��Ŀ������Լ��Ŀ�ִ�г�����,���ɵij���Ƚϴ�
ִ�������������龲̬�����붯̬���ӵ�����:
��̬����,������Ϊhello�Ŀ�ִ���ļ� gcc hello.o �Co hello # Ҳ����ֱ��һ������ gcc hello.c -o hello # ��̬����,ʹ�èCstatic���� gcc hello.o �Co hello_static --static # Ҳ����ֱ��һ������ gcc hello.c -o hello_static --static
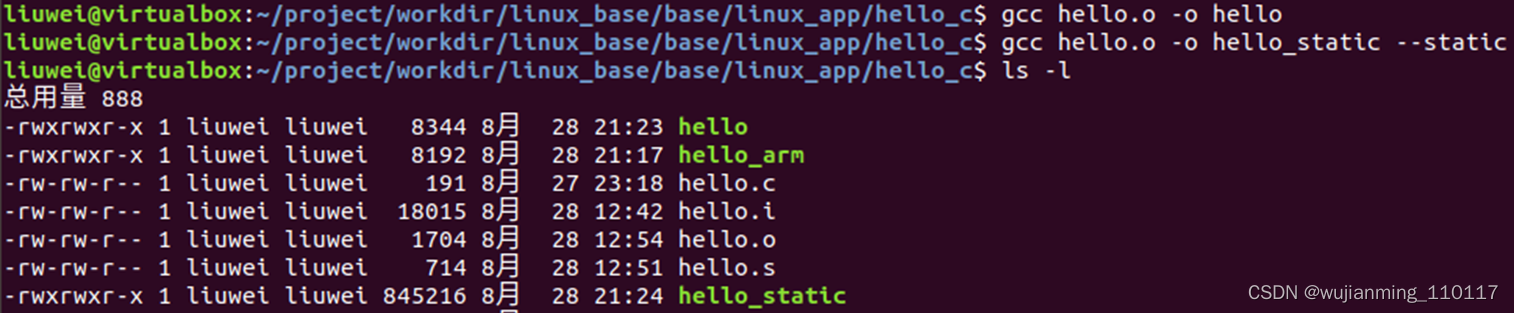
��ͼ�п��Կ���,ʹ�ö�̬�������ɵ�hello�����8.3KB, ��ʹ�þ�̬�������ɵ�hello_static������ߴ�845KB��
��Ubuntu��,����ʹ�� ldd ���߲鿴��̬�ļ��Ŀ�����,����ִ����������:

���Կ���,��̬�������ɵ�hello���������ڿ��ļ�:
linux-vdso.so.1��libc.so.6 �Լ�ld-linux-x86-64.so.2,���е�libc.so.6����C������⡣
��̬�������ɵ�hello_staticû�������ⲿ���ļ���
3. �������
Ƕ��ʽ������һ�������x86�ܹ�ƽ̨��,������ARM��������,���ֱ�������Ŀ����������ڲ�ͬ�ܹ��ı������,����Ϊ ������롣
(1)��װARM-GCC
��������ִ���������� sudo apt install gcc-arm-linux-gnueabihf # ��װ��ɺ�ʹ����������鿴�汾 arm-linux-gnueabihf-gcc �Cv
��װ��ɺ���Բ鿴ARM-GCC������Binutils�ĸ��ֹ���:

(2)����������
����������뱾�ر�����ʹ��������û�ж������
ִ�б�������arm-linux-gnueabihf-gcc hello.c �Co hello_arm
ͬ����C�����ļ�,ʹ�ý�������������,�Ϳ�����ARMƽ̨�����С�
����ͨ��readelf�������鿴����ij�����Ϣ:
�������������������� readelf -a hello_arm
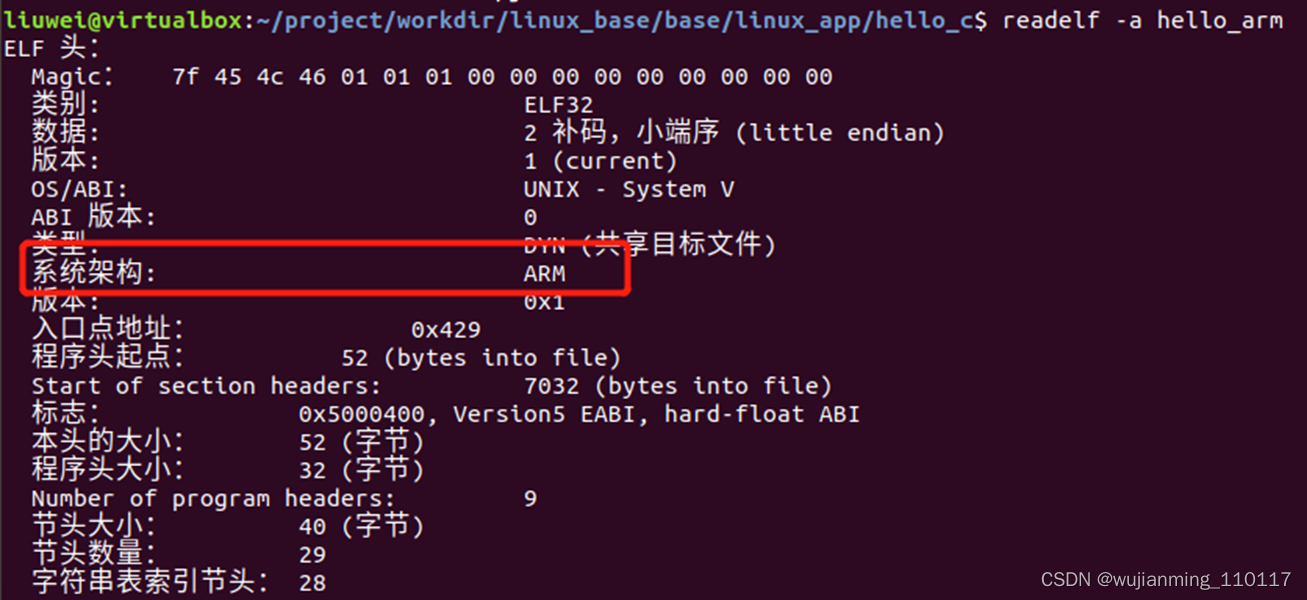
����hello_armͨ��NFS��������������,�����ֶ������ˡ�
(3)GCC������������ʽ
���ϰ�װ����:arm-linux-gnueabihf-gcc������,���������кܶ�汾��:arm-linux-gnueabi-gcc��
��������һ������������:
arch [-os] [-(gnu)eabi(hf)] -gcc
���еĸ��ֶ����±���ʾ:
�ֶ� ����
arch Ŀ��оƬ�ܹ�
os ����ϵͳ
gnu C��������
eabi Ӧ�ö����ƽӿ�
hf ����ģʽ
�� arm-linux-gnueabihf-gcc ��������:
? arm:��ʾĿ��оƬ�ܹ�ΪARM
? linux:Ŀ�����ϵͳΪLinux
? gnu:ʹ��GNU��C���⼴glibc
? eabi:ʹ��Ƕ��ʽӦ�ö����ƽӿ�(eabi)
? hf:�������ĸ���ģʽΪӲ����hard-float
������GCC�ĸ���ͻ���ʹ�á�
���� GCC
һ��GPL �ĵ���ֱ�� 1985 ���� MIT ��������¡�˹����(Richard Stallman)���Ӧ������Դ�뿴�����ͬӵ�е�֪ʶ�Ƹ�,Ӧ�ù��������ɽ�������,����� GNU �ƻ�(��Ӣ������ͬ,GNU �� logo ����һֻţ��),���������������������;ͬʱ,������һ�ݾ������صķ����ļ�,GNU ͨ�ù�����Ȩ��(GNU GPL,GNU General Public License)��
GPL Э��ĺ��ľ���Ҫ��Դ����й���,���������κ�����Դ��,����ֻҪʹ���� GPL Э�������Դ��,����������Ҳ���빫��Դ��,���������Ķ�����Դ��,�� GPL Э����м̳��ԡ�
��һ��������� GPL �������Ǿ����������,������˵������������ָ������Դ������ɻ��������ʹ�á���,���������߲�������ͨ���������շ�,���һ�����ͨ������ GPL ������������
��Ӧ GPL Э�������һ�㶼����������,����������ָһ���������û����ɸ��ơ�ʹ�á��о����ġ��ַ���,���������κ�������������
����,�� GPL �����ǾͿ������ɽ�����������Դ����,��һЭ�鼫����ƶ������������������ҵ�ķ�չ��
����COPYLEFT ��ȨStallman Ϊ��ֹͣ�м��˶���������Ȩ�����ֺ�,����� COPYLEFT ��Ȩ,��Ϊ���������ڷ��������п��ܻ���һЩ����������ͨ���Գ�����Ķ����������˽������,�������� COPYLEFT ��Ȩ�������������а�Ȩ��,��������˷ַ�����,��Щ�����Ƿ���ָ��,ʹ���κ��˶�ӵ�ж���һ�����������κ���һ���������Ʒ��ʹ�á��ĺ����·�����Ȩ��,��ǰ������Щ��������ܱ��ı䡣�����ڷ�����,��������ɾͲ��ɷָ��ˡ�
����GNU��Ŀ
GNU ��Ŀ�ƻ�����ҪĿ���Ǵ���һ������ GNU��s Not Unix(GNU) ����ȫ��ѵIJ���ϵͳ���ò���ϵͳ������������������������������������������,�ԶԿ�������ҵ����,���������ϵͳ�ĺ���(kernel)�ͽ� HURD������ GNU �ڿ�����ȫ��ѵIJ���ϵͳ�ϲ�δȡ�óɹ�,ֱ�� 20 ���� 90 ���������˹�����ɵڿ��ء�������(Linus Benedict Torvalds)������ Linux ����ϵͳ,GNU ��������Ѳ���ϵͳ�������������Ȼ GNU �ƻ��ڿ�������ϵͳ�ϲ��ɹ�,����ȴ�������˺ܶ�ϵͳ������������,�������������� GNU C Complier(gcc)��
�ġ����� GCCGCC ����һ��ı��������ƽ��ִ��Ч��Ҫ�߳� 20%~30%����ʹ����Щ�������������Ĺ�˾��Կ�ͷ,��Ϊ�����Ƴ��� GCC ͬ������,ȴ����ȫ��ѡ�������Դ����ı���������ͬʱ,GCCʹ�õ��� COPYLEFT ��Ȩ����Ȼ,��������������Ļ��Ǽ������е�������������ͨ������ġ�����˵,������������չ�Ļ�ʯ���ˡ���ֹ��2021��8��, GCC ���µ��ͳ��汾�� 11.2 �����ڱ������ܻ�ֱ��Ӱ�쵽 Linux��Firefox��OpenOffice.org��Apache �Լ�һЩ������ĸ��ֿ�Դ��Ŀ�Ŀ�����GCC �������ܷdz�ǿ��,�ṹҲ�쳣����ֵ�óƵ���һ�����,����ͨ����ͬ��ǰ��ģ����֧�ָ�������,�� Java��Fortran��Pascal��Modula-3 �� Ada ���Եȡ�
�塢GCC��������
�Դ�������,GCC �����䡢��չ,���ڲ�����֧�� C ����,��֧�������ܶ�����,���� C++��Objective-C��Fortran��Ada��Go��D�� Java�ȡ����,GCC ����˼�����¶���Ϊ��GNU Compiler Collection��,Ҳ����GUN ������������GUN ����������������ǰ�˴�����,�Է�����ֲ�ͬ���ԡ�GCC Ҳ��һ�ֶ�Ŀ��(multitarget)������;���仰˵,ͨ��ʹ�ÿɻ����ĺ�˴�����,Ϊ���ֲ�ͬ�ļ�����ܹ�������Ӧ�Ŀ�ִ�г�������ģ�黯�������ᳫ��,GCC �ɱ���������ʽ������;Ҳ����˵,����ʹ�� GCC �������豸�����ϵͳ������ִ�г���,����Ҫ�����ڽ��������� GCC ��ƽ̨��Ȼ��,��ô����Ҫ��������úͰ�װ,����� GCC �İ�װ,�����������ϵͳ�������GCC ����֧��C�����ࡰ���ԡ�,Ҳ��������ͬ��C���Ա�;Ҳ����˵,����ʹ��������ѡ�������Ʊ������ڷ���Դ����ʱӦ����ѭ�ĸ�C��������,��ʹ�������в��� -std=c99 ���� GCC ʱ,������֧�� C99 ����GCC �� C11 ����֧���Dz�������,�������漰������ͷ�ļ� threads.h �еĶ��̺߳�����������Ϊ,GCC ��C���ӿⳤ������֧�� POSIX ������ C11 ���dz����ƵĶ��̹߳��ܡ�
����GCC������ʹ��
$ sudo apt install gcc //��װgcc
$ gcc --version //�鿴gcc�汾
$ gedit main.c //��дc
#include <stdio.h>
int main(){ puts(�������demo��); return 0;}
$ gcc -g -o main main.c //����Դ��Ϊ��ִ���ļ�,����g��ʾ���ɵ�����Ϣ,�ó�����Ա�����������,�������Ա���Դ��������Ϣ,���ڵ���,����o��ʾ���
�������-GCC
gcc����ʹ��GNU�Ƴ��Ļ���C/C++�ı�����,�ǿ���Դ��������Ӧ����㷺�ı�����,���й���ǿ��,�������֧�������Ż����ص㡣���ںܶ����Ա��Ӧ��GCC,�������ܸ��õ�Ӧ��GCC��Ŀǰ,GCC������������C/C++��FORTRAN��JAVA��OBJC��ADA�����Եij���,�ɸ�����Ҫѡ��װ֧�ֵ����ԡ�
�
gcc(ѡ��)(����)
ѡ��
-o:ָ�����ɵ�����ļ�;
-E:��ִ�б���Ԥ����;
-S:��C����ת��Ϊ������;
-wall:��ʾ������Ϣ;
-c:��ִ�б������,���������Ӳ�����
����
CԴ�ļ�:ָ��C����Դ�����ļ���
ʵ��
���ñ�������ѡ��
����Դ�����ļ���Ϊtest.c
��ѡ���������
gcc test.c
��test.cԤ��������ࡢ���벢�����γɿ�ִ���ļ�������δָ������ļ�,Ĭ�����Ϊa.out��
ѡ�� -o
gcc test.c -o test
��test.cԤ��������ࡢ���벢�����γɿ�ִ���ļ�test��-oѡ������ָ������ļ����ļ�����
ѡ�� -E
gcc -E test.c -o test.i
��test.cԤ�������test.i�ļ���
ѡ�� -S
gcc -S test.i
��Ԥ��������ļ�test.i����test.s�ļ���
ѡ�� -c
gcc -c test.s
���������ļ�test.s�������test.o�ļ���
��ѡ������
gcc test.o -o test
����������ļ�test.o���ӳ����տ�ִ���ļ�test��
ѡ�� -O
gcc -O1 test.c -o test
ʹ�ñ����Ż�����1���������Ϊ1~3,����Խ���Ż�Ч��Խ��,������ʱ��Խ����
��Դ�ļ��ı��뷽��
����ж��Դ�ļ�,�����������ֱ��뷽��:
����������Դ�ļ�Ϊtest.c��testfun.c
����ļ�һ�����
gcc testfun.c test.c -o test
��testfun.c��test.c�ֱ��������ӳ�test��ִ���ļ���
�ֱ�������Դ�ļ�,֮��Ա���������Ŀ���ļ����ӡ�
gcc -c testfun.c #��testfun.c�����testfun.o
gcc -c test.c #��test.c�����test.o
gcc -o testfun.o test.o -o test #��testfun.o��test.o���ӳ�test
�������ַ�����Ƚ�,��һ�з�������ʱ��Ҫ�����ļ����±���,���ڶ��ַ�������ֻ���±����ĵ��ļ�,δ�ĵ��ļ��������±��롣
����GCC �Ľ���
һ��ʲô��Gcc
Linuxϵͳ�µ�Gcc(GNU C Compiler)��GNU�Ƴ��Ĺ���ǿ��������Խ�Ķ�ƽ̨������,��GNU�Ĵ�����Ʒ֮һ��gcc�ǿ����ڶ���Ӳ��ƽ̨�ϱ������ִ�г���ij���������,��ִ��Ч����һ��ı��������ƽ��Ч��Ҫ��20%~30%��
Gcc�������ܽ�C��C++����Դ�����ʽ�����Ŀ�������롢���ӳɿ�ִ���ļ�,���û�и�����ִ���ļ�������,gcc������һ����Ϊa.out���ļ�����Linuxϵͳ��,��ִ���ļ�û��ͳһ�ĺ�,ϵͳ���ļ������������ֿ�ִ���ļ��Ͳ���ִ���ļ���
����gcc����ѭ�IJ���Լ������
ǰ���ᵽ���˵ĺ�����,��gcc��ͨ���������������ļ������,����������gcc����ѭ�IJ���Լ������
? .cΪ�����ļ�,C����Դ�����ļ�;
? .aΪ�����ļ�,����Ŀ���ļ����ɵĵ������ļ�;
? .C��.cc��.cxxΪ�����ļ�,��C++Դ�����ļ�;
? .hΪ�����ļ�,�dz�����������ͷ�ļ�;
? .iΪ�����ļ�,���Ѿ�Ԥ��������CԴ�����ļ�;
? .iiΪ�����ļ�,���Ѿ�Ԥ��������C++Դ�����ļ�;
? .mΪ�����ļ�,��Objective-CԴ�����ļ�;
? .oΪ�����ļ�,�DZ�����Ŀ���ļ�;
? .sΪ�����ļ�,�ǻ������Դ�����ļ�;
? .SΪ�����ļ�,�Ǿ���Ԥ����Ļ������Դ�����ļ���
����Gcc��ִ�й���
��Ȼ��Gcc��C���Եı�����,��ʹ��gcc��C����Դ�����ļ����ɿ�ִ���ļ��Ĺ��̲������DZ���Ĺ���,����Ҫ�����ĸ�������IJ����Ԥ����(Ҳ��Ԥ����,Preprocessing)������(Compilation)�����(Assembly)������(Linking)��
? ����gcc���ȵ���cpp����Ԥ����,��Ԥ����������,��Դ�����ļ��е��ļ�����(include)��Ԥ�������(��궨��define��)���з�����
? ���ŵ���cc1���б���,����θ��������ļ�������.oΪ����Ŀ���ļ�������������Ի�����ԵIJ���,����as���й���,һ������,.SΪ���Ļ������Դ�����ļ��ͻ�ࡢ.sΪ���Ļ�������ļ�����Ԥ����ͻ��֮��������.oΪ����Ŀ���ļ���
? �����е�Ŀ���ļ�������֮��,gcc�͵���ld��������Ĺؼ��Թ���,����ξ������ӡ������ӽ�,���е�Ŀ���ļ��������ڿ�ִ�г����е�ǡ����λ��,ͬʱ,�ó��������õ��Ŀ⺯��Ҳ�Ӹ������ڵĵ��������������ʵĵط���
�ġ�Gcc�Ļ����÷���ѡ��
��ʹ��Gcc��������ʱ��,�������һϵ�б�Ҫ�ĵ��ò������ļ����ơ�Gcc�������ĵ��ò�����Լ��100���,���ж����������ܸ������ò���,����ֻ�����������������õIJ���
Gcc��������÷��ǡ�gcc[options] [filenames] ,����options���DZ���������Ҫ�IJ���,filenames������ص��ļ����ơ�
�塢Gcc�IJ���ѡ��
-c,ֻ����,�����ӳ�Ϊ��ִ���ļ�,������ֻ���������.c��Դ�����ļ�����.oΪ����Ŀ���ļ�,ͨ�����ڱ��벻������������ӳ����ļ���
-o output_filename,ȷ������ļ�������Ϊoutput_filename,ͬʱ������Ʋ��ܺ�Դ�ļ�ͬ����������������ѡ��,gcc����Ԥ��Ŀ�ִ���ļ�a.out��
-g,�������ŵ��Թ���(GNU��gdb)����Ҫ�ķ�����Ѷ,Ҫ���Դ������е���,�ͱ���������ѡ�
-O,�Գ�������Ż����롢����,�������ѡ��,����Դ������ڱ��롢���ӹ����н����Ż�����,���������Ŀ�ִ���ļ���ִ��Ч�ʿ������,����,���롢���ӵ��ٶȾ���Ӧ��Ҫ��һЩ��
-O2,��-O���õ��Ż����롢����,��Ȼ�������롢���ӹ��̻������
-Idirname,��dirname��ָ����Ŀ¼���뵽����ͷ�ļ�Ŀ¼�б���,����Ԥ���������ʹ�õIJ�����
������ԡ�GCC�������
GCC֧����C/C++������Ƕ�������,��Щ���뱻������"GCC Inline ASM"(GCC�������);
һ�������������
GCC�л������������dz���,��ʽ����:
asm [volatile] (��instruction list��);
����,
1.asm:
��GCC����Ĺؼ���asm�ĺ궨��(#define asm asm),��������һ������������ʽ,����,�κ�һ������������ʽ���Դ˿�ͷ,�DZز����ٵ�;���Ҫ��д����ANSI C���Ĵ���(��:��ANSI C����),�Ǿ�Ҫʹ��__asm__;
2.volatile:
��GCC�ؼ���volatile�ĺ궨��;���ѡ���ǿ�ѡ��;��GCC����"��Ҫ����д��instruction list,��Ҫԭ�ⲻ���ر���ÿһ��ָ��";�����ʹ��__volatile__,��ʹ�����Ż�ѡ��-O�����Ż�����ʱ,GCC��������Լ����ж��������Ƿ��������������ʽ�е�ָ���Ż���;���Ҫ��д����ANSI C���Ĵ���(��:��ANSI C����),�Ǿ�Ҫʹ��__volatile__;
3.instruction list:
�ǻ��ָ���б�;�����ǿ��б�,����:asm volatile(����);��__asm__(����);���ǺϷ�������������ʽ,ֻ�������������ʲô������,û��ʲô����;����������"instruction list"Ϊ�յ�����������ʽ����û�����,����:asm(����:::��memory��);���Ƿdz��������,��GCC����:�����ڴ����˸Ķ���,����,GCC�ڱ����ʱ��,�ͻὫ�����ؿ��ǽ�ȥ;
����:
asm(��movl %esp,%eax��);
������
asm(��movl $1,%eax xor %ebx,%ebx int $0x80��);
������
asm(��movl $1,%eax\n\t��\ ��xor %ebx,%ebx\n\t��\ ��int $0x80��);
instruction list�ı�д����:��ָ���б������ж���ָ��ʱ,������һ��˫������ȫ��д��,Ҳ�ɽ�һ�������ָ�����һ��˫������,����ָ����ڶ��˫������;����ǽ�����ָ��д��һ��˫������,��ô,��������ָ��֮������÷ֺ�";"���з�(\n)����,���ʹ�û��з�(\n),ͨ��\n���滹Ҫ��һ��\t;��������������ָ��ֱ�д��������;
����1:��������ָ��֮��Ҫô���ֺ�(;)���з�(\n)��(\n\t)�ָ���,Ҫô������������;
����2:�����������еķ����ȿ���ͨ��\n��\n\t�ķ�����ʵ��,Ҳ���������ط�������;
����3:����ʹ��1�Ի���˫����,ÿ1��˫����������Է�1�������ָ��,���е�ָ�Ҫ����˫������;
����,��������������䶼�ǺϷ���:
asm(��movl %eax,%ebx sti popl %edi subl %ecx,%ebx��);asm(��movl %eax,%ebx; sti popl %edi; subl %ecx,%ebx��);asm(��movl %eax,%ebx; sti\n\t popl %edi subl %ecx,%ebx��);
�����ָ����ڶ��˫������,��,�������һ��˫����֮��,ǰ�������˫����������һ��ָ����涼Ҫ��һ���ֺ�(;)��(\n)��(\n\t);����,��������������䶼�ǺϷ���:
asm(��movl %eax,%ebx sti\n�� ��popl %edi;�� ��subl %ecx,%bx��);asm(��movl %eax,%ebx; sti\n\t�� ��popl %edi; subl %ecx,%ebx��);asm(��movl %eax,%ebx; sti\n\t popl %edi\n�� ��subl %ecx,%ebx��);
��������C/C++����ʽ���������
GCC����ͨ��C/C++����ʽָ�����������"instruction list"�е�ָ�����������,�������Բ����ĵ���ʹ����Щ�Ĵ���,��ȫ����GCC�����ź�ָ��;��һ������ó���Ա��ȥ�������ļĴ�����ʹ��,Ҳ�������Ŀ������Ч��;
1.����C/C++����ʽ������������ĸ�ʽ:
asm [volatile](��instruction list��:Output:Input:Clobber/Modify);
Բ�����е����ݱ�ð��":����Ϊ�ĸ�����:
A.������IJ��ֵ�"Clobber/Modify"����Ϊ��;���"Clobber/Modify"Ϊ��,����ǰ���ð��(:)����ʡ��;����:���__asm__(��movl %%eax,%%ebx��:��=b"(foo):��a��(inp)😃;�ǷǷ���,�����__asm__(��movl %%eax,%%ebx��:��=b��(foo):��a��(inp));���ǺϷ���;
B.�����һ���ֵ�"instruction list"Ϊ��,��input��output��Clobber/Modify����Ϊ��,Ҳ���Բ�Ϊ��;����,���__asm__(����:::��memory��);�����__asm__(����:😃;���ǺϷ���д��;
C.���Output��Input��Clobber/Modify��Ϊ��,��ô,Output��Input֮ǰ��ð��(:)����ʡ��,Ҳ���Բ�ʡ��;�����ʡ��,��˻����˻�Ϊһ���������,����,��Ȼ��һ������C/C++����ʽ���������,��ʱ"instruction list"�еļĴ�����д��Ҫ��ѭ��ع涨,����:�Ĵ�������ǰ�����ʹ�������ٷֺ�(%%);������������еļĴ�������ǰ��ֻ��һ���ٷֺ�(%);����,���__asm__(��movl %%eax,%%ebx��:😃;asm(��movl %%eax,%%ebx��😃;�����__asm__(��movl %%eax,%%ebx��);������ȷ��д��,�����__asm__(��movl %eax,%ebx��:😃;asm(��movl %eax,%ebx��😃;�����__asm__(��movl %%eax,%%ebx��);���Ǵ����д��;
D.���Input��Clobber/ModifyΪ��,��Output��Ϊ��,��,Inputǰ���ð��(:)����ʡ��,Ҳ���Բ�ʡ��;����,���__asm__(��movl %%eax,%%ebx��:��=b��(foo)😃;�����__asm__(��movl %%eax,%%ebx��:��=b��(foo));������ȷ��;
E.�������IJ��ֲ�Ϊ��,��ǰ��IJ���Ϊ��,��,ǰ���ð��(:)�����뱣��,������˵����Ϊ�յIJ��־����ǵڼ�����;����,Clobber/Modify��OutputΪ��,��Input��Ϊ��,��Clobber/Modifyǰ���ð�ű���ʡ��,��Outputǰ���ð�ű��뱣��;���Clobber/Modify��Ϊ��,��Input��Output��Ϊ��,��Input��Outputǰ���ð�Ŷ����뱣��;����,���__asm__(��movl %%eax,%%ebx��::��a��(foo));��__asm__(��movl %%eax,%%ebx��:::��ebx��);
ע��:������������еļĴ�������ǰ��ֻ����һ���ٷֺ�(%),������C/C++����ʽ����������еļĴ�������ǰ������������ٷֺ�(%%);
2.Output:
Output��������ָ����ǰ��������������,��Ϊ�������ʽ;
��ʽΪ: ������Լ����(�������ʽ)
����:
asm(��movl %%rc0,%1��:��=a��(cr0));
�������е�Output���־���(��=a��(cr0)),��һ����������ʽ,ָ����һ��������������������;
Output�����������������:��˫�����������IJ��ֺ���Բ�����������IJ���,������������һ��Output����������ȱ�ٵIJ���;
��˫�����������IJ��־���C/C++����ʽ,���ڱ��浱ǰ�����������һ�����ֵ,���������C/C++��ֵ���"=������ֵ����,���,Բ������ָ���ı���ʽֻ����C/C++�и�ֵ������ֵ����ʽ,��:���ڵȺ�=��ߵı���ʽ;Ҳ����˵,Output����ֻ����ΪC/C++��ֵ������ߵı���ʽʹ��;
��˫�����������IJ��־�ָ����C/C++�и�ֵ����ʽ����ֵ��Դ;������ֱ�������"����Լ����(Operation Constraint),Ҳ���Գ�Ϊ"���Լ��";����������еIJ���Լ����"=a",�������Լ������������ɲ���:�Ⱥ�(=)����ĸa,����,�Ⱥ�(=)˵��Բ�����еı���ʽcr0��һ��ֻд�ı���ʽ,ֻ�ܱ�������ǰ��������������,��������Ϊ����;��ĸa�ǼĴ���EAX/AX/AL����д,˵��cr0��ֵҪ�ӼĴ���EAX�л�ȡ,Ҳ����˵cr0=eax,������һ�㱻ת���ɻ��ָ�����:movl %eax,address_of_cr0;
ע��:�ܶ��ĵ��ж�����,������������ĵIJ���Լ�����������һ���Ⱥ�(=),����GCC���ĵ���ȴ��ȷ������,�������;��Ϊ�Ⱥ�(=)Լ��˵����ǰ�ı���ʽ��һ��ֻд��,���ǻ�������һ������:�Ӻ�(+),Ҳ��������˵����ǰ����ʽ�ǿɶ���д��;���һ������Լ����û�и��������������е��κ�һ��,��˵����ǰ����ʽ��ֻ����;���,�������������˵,�϶������ǿ�д��,���Ⱥ�(=)�ͼӺ�(+)���ɱ�ʾ��д,ֻ�����Ӻ�(+)ͬʱҲ���Ա�ʾ�ɶ�;����,����һ�����������˵,�����Լ����ֻҪ�����Ⱥ�(=)��Ӻ�(+)�е�����һ���Ϳ�����;
�Ⱥ�(=)��Ӻ�(+)������:�Ⱥ�(=)��ʾ��ǰ����ʽ��һ��������������,���Ӻ�(+)���ʾ��ǰ����ʽ��������һ���������,����һ���������;�������ǵȺ�(=)���ǼӺ�(+),����ʾ�Ķ��ǿ�д,ֻ���������,ֻ�ܳ�����Output����,�����ܳ�����Input����;
��Output���ֿ��Գ��ֶ�������������ʽ,��������������ʽ֮������ö���(,)����;
3��Input:
Input��������ָ����ǰ���������������;��Ϊ�������ʽ;
��ʽΪ: ������Լ����(�������ʽ)
����:
asm(��movl %0,%%db7��::��a��(cpu->db7));
����,����ʽ"a"(cpu->db7)�ͳ�Ϊ�������ʽ,���ڱ�ʾһ���Ե�ǰ������������;
Inputͬ��Ҳ�����������:��˫�����������IJ��ֺ���Բ�����������IJ���;���������ֶ��ڵ�ǰ�����������������˵Ҳ�DZز����ٵ�;
�����������,��˫�����������IJ�����"a",��Բ�����������IJ�����(cpu->db7);
��˫�����������IJ��־���C/C++����ʽ,Ϊ��ǰ�����������ṩһ������ֵ;������,Բ�����еı���ʽcpu->db7��һ��C/C++���Եı���ʽ,��������ֵ����ʽ,Ҳ����˵,���������Ƿ���C/C++��ֵ������ߵı���ʽ,�������Ƿ���C/C++��ֵ�����ұߵı���ʽ;����,Input������һ��������һ������,��������һ�����ӵı���ʽ(��:a+b/c*d);
����,��������������д:
asm(��movl %0,%%db7��::��a��(foo));asm(��movl %0,%%db7��::��a��(0x12345));asm(��movl %0,%%db7��::��a��(va:vb/vc));
��˫�����������IJ��־���C/C++�и�ֵ����ʽ����ֵ����ʽ,����Լ����ǰ�����������еĵ�ǰ����;�������Ҳ��Ϊ"����Լ��",Ҳ���Գ�Ϊ��"����Լ��";���������ʽ�еIJ���Լ����ͬ����,�������ʽ�еIJ���Լ��������ָ���Ⱥ�(=)Լ����Ӻ�(+)Լ��,Ҳ����˵,ֻ����ֻ����;Լ���б���ָ��һ���Ĵ���Լ��;�����е���ĸa��ʾ��ǰ�������cpu->db7Ҫͨ���Ĵ���EAX���뵽��ǰ������������;
��������Լ��:Operation Constraint
����Լ��ֻ������ڴ���C/C++����ʽ��������������;
ÿһ��Input��Output����ʽ������ָ���Լ��IJ���Լ��Operation Constraint;Լ����������:�Ĵ���Լ�����ڴ�Լ����������Լ����ͨ��Լ��;
��������ʽ�ĸ�ʽ:
��Լ����(C/C++����ʽ)
��:��Constraint��(C/C++ expression)
1.�Ĵ���Լ��:
������������Ҫ������һ���Ĵ���ʱ,��ҪΪ��ָ��һ���Ĵ���Լ��;
����ֱ��ָ��һ���Ĵ�������;����:
asm volatile(��movl %0,%%cr0��::��eax��(cr0));
Ҳ����ָ���Ĵ�������д����;����:
asm volatile(��movl %0,%%cr0��::��a��(cr0));
���ָ�����ǼĴ�������д����,����:��ĸa;��ô,GCC������ݵ�ǰ��������ʽ��C/C++����ʽ�Ŀ���������ʹ��%eax��%ax����%al;����:
unsigned short __shrt;asm volatile(��movl %0,%%bx��::��a��(__shrt));
���ڱ���__shrt��16λ��������m��С�������ֽ�,����,��������������Ļ�������,����ô˱���ʹ�üĴ���%ax;
������Input����Output����Լ��,������ʹ�üĴ���Լ��;
���õļĴ���Լ������д:
r:I/O,��ʾʹ��һ��ͨ�üĴ���,��GCC��%eax/%ax/%al��%ebx/%bx/%bl��%ecx/%cx/%cl��%edx/%dx/%dl��ѡȡһ��GCC��Ϊ�Ǻ��ʵ�;
q:I/O,��ʾʹ��һ��ͨ�üĴ���,��r��������ͬ;
g:I/O,��ʾʹ�üĴ������ڴ��ַ;
m:I/O,��ʾʹ���ڴ��ַ;
a:I/O,��ʾʹ��%eax/%ax/%al;
b:I/O,��ʾʹ��%ebx/%bx/%bl;
c:I/O,��ʾʹ��%ecx/%cx/%cl;
d:I/O,��ʾʹ��%edx/%dx/%dl;
D:I/O,��ʾʹ��%edi/%di;
S:I/O,��ʾʹ��%esi/%si;
f:I/O,��ʾʹ�ø���Ĵ���;
t:I/O,��ʾʹ�õ�һ������Ĵ���;
u:I/O,��ʾʹ�õڶ�������Ĵ���;
A:I/O,��ʾ��%eax��%edx��ϳ�һ��64λ������ֵ;
o:I/O,��ʾʹ��һ���ڴ�λ�õ�ƫ����;
V:I/O,��ʾ����ʹ��һ��ֱ���ڴ�λ��;
i:I/O,��ʾʹ��һ���������͵�������;
n:I/O,��ʾʹ��һ��������֪����ֵ��������;
F:I/O,��ʾʹ��һ���������͵�������;
2.�ڴ�Լ��:
���һ��Input/Output��������ʽ��C/C++����ʽ����Ϊһ���ڴ��ַ(ָ�����),����������κμĴ���,�����ʹ���ڴ�Լ��;����:
asm(��lidt %0��:��=m��(idt_addr));��__asm(��lidt %0��::��m��(__idt_addr));
�ڴ�Լ��ʹ��Լ����"m",��ʾ����ʹ��ϵͳ֧�ֵ��κ�һ���ڴ淽ʽ,����Ҫ�����ڼĴ���;
ʹ���ڴ�Լ����ʽ�����������ʱ,���ڲ������ڼĴ���,����,GCC���ᰴ�������������κε������������;GCCֻ��ֱ������ʹ��,�����C/C++����ʽ����,���������뻹�����,��ȫ������д��"instruction list"�е�ָ���������ķ�ʽ;����,���ܰѲ���Լ���Ͳ�������ʽ����Input���ֻ��Ƿ���Output����,GCC�������ɵĻ����붼��һ����,�����ִ�н��Ҳ������ȷ��;������һ����������ʽ����Input��Output������ϣ��GCC��Ϊ�Զ�ͨ���Ĵ���������ʽ��ֵ��������;��Ȼ�����ڴ�Լ�����͵IJ�������ʽ��˵,GCC����Ϊ���κ�����,��ô�������������ν��;���Ǵӳ���Ա�ĽǶ�����,Ϊ����ǿ����Ŀɶ���,����ܹ����ڷ���ʵ������ĵط�;
3.������Լ��:
���һ��Input/Output��������ʽ��C/C++����ʽ��һ�����ֳ���,����������κμĴ������ڴ�,�����ʹ��������Լ��;
������������C/C++����ʽ��ֻ����Ϊ��ֵʹ��,����,����ʹ��������Լ���ı���ʽ����,ֻ�ܷ���Input����;����:
asm volatile(��movl %0,%%eax��::��i��(100));
������Լ��ʹ��Լ����"i"��ʾ�������ʽ��һ���������͵�������,����Ҫ�������κμĴ���,ֻ������Input����;ʹ��Լ����"F"��ʾ�������ʽ��һ�����������͵�������,����Ҫ�������κμĴ���,ֻ������Input����;
4.ͨ��Լ��:
Լ����"g"����������������,��ʾ����ʹ��ͨ�üĴ������ڴ桢���������κ�һ�ִ�����ʽ;
Լ����"0,1,2,3,4,5,6,7,8,9"ֻ����������,��ʾ���n����������ʽʹ����ͬ�ļĴ���/�ڴ�;
ͨ��Լ��"g"��һ���dz�����Լ��,������Ա��Ϊһ��C/C++����ʽ��ʵ�ʲ�����,����ʹ�üĴ�����ʽ���ڴ淽ʽ������������ʽ������νʱ,���߳���Ա��ʵ��һ������ģ��,����GCC���Ը��ݲ�ͬ��C/C++����ʽ���ɲ�ͬ�ķ��ʷ�ʽʱ,�Ϳ���ʹ��ͨ��Լ��g;
����:
#define JUST_MOV(foo) asm(��movl %0,%%eax��::��g��(foo))
��,JUST_MOV(100)��JUST_MOV(var)�ͻ��ñ�����������ͬ�Ļ�����;
����JUST_MOV(100)�Ļ�����Ϊ:
#APP
movl $100,%eax #��������ʽ;
#NO_APP
����JUST_MOV(var)�Ļ�����Ϊ:
#APP
movl 8(%ebp),%eax #�ڴ淽ʽ;
#NO_APP
��������Ч��,����ͨ��Լ��g������;
5.���η�:
�Ⱥ�(=)�ͼӺ�(+)��Ϊ���η�,ֻ������Output����;�Ⱥ�(=)��ʾ��ǰ�������ʽ������Ϊֻд,�Ӻ�(+)��ʾ��ǰ�������ʽ������Ϊ�ɶ���д;���������η�����Լ�����������ʽ�IJ���,����д���������ʽ��Լ��������,����ֻ��д�ڵ�һ���ַ���λ��;
����&Ҳд���������ʽ��Լ������,����Լ���Ĵ����ķ���,����ֻ��д��Լ�����ֵĵڶ����ַ���λ����;
�÷���&��������ʱ,������GCC����:��GCC����Ϊ�κ�Input��������ʽ�������Output��������ʽ��ͬ�ļĴ�����;
��ԭ�������η�&��ζ�ű������ε�Output��������ʽҪ�����е�Input��������ʽ������֮ǰ���;
��:GCC����ʹ�����ֵ�Ա����η�&���ε�Output��������ʽ�������,Ȼ��,�Ŷ�Input��������ʽ��������;
�����Ļ�,�����ʹ�����η�&��Output��������ʽ��������,һ�������Input��������ʽʹ������Output��������ʽ��ͬ�ļĴ���,�ͻ��������������ݻ��ҵ����;�෴,���û�������η�&���������������ʽ,��ô,����ζ��GCC���Ȱ�Input��������ʽ��ֵ���뵽ѡ���ļĴ�����,Ȼ������,���������ֵ����Ӧ��Output��������ʽ;
����,���η�&�����þ���Ҫ��GCC������Ϊ���е�Input��������ʽ�����ļĴ���,����������뱻���η�&���ε�Output��������ʽ��ͬ�ļĴ���;���η�&Ҳд�ڲ���Լ����,��:&Լ��;����GCC�Ѿ��涨�Ӻ�(+)��Ⱥ�(=)ռ��Լ���ĵ�һ���ַ�,��ô&Լ��ֻ��ռ�õڶ����ַ�;
����:
int __out, __in1, __in2;asm(��popl %0\n\t�� ��movl %1,%%esi\n\t�� ��movl %2,%%edi\n\t�� :��=&a��(__out) :��r��(__in1),��r��(__in2));
ע��:���һ��Output��������ʽ�ļĴ���Լ����ָ��Ϊij���Ĵ���,ֻ�е����ٴ���һ��Input��������ʽ�ļĴ���Լ��Ϊ��ѡԼ��(��˼��GCC���ԴӶ���Ĵ�����ѡȡһ��,��ʹ�÷ǼĴ�����ʽ)ʱ,����"r"��"g"ʱ,��Output��������ʽʹ�÷���&���β�������;���Ϊ���е�Input��������ʽָ���˹̶��ļĴ���,��ʹ���ڴ�/������Լ��ʱ,���Output��������ʽʹ�÷���&����û���κ�����;
����:
asm(��popl %0\n\t�� ��movl %1,%esi\n\t�� ��movl %2,%edi\n\t�� :��=&a��(__out) :��m��(__in1),��c��(__in2));
�����е�Output��������ʽ��ȫû�б�Ҫʹ�÷���&������,��Ϊ__in1��__in2���Ѿ���ָ���˹̶��ļĴ���,��ʹ�����ڴ淽ʽ,GCC��ѡ��;
����Ѿ�Ϊij��Output��������ʽָ�������η�&,��ָ���˹̶��ļĴ���,��ô,�Ͳ�����Ϊ�κ�Input��������ʽָ������Ĵ�����,�������ֱ��뱨��;
����:
asm(��popl %0; movl %1,%%esi; movl %2,%%edi;��:��=&a��(__out):��a��(__in1),��c��(__in2));
���������ı���ͻᱨ��;
�෴,Ҳ����ΪOutputָ����ѡԼ��,����"r"��"g"��,��GCCΪ��Output��������ʽѡ����ʵļĴ���,��ʹ���ڴ淽ʽ,GCC��ѡ���ʱ��,���ų����Ѿ���Input��������ʽ��ʹ�ù������мĴ���,Ȼ����ʣ�µļĴ�����ѡ��,���߸ɴ�ʹ���ڴ淽ʽ;
����:
asm(��popl %0; movl %1,%%esi; movl %2,%%edi;��:��=&r��(__out):��a��(__in1),��c��(__in2));
���������η�ֻ������Output��������ʽ��,�����η�%��ǡǡ�෴,ֻ������Input��������ʽ��;
���η�%������GCC����:����ǰInput��������ʽ�е�C/C++����ʽ��������һ��Input��������ʽ�е�C/C++����ʽ������;������η�һ�����ڷ��Ͻ���������ĵط�;����:�ӡ��ˡ���λ��&����λ��|�ȵ�;
����:
asm(��addl %1,%0\n\t��:��=r��(__out):��%r��(__in1),��0��(__in2));
����,��0��(__in2)��ʾʹ�����һ��Input��������ʽ(��r��(__in1))��ͬ�ļĴ������ڴ�;
����ʹ�÷���%����__in1�ļĴ�����ʽr,��ô�ͱ�ʾ,__in1��__in2���Ի���λ��;�ӷ�����������������λ��֮��,�Ͳ���;
���η� I/O ����
= O ��ʾ��Output��������ʽ��ֻд��
-
O ��ʾ��Output��������ʽ�ǿɶ���д��
& O ��ʾ��Output��������ʽ��ռΪ��ָ���ļĴ���
% I ��ʾ��Input��������ʽ�е�C/C++����ʽ��������һ��Input��������ʽ�е�C/C++����ʽ����
�ġ�ռλ��
ÿһ��ռλ����Ӧһ��Input/Output��������ʽ;
��C/C++����ʽ�����������������ռλ��:���ռλ��������ռλ��;
1.���ռλ��:
GCC�涨:һ�����������������ֻ����10��Input/Output��������ʽ,��Щ��������ʽ���ձ��г�����˳�����θ�����0��9;����ռλ���е����ֶ���,����Щ����Ƕ�Ӧ��;����:ռλ��%0��Ӧ���Ϊ0�IJ�������ʽ,ռλ��%1��Ӧ���Ϊ1�IJ�������ʽ,��������;
����ռλ��ǰ��Ҫ��һ���ٷֺ�%,Ϊ��ȥ��ռλ����Ĵ���,GCC�涨:�ڴ���C/C++����ʽ�������������ָ���б����г��ļĴ�������ǰ�����ʹ�������ٷֺ�(%%),һ������ռλ���;
GCC��ռλ�����б����ʱ��,�Ὣÿһ��ռλ���滻Ϊ��Ӧ��Input/Output��������ʽ��ָ���ļĴ���/�ڴ�/������;
����:
asm(��addl %1,%0\n\t��:��=a��(__out):��m��(__in1),��a��(__in2));
��������,%0��ӦOutput��������ʽ"=a"(__out),��"=a"(__out)ָ���ļĴ�����%eax,����,ռλ��%0���滻Ϊ%eax;ռλ��%1��ӦInput��������ʽ"m"(__in1),��"m"(__in1)��ָ��Ϊ�ڴ�,����,ռλ��%1���滻λ__in1���ڴ��ַ;
��һ�仰����:���ռλ������ǰ��������%0��%1��%2��%3��%4��%5��%6��%7��%8��%9;����,ÿһ��ռλ����Ӧһ��Input/Output��C/C++����ʽ;
2.����ռλ��:
����GCC����������ռλ���ĸ������ֻ������10��,��Ҳ��������Input/Output��������ʽ��C/C++����ʽ����������ֻ����10��;�����Ҫ��C/C++����ʽ����������10��,��ô,��Щ��Ҫռλ���Ͳ�������;
GCC��������ṩ������ռλ��������������;��:ʹ��һ�������ַ�����һ��C/C++����ʽ��Ӧ;��������ַ����ͳ�Ϊ����ռλ��;���������ͨ��ʹ����C/C++����ʽ�еı�����ȫ��ͬ������;
ʹ������ռλ��ʱ,��������Input/Output��������ʽ�е�C/C++����ʽ�ĸ�ʽ����:
[name] ��constraint��(����)
��ʱ,ָ���б��е�ռλ������д��ʽ����:
%[name]
�����ʽ�ȼ������ռλ���е�%0,%1,$2�ȵ�;
ʹ������ռλ��ʱ,һ��name��Ӧһ������;
����:
asm(��imull %[value1],%[value2]�� :[value2] ��=r��(data2) :[value1] ��r��(data1),��0��(data2));
������,����ռλ��value1�Ͷ�Ӧ����data1,����ռλ��value2��Ӧ����data2;GCC�����ʱ��,ͬ�����������ռλ���ֱ��滻�ɶ�Ӧ�ı�����ʹ�õļĴ���/�ڴ��ַ/������;����Ҳ��ǿ�˴���Ŀɶ���;
�������,ʹ�����ռλ����д������:
asm(��imull %1,%0�� :��=r��(data2) :��r��(data1),��0��(data2));
�塢�Ĵ���/�ڴ��ı�ʾ(Clobber/Modify)
��ʱ��,����֪ͨGCC��ǰ������������ܻ��ijЩ�Ĵ������ڴ������,ϣ��GCC�ڱ���ʱ�ܹ�����һ�㿼�ǽ�ȥ;��ô�Ϳ�����Clobber/Modify����������Щ�Ĵ������ڴ�;
1.�Ĵ�����֪ͨ:
�������һ�㷢����һ���Ĵ���������ָ���б���,���ֲ���Input/Output��������ʽ��ָ����,Ҳ������һЩInput/Output��������ʽ��ʹ��"r"��"g"Լ��ʱ��GCCѡ���,ͬʱ,�˼Ĵ�����ָ���б��е�ָ������,������Ĵ���ֻ����ǰ����������ʹ�õ����;����:
asm(��movl %0,%%ebx��::��a��(__foo):��bx��);
//���������������,%ebx������ָ���б���,���ұ�ָ������,����ȴδ���κ�Input/Output��������ʽ����ָ��,����,��Ҫ��Clobber/Modify����ָ��"bx",����GCC֪����һ��;
��Ϊ��Input/Output��������ʽ��ָ���ļĴ���,��ΪһЩInput/Output��������ʽʹ��"r"/��g"Լ��,��GCCΪѡ��һ���Ĵ���ʱ,GCC����Щ�Ĵ�����״̬�Ƿdz������,֪����Щ�Ĵ����DZ��ĵ�,��������Ҫ��Clobber/Modify��������;������֮��,GCC��ʣ�µļĴ�������Щ�ᱻ��ǰ����������������һ����֪;����,�������ڵ�ǰ�������ָ��������,��ô�������Clobber/Modify��������,��GCC�����Щ�Ĵ�������Ӧ�Ĵ���;����,�п��ܻ���ɼĴ�����һ��,�Ӷ���ɳ���ִ�д���;
��Clobber/Modify����������Щ�Ĵ����ķ����ܼ�,ֻ��Ҫ���Ĵ�����������˫�����������Ϳ���;���Ҫ��������Ĵ���,�����������Ĵ�������֮���ö��Ÿ���;
����:
asm(��movl %0,%%ebx; popl %%ecx��::��a��(__foo):��bx��,��cx��);
��������,������bx��cx,����GCC:�Ĵ���%ebx��%ecx���ܻᱻ��,Ҫ��GCC�����������;
�Ĵ������ƴ�:
��al��/��ax��/��eax��:�����Ĵ���%eax
��bl��/��bx��/��ebx��:�����Ĵ���%ebx
��cl��/��cx��/��ecx��:�����Ĵ���%ecx
��dl��/��dx��/��edx��:�����Ĵ���%edx
��si��/��esi��:�����Ĵ���%esi
��di��/��edi��:�����Ĵ���%edi
����,ֻ��Ҫʹ��"ax��,��bx��,��cx��,��dx��,��si��,��di"�Ϳ�����,��Ϊ��������Ӧ�ļĴ���;
�����һ�������������Clobber/Modify������GCC������ij���Ĵ����ڴ淢���˸ı�,GCC�ڱ���ʱ,�����������������ļĴ����������ڴ��������֮��Ҫ����ʹ��,��ô,GCC�����Ƚ��˼Ĵ��������ݱ�������,Ȼ���ڴ��������������ش�������֮��,�ٽ������ݻظ�;
������Ҫע�����,�����Clobber/Modify����������һ���Ĵ���,��ô����Ĵ����������ٱ�������ǰ�����������Input/Output��������ʽ�ļĴ���Լ��,���Input/Output��������ʽ�ļĴ���Լ����ָ��Ϊ"r��/��g��,GCCҲ����ѡ���Ѿ���������Clobber/Modify�����еļĴ���;
����:
asm(��movl %0,%%ebx��::��a��(__foo):��ax��,��bx��);
��������е�Input��������ʽ"a"(__foo)���Ѿ�ָ���˼Ĵ���%eax,��ô��Clobber/Modify�����и��г���"ax"���ǷǷ���;����ʱ,GCC�ᱨ��;
2.�ڴ���֪ͨ:
���˼Ĵ��������ݻᱻ��֮��,�ڴ������Ҳ�ᱻ��;���һ�������������ָ���б��е�ָ����ڴ��������,�����ڴ����������ֵĵط�,�ڴ����ݿ��ܷ����ı�,�����ı���ڴ��ַû������Output��������ʽ��ʹ��"m"Լ��,���������,��Ҫʹ����Clobber/Modify����ʹ���ַ���"memory"��GCC����:��������,�ڴ淢����,����ܷ����˸ı䡱;
����:
void* memset(void* s, char c, size_t count){ asm(��cld\n\d�� ��rep\n\t�� ��stosb�� 😕no output/ :��a"?,��D��(s),��c��(count) :��cx��,��di��,��memory��); return s;}
���һ�������������Clobber/Modify���ִ���"memory��,��ôGCC�ᱣ֤�ڴ��������֮ǰ,���ij���ڴ�����ݱ�װ���˼Ĵ���,��ô,������������֮��,�����Ҫʹ������ڴ洦������,�ͻ�ֱ�ӵ�����ڴ洦���¶�ȡ,������ʹ�ñ�����ڼĴ����еĿ���;��Ϊ���ʱ��Ĵ����еĿ����ܿ����Ѿ����ڴ洦�����ݲ�һ����;
3.��־�Ĵ�����֪ͨ:
��һ����������а���Ӱ���־�Ĵ���eflags������,��ôҲ��Ҫ��Clobber/Modify������ʹ��"cc"����GCC������һ��;
���������
https://mp.weixin.qq.com/s/-MhkY2FLZ3Tn4eWZZrZ2Ww
https://mp.weixin.qq.com/s/BaATGUQJii_YPwXpc5Dzow
https://mp.weixin.qq.com/s/Y3xyHoMmES_skOHgteB41g
https://mp.weixin.qq.com/s/1g4i64UklWybygT4CR5MTA
https://mp.weixin.qq.com/s/8QXCSrGdOrdzIcTa6VG1Hw
https://mp.weixin.qq.com/s/h6NY1aaxzBcws0c28cbrdQ