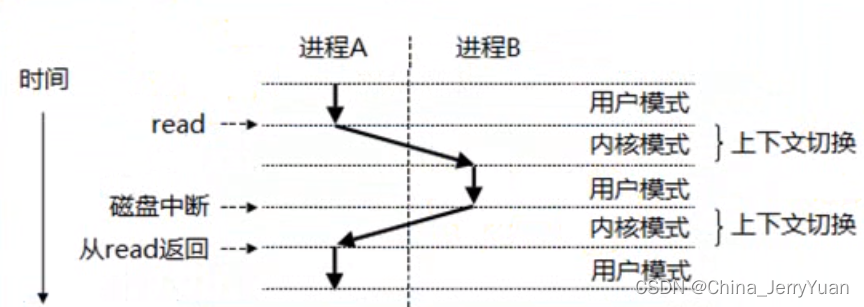
进程A 在用空空间中 执行read 操作时, 程序将陷入到内核空间,此时CPU 向通过地址总线告诉主存操作地址,通过控制总线告诉主存是要读,并且通过DMA 机制将磁盘中的数据搬运到 主存,此时磁盘控制器获取到总线控制权,CPU 不参与数据搬运。为了高效利用CPU linux 内核调度器会将CPU 分配给别的进程,此时CPU 会执行别的进程,直到磁盘控制器将数据由磁盘向主存搬运完毕后,向CPU 发送中断信号,然后CPU 转而又来执行A进程,此时read 返回。 上述过程就产生了进程的上下文切换。
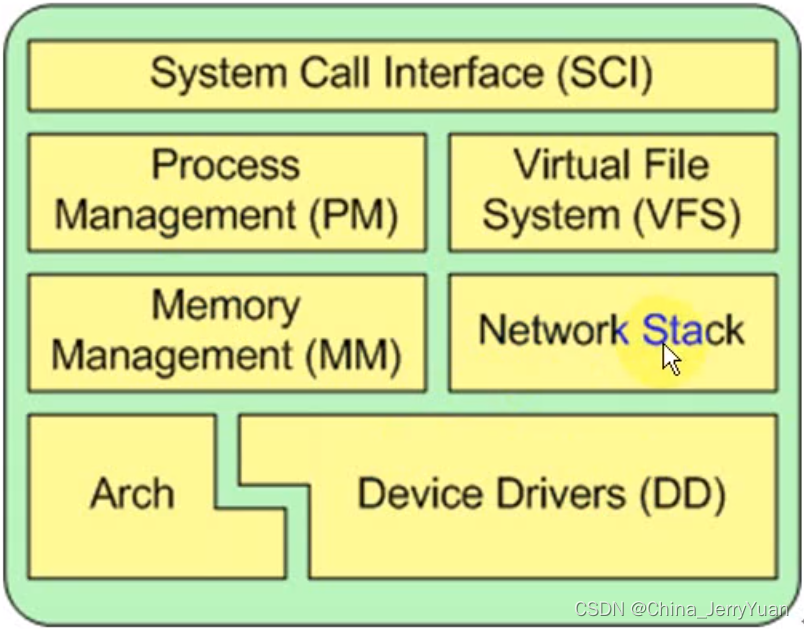
内核模块:
PM 进程管理
VFS 文件系统
MM 内存管理
逻辑地址==》物理地址 段、页。。。
Network stack 网络协议栈
为什么 tcp/ip 协议栈放到linux内核中?
陷入到内核空间的方式:
软件中断 system call
硬件中断 例如 usb控制器中断
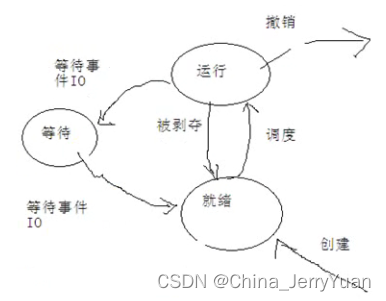
计算机原理中 进程的状态:
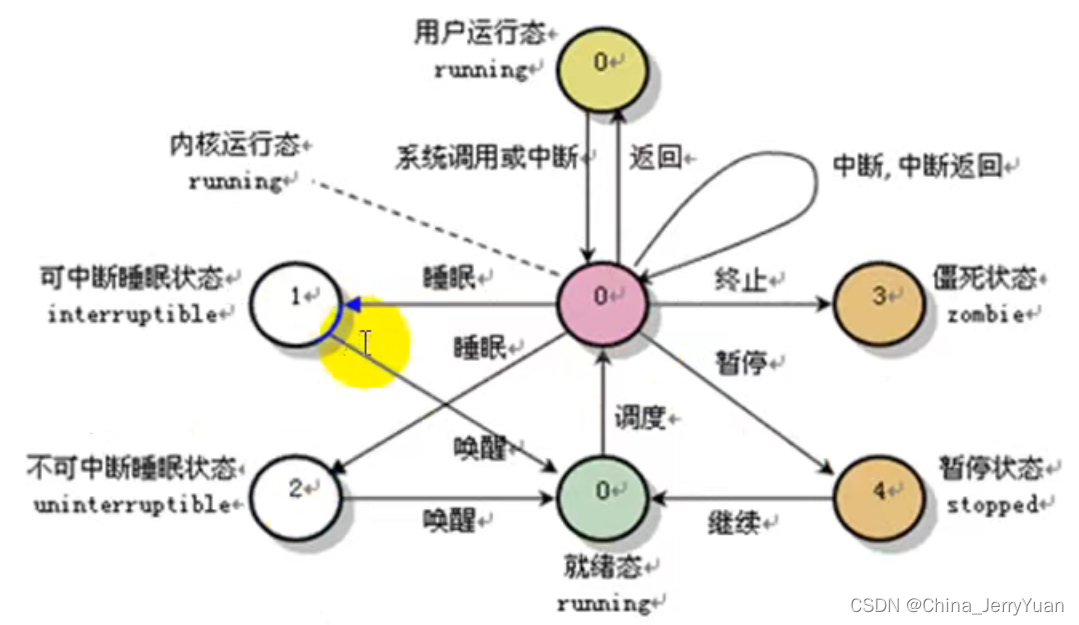
linux 操作系统的实现:
linux 编程:系统开发、系统移植、应用开发
bios===》boot===》 起linux init 进程
linux 的init 进程bin档的位置:
which init
linux 系统支持的最大进程数量:
cat /proc/sys/kernel/pid_max
fork() 函数,一次调用,两次返回,linux 是怎么做到的?
当调用fork()时,陷入到linux 内核中,linux 内核 copy 当前进程的 一个副本放到主存中,并且将进程副本对应的进程放到就绪队列中,这样,就做到了一次调用两次返回,两次放回一个是从当前进程中返回的,另外一个返回是从进程副本中返回的。本质是两个进程从各自的进程空间中返回。
子进程copy 父进程的那些东西?
代码段、堆栈、数据段、PCB(用于linux 内核控制进程)
文件描述符会copy吗? 文件锁会copy 吗?
fork() 调用为什么返回的是子进程的pid号?
目的是便于父进程控制子进程,一个父进程可以fork 多个子进程,哪个它想控制某个子进程就需要知道 子进程的id号,这个id号就是在call fork 函数时获取到的。也就是父进程对子进程是一对多的关系。 而子进程想要知道父进程的id 号,只需要通过getppid() 这个system call 就可以获取到了。
fork() 返回 要么返回 -1,要么返回0, 要么返回 子进程的pid。返回-1 代表进程创建失败了,失败的原因会被写到errno中。 errno 是每个进程默认创建的一个变量。
子进程为什么是从fork() 后的代码段开始执行?
因为copy 进程副本的时候 堆栈段也copy了,堆栈段就决定了子进程从哪里开始执行。