ǰ��
ʲô��Oops?������ѧ�ĽǶ�˵,OopsӦ����һ�������ʡ������˵�С�¹�,�������˱Ƚ����ε���֮��,�����˵"Oops",������й����ͽ��������ϡ���������,�Բ���,�Բ���,���治�ǹ���������ı��ӵġ�����,Oops���������˼��
��Linux�ں˿����е�Oops��ʲô��?��ʵ,��������Ľ���Ҳûʲô���ʵIJ��,ֻ����˵�������DZ����Linux����ijЩ�Ƚ��������������ʱ,���ǵ�Linux�ں�Ҳ�ᱧǸ�Ķ�����˵:������(Oops),�Բ���,�Ұ���������ˡ���Linux�ں��ڷ���kernel panicʱ���ӡ��Oops��Ϣ,��Ŀǰ�ļĴ���״̬����ջ���ݡ��Լ�������Call trace��show�����ǿ�,�����Ϳ��������Ƕ�λ����
1. Oops�IJ���
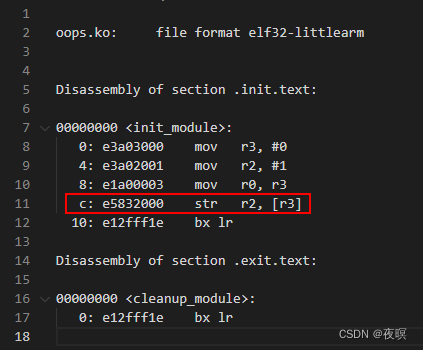
��ѡһλ��������ں�,insmod oops.ko�������±���ӡ,������һ������ͼ��ӡ:
Oops ��Ϣ�������¼���������:
- һ���ı�������Ϣ��
�������ơ�Unable to handle kernel NULL pointer dereference at virtual address 00000000������Ϣ,��˵���˷�������������� - Oops ��Ϣ�����
�����ǵ� 1 �Ρ��� 2 �εȡ���Щ��Ϣ����������,�������ڵ����ݱ�ʾ��š�
Internal error: Oops: 817 [#1] PREEMPT SMP ARM - �ں��м��ص�ģ������(Ҳ����û��),������������ͷ
Modules linked in:xxx - ��������� CPU �����,���ڵ���������ϵͳ,���Ϊ 0
CPU: 1 PID: 1412 Comm: insmod Tainted: P O 4.9.37 #1
��ͼ�ǹ���Tainted(��Ⱦ)�����ֶξ��庬��(����ע�,��3���ּ��ص�ģ�������Щģ�����(PO)������,ʵ���Ͼ��Ǻ���������ͬ�ĺ���),Դ��·��: \kernel\panic.c
/**
* print_tainted - return a string to represent the kernel taint state.
*
* 'P' - Proprietary module has been loaded.(û��ģ��MODULE_LICENSE���ߴ���insmod��Ϊ����GPL�����ݵĵ�MODULE_LICENSE��ģ�鱻�϶���ר�е�)
* 'F' - Module has been forcibly loaded.(ͨ����insmod -f����ǿ��װ�ص�ģ��)
* 'S' - SMP with CPUs not designed for SMP.(oops������SMP�ں���,������û��֤����ȫ���жദ������Ӳ���� ��ǰ������������ڼ��ֲ�֧��SMP�Ĵ�����)
* 'R' - User forced a module unload.(rmmod �Cfǿ��ж��)
* 'M' - System experienced a machine check exception.(��������쳣)
* 'B' - System has hit bad_page.(ҳ�ͷź���������һ�������ҳ���û���һЩ��Ԥ�ڵ�ҳ��־)
* 'U' - Userspace-defined naughtiness.
* 'D' - Kernel has oopsed before.(�ں���ǰ�Ѿ�OOPS����)
* 'A' - ACPI table overridden.
* 'W' - Taint on warning.
* 'C' - modules from drivers/staging are loaded.
* 'I' - Working around severe firmware bug.
* 'O' - Out-of-tree module has been loaded.(����ģ�����)
* 'E' - Unsigned module has been loaded.(δǩ��ģ�����)
* 'L' - A soft lockup has previously occurred.(������������)
* 'K' - Kernel has been live patched.
*
* The string is overwritten by the next call to print_tainted().
*/
-
��������ʱ CPU �ĸ����Ĵ���ֵ
-
��ǰ���̵����ּ����� ID
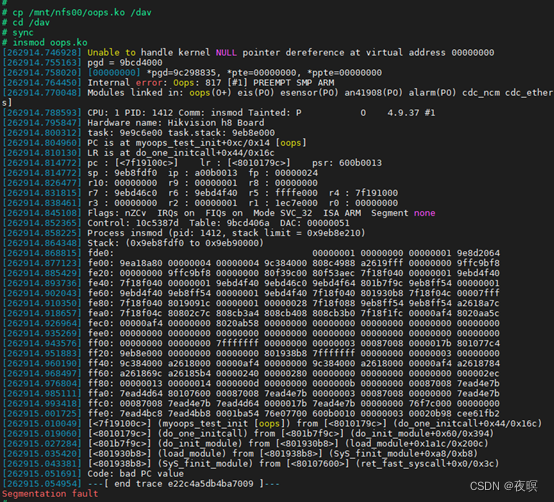
Process insmod (pid: 1412, stack limit = 0x9eb8e210)
�Ⲣ����˵������������������,���DZ�ʾ��������ʱ,��ǰ����������������ܷ������ں˴��롢��������,Ҳ���ܾ���������̵Ĵ��� -
ջ��Ϣ
-
ջ������Ϣ,���Դ��п����������ù�ϵ
-
����ָ�����ָ��Ļ�����(����ָ����С������),Ҳ�п���û��

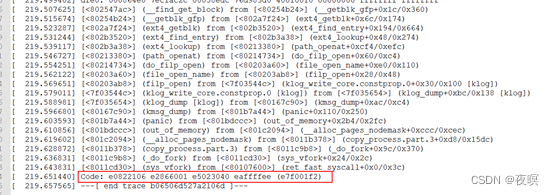
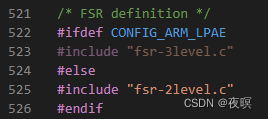
���ڴ�����,����Ϊarmv7�ܹ������FSR(����״̬�Ĵ���,��ΪDFSR��IFSR,���ݲ�ͬ������ʹ�ò�ͬ��FSR)�Ĵ������,ʵ����Դ����,oops�Ĵ��������ͨ������ȡ�ļĴ���ֵ,����Ϊ�ֲ���IFSR��ȡ������ķ���(DFSRͬ��)

����ΪDFSR�ṹ(IFSR����FS������ͬ��)
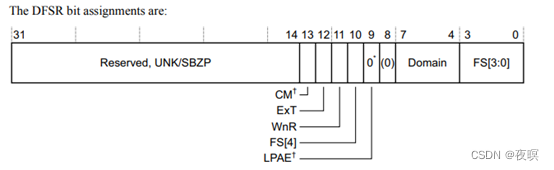
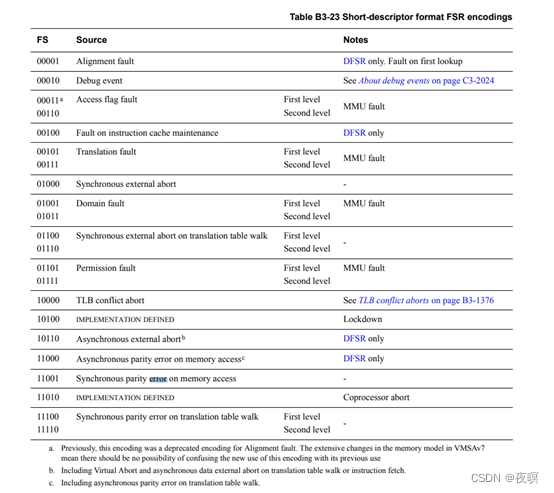
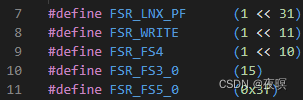
��������0x817�Ĵ��������Ϊ:д���ڴ�ʱ����,����ԭ����:Translation fault Ҳ����ҳ��ת����������
���Ͽ��Դ���֪��Oops ���Կ������ں˼���Segmentation Fault��Ӧ�ó�����������˷Ƿ��ڴ���ʻ�ִ���˷Ƿ�ָ��,��õ�Segfault�ź�,һ�����Ϊ��coredump,Ӧ�ó���Ҳ�����Լ��ػ� Segfault�ź�,���д���������ں��Լ����������Ĵ���,�����Oops��Ϣ,Ҳ����˵Oopsһ���������ڴ�ԭ���µġ�
2.Դ�����
2.1 ��Դ����C����
ֱ��ͨ����ӡ�ҵ������Ķ�Ӧ����,oops�Ĵ�ӡΪ__die����(\arch\arm\kernel\traps.c)��
��265�д�ӡ����oops��Ϣ,��������ַ��������������뿪��,�ֱ��ʾ������ռ,֧�ֶԳƶദ����,����ARMָ�
��269�к���,��עҲд������ʹ�������ARM�ϼ���û������
��273��,��ӡ���ص�ģ����Ϣ
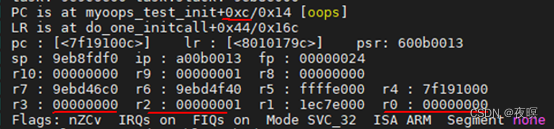
��274��,��ӡ�Ĵ�����Ϣ(CPU��,������,��Ⱦԭ��,PC,LR(���ӼĴ���,���溯�����صĵ�ַ),SP(ջָ��),IP,FP(ջ��ָ��),R10-R0�ȼĴ���ֵ,CPU��Flags (Flags��ߴ�д��ĸ��ʾ��Ӧ��λΪ1,Сд��ʾΪ0)��ָNZCV�⼸��״̬�Ĵ�����)
��275��,��ӡ�˵�ǰ�����Ľ�����,pidֵ,�Ͷ�ջ����,��ARMƽ̨ջ�����������ǴӸߵ�ַ��͵�ַ,spָ���ǵ�ǰ��ջ��,stack limit��ӡ����ջ������,��ʾ��С��ַ�Ƕ���,���SP�����ֵС,��ô��ʾջ����ˡ�
��279��֮���ӡ��ջ�ͺ����ĵ��û��ݡ�
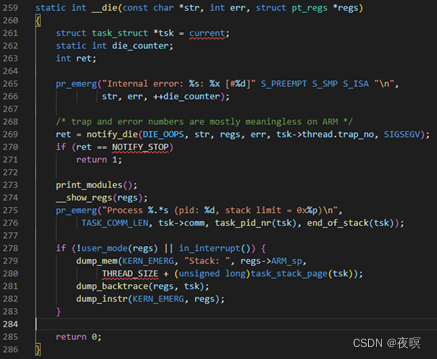
����Ϊpt_reg�Ķ���
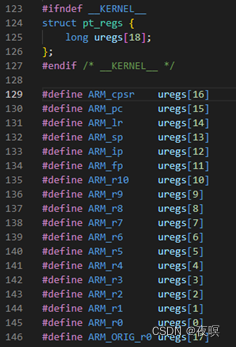
��һ����Դ,����̽��oopsԴ��,����__die�ĺ���Ϊdie(\arch\arm\kernel\traps.c):
��344��:����oops_begin,������ط��رձ�CPU�ж�,��ȡCPUID, ��oops����.���ͬһ��CPU�Ѿ��ڴ���die��,��ô����Ƕ��die,����Ҫ�ٻ�ȡ����
��347�л�ȡcpu�Dz��Ǵ����û�ģʽ,��������û�ģʽ����report_bug�ķ���ֵ���������BUG_TRAP_TYPE_NONE��ӡ���Ϊ��Oops - BUG��,������������,�ͱȽ�����,һ����ӡ����

��355��:die������ǵ���oops_end,����ߵIJ����ܶ��Ǻ�oops_begin���Ӧ��,Ȼ�����oops_exit,�ú������ӡtrace������־,����kmsg_dump(KMSG_DUMP_OOPS)���������oops�������жϹ�����,oops_end������ֱ�Ӳ���panic����������ú�CONFIG_PANIC_ON_OOPS_VALUE��ֵΪ1(panic_on_oops),��Ҳ��ֱ��panic
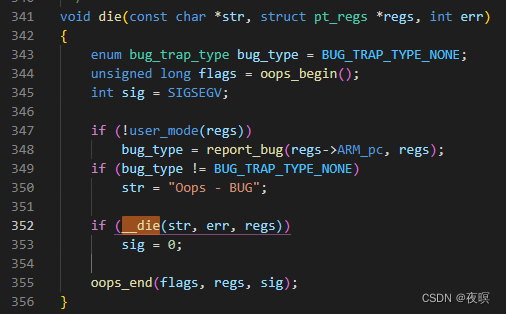
ͨ��������ڿ�ָ����ߴ���������ַ���µ�oops,����Ϊ:__do_kernel_fault��Դ��λ��\arch\arm\mm\fault.c
��138��:���Խ����쳣��,������һ�ܸ��ӵ��ڴ��쳣�ظ�����,������,ʧ�ܺ���������ִ��
��152��:ִ����ǰ���die������,ֱ�Ӹɵ�������Ľ���
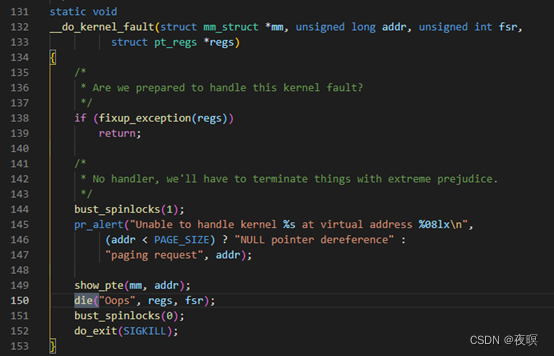
������Դ,�����ҵ���\arch\arm\mm\fault.c�з��������������е���__do_kernel_fault���ֱ���do_bad_area��do_page_fault,�����Ȳ����������Դ��,������Դ
����do_bad_area�����������º���:do_alignment,do_translation_fault,do_sect_fault
����do_page_fault��������:do_translation_fault
�����ջ��ܳ����¸�����
�����ɺ���do_DataAbort����
2.2��Դ���̻�ಿ��
���²���Ϊ������,�����漰�������ڴ��������̡�
���ں������ڴ�ʱ,�����ڴ�ӳ�䵽ʵ�������ڴ�,ϵͳ�Զ�����ȱҳ�ж�,ȱҳ�жϻ��Ƹ���������ҳ���״̬����������ҳ�沢����ӳ���ϵ������ȱҳ�жϵ���������� , ��һ,��������˷Ƿ���ַ(������Ҫ������);�ڶ�,���ʵĵ�ַ�ǺϷ���,���Ǹõ�ַ��δ��������ҳ��
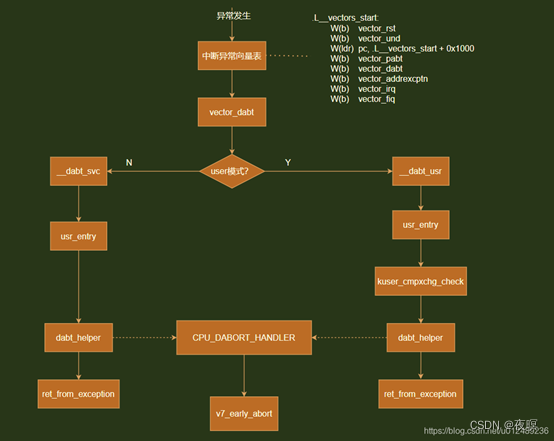
��������ʵ�����ҳ��û�н��й�����ҳ���ӳ��ʱ,��ͨ������ȱҳ�ж��������ӳ������ҳ�档����ȱҳ�ж�ʱ,����������ת���쳣������ Data abort �����п�ʼִ��ȱҳ�жϵĻ���,������봦�����ܹ�������ϵ,�������ARMv7-A�ܹ�,��ദ������Ϊ:__vectors_start -> vector_dabt -> __dabt_usr/__dabt_svc -> dabt_helper -> v7_early_abort
����Ϊ�ж�������,Դ��λ��:arch\arm\kernel\entry-armv.S
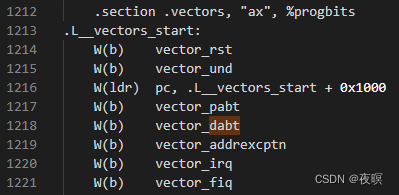
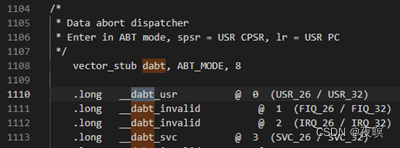
��svc��,�����dabt_helper
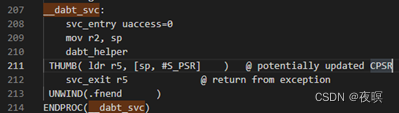
���dabt_helper��bl��CPU_DABORT_HANDLER���������,����ʹ�õļܹ���ͬ,�ú���ʹ�õĿ��ܻ��ͬ
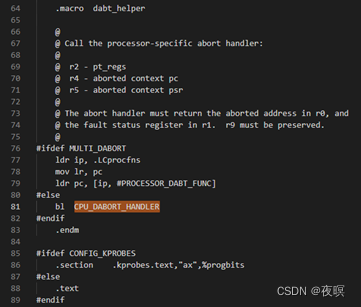
����ʹ�õ�v7�ܹ�,ʹ�ú���Ϊv7_early_abort
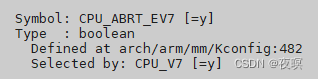
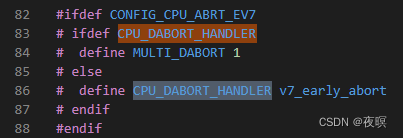
v7_early_abortԴ��λ��:\arch\arm\mm\abort-ev7.S
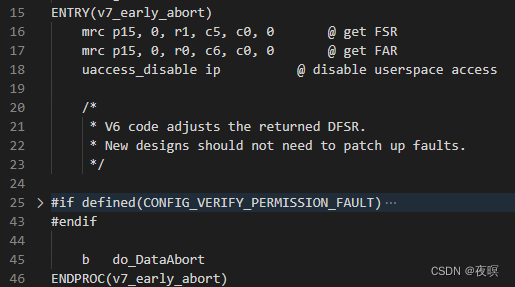
�������ʵ���Ͼ���ʵ���˴�arm�л�ȡFSR(����״̬�Ĵ���)��FAR(�����ַ�Ĵ���,Ҳ����Ҫӳ��ĵ�ַ),r0=��ַ,ri=������,r2=pt_regs(�ڶ�Ӧ��__dabt_svc���Ѿ���ȡ)
2.3 do_DataAbort�ĺ���ע��
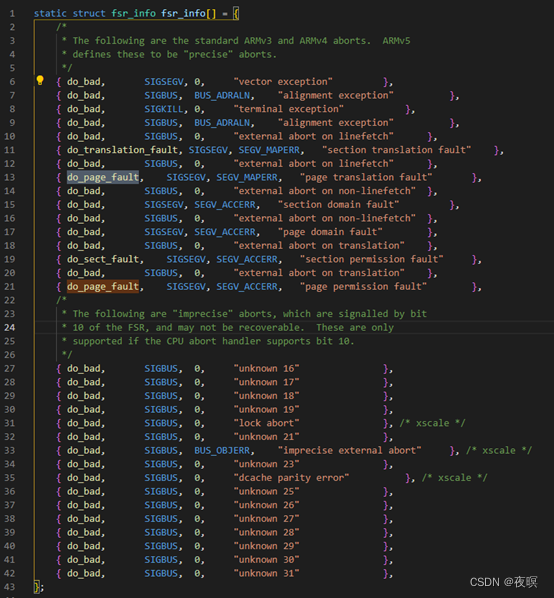
��2.1��2.2�ֱ��C���ֺͻ�ಿ�ֽ��мķ���,��������һ��do_DataAbort�����ʶ��ͬ��ҳ������
���º���Ϊ��fsr_info�����ע�ắ��,��Ϊdo_DataAbortʵ���Ͼ��Ǹ���fsr_info���������к������õ�
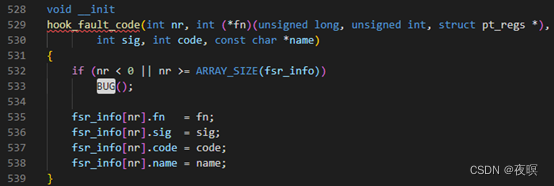
ȫ������hook_fault_code���Է�������:ʵ����Ҳ���Ƕ�fsr_info���鲹���˶δ���ĺ����ص�
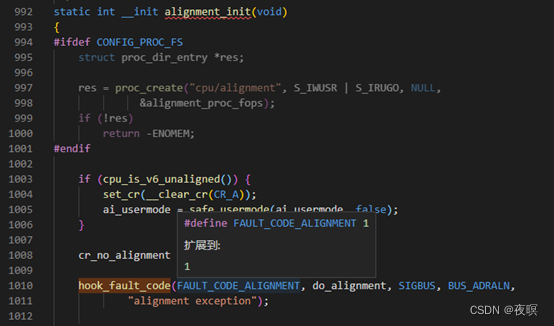
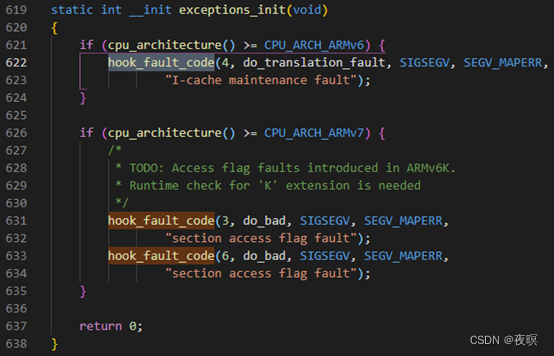
Ҳ����˵,������ֻҪ����fsr_info�������������з���,����֪��oops��ȫ������ԭ����
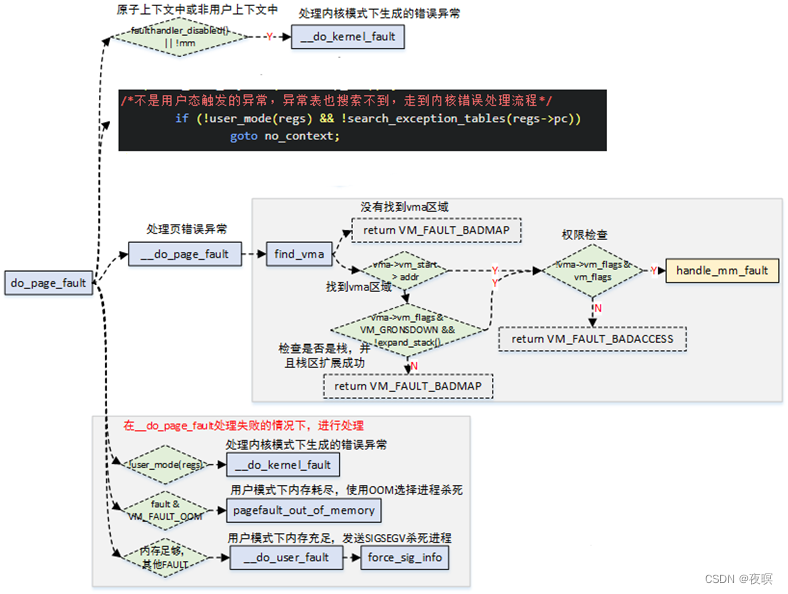
2.4 ������ͼ
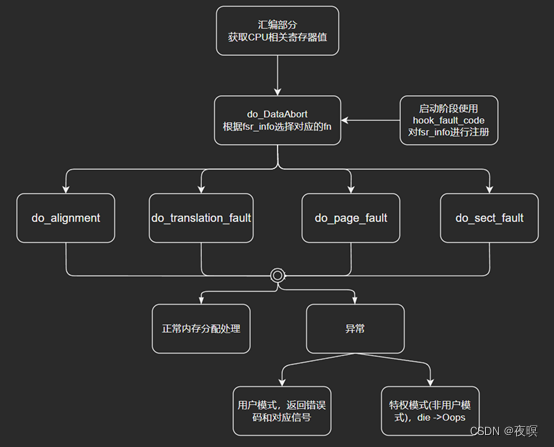
3.oops����ԭ�����
���±�,Ϊ���ܵ�frs_info,��������,ҳ��ת��,ҳ,��Ȩ��
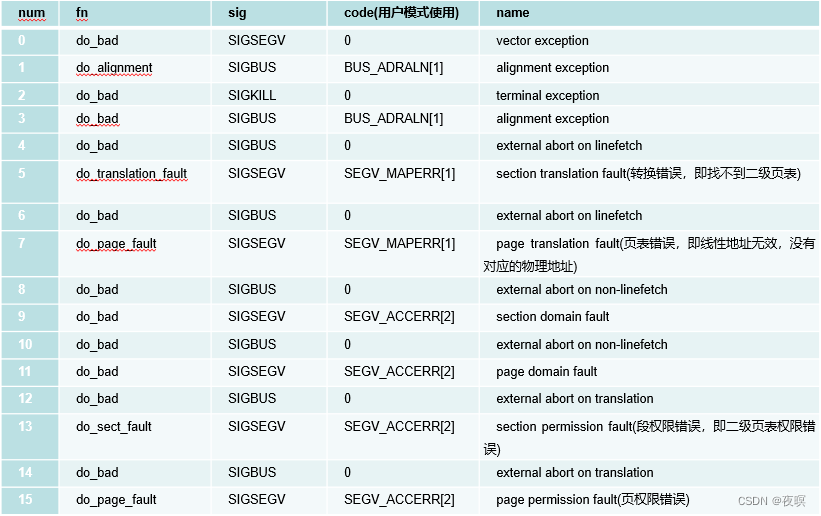
���Ǽ�����Դ����з���������ͼΪdo_DataAbort�����ж�fsr�Ĵ�����ȡ���ݵĴ�����Ҳ���Ƕ�fsr�Ĵ���ȡfs,��Ϊfs�ֲ�Ϊfs[3:0]λ��bit3:0,fs[4]λ��bit10,���Դ������fsr_info����ֱ�Ӳ������
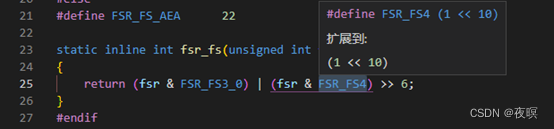
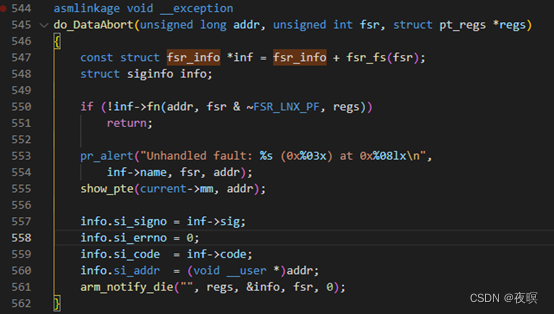
��547�����Ϸ���
��550��ִ�б��ж�Ӧ����,ֻ��do_bad�᷵��1,���ຯ���Է���0.
��561��,ִ������do_bad��Ӧ��fsr���µĴ���,arm_notify_die���жϵ�ǰCPU�Ƿ����û�̬,���������ִ��die
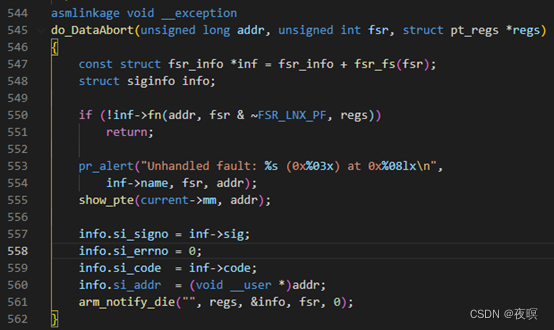
3.1 do_translation_fault
static int __kprobes
do_translation_fault(unsigned long addr, unsigned int fsr,
struct pt_regs *regs)
{
/* ���� */
#define TASK_SIZE (UL(CONFIG_PAGE_OFFSET) - UL(SZ_16M))
/* ������û��ռ�ĵ�ַ,��do_page_fault���� */
if (addr < TASK_SIZE)
return do_page_fault(addr, fsr, regs);
/* ���˵ĵ�ַ�����ں˿ռ�,���regs��ʽΪ�û��ռ䡣˵�����߳�ͻ,����bad_area */
if (user_mode(regs))
goto bad_area;
/* �м��Թ�һ���ִ��� */
return 0;
bad_area:
do_bad_area(addr, fsr, regs);
return 0;
}
����ͼΪdo_bad_areaԴ��
��195�ж��Ƿ����û�ģʽ,������Ǿ�Oops
3.2 do_page_fault
ֱ�ӿ���ͼ���̼���,�����о������,��֮�ڴ��ڷ��û�ģʽ��ȱҳ�Ҵ������ִ���,��ִ��__do_kernel_fault������:do_page_fault���������������ҳ����乤��,����ջ��չ��mmap��֧�ֵ�Ҳ���������������ҳ��ķ���,����õ�do_anonymous_page->������-> __rmqueue,__rmqueue��ʵ��������ҳ�����Ļ���㷨
3.3 do_sect_fault
Դ������,һ������,ֱ��do_bad_area

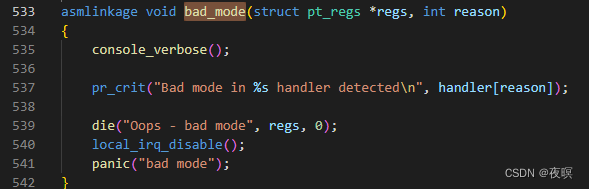
3.4 bad_mode
bad_mode(�ж��쳣)Ҳ���Ե���die��������ֱ��panic,Դ������
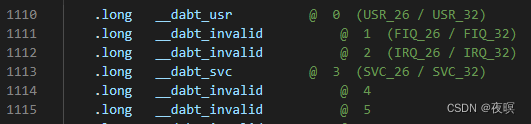
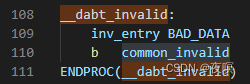
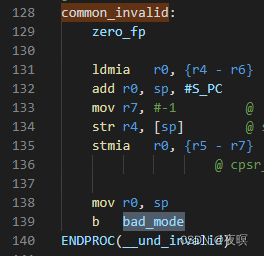
��������:xx�ж��쳣 -> xx_invalid -> common_invalid -> bad_mode
3.5�ܽ�

4. Oops�Ľ��˼·
1.�ȿ��Ƿ���BUG/BUG_ON����,�����BUG�����,��ֱ�ӿ���������,���־�������������
2.�������,����Ը���Oops�ֳ���ӡ��һ�����������Ǽ������ڵ�һ���в�����Oops��Ϣ������ͼ������ֱ�ӿ����˴���ԭ��,��ָ�������,Ȼ��������0x817:��д�ڴ�ʱ,ȱҳ,ӳ��ʧ�ܡ�������ֱ�ӿ�PCָ�������
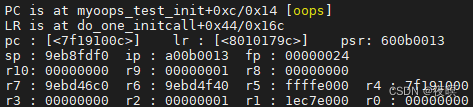
3.PC is at myoops_test_init +0xc/0x14 ȷ���˳�����ĺ���λ��,Ȼ��һ�³���������insmod Ҳ����˵������insmod oops.ko����ʱ��������⡣��������Ҫ�Ըý������ӵ�����Ϣ,�Թ������ܹ��ҵ�����λ��
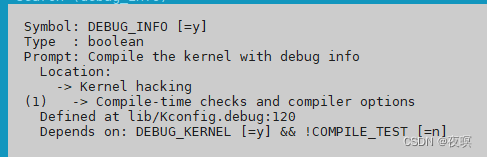
4.���� �Cg����ѡ��,����ͼ�����file����stripped,˵��makefile���߽ű��д���ѡ��,������ʱ���μ��ɡ�
5.�����ں����ӵ�����Ϣ,ֱ������debug_info,�������
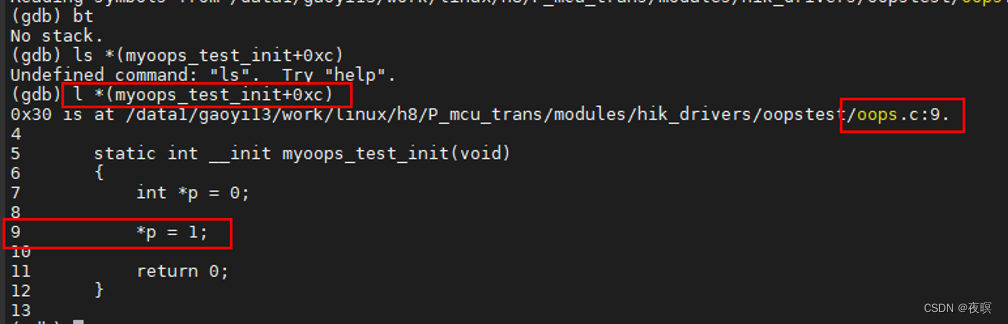
6.ʹ�ö�Ӧ��������gbd��λ����Դ������λ��
�鿴����(Ĭ����ʾ10��)
l/list ��:l *(������+ƫ��)
Ȼ����ݶ�λ���Ķ�ӦԴ�������ļ����������⼴��
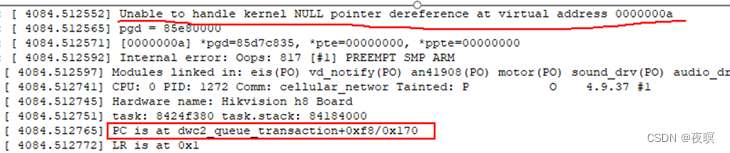
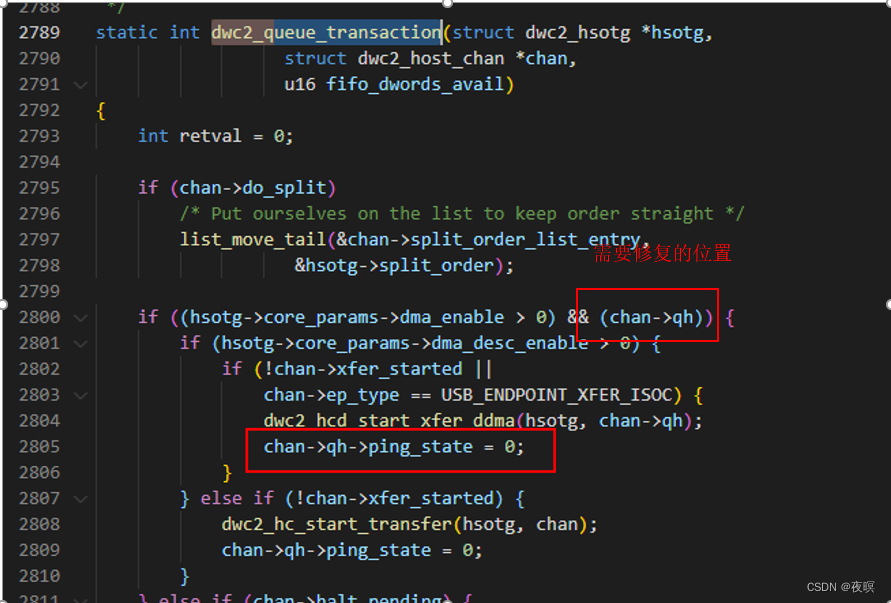
7.ʹ��addr2line��λ�ں�������Դ�롣����ͼΪ֮ǰ���������һ��oops��ӡ�����Է������������dwc2_queue_transaction������ֱ���ҵ��ں˶�Ӧ�ķ��ű�,�ҵ��ú�����Ӧ�ں˵�����λ��
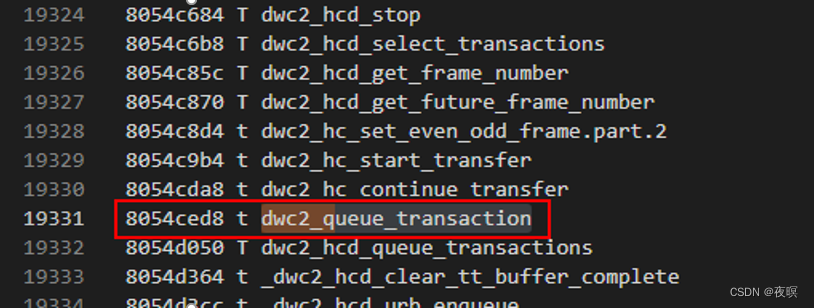
ȷ����ƫ��Ϊ 0x8054ced8+0xf8=0x8054CFD0
ʹ������ xxx(������)-addr2line -C -f -e vmlinux 8054CFD0,ȷ������������������2805
��addr2line����˵��:
(1).-a:�ں��������ļ������к���Ϣ֮ǰ,��ʮ��������ʽ��ʾ��ַ��
(2).-b:ָ��Ŀ���ļ��ĸ�ʽΪbfdname��
(3).-C:���ͼ���ķ���������Ϊ�û���������֡�
(4).-e:ָ����Ҫת����ַ�Ŀ�ִ���ļ���,Ĭ���ļ���a.out��
(5).-f:����ʾ�ļ������к���Ϣ��ͬʱ��ʾ��������
(6).-s:����ʾÿ���ļ���(the base of each file name)ȥ��Ŀ¼����
(7).-i:�����Ҫת���ĵ�ַ��һ����������,����ӡ���ص�һ����������������Ϣ��
(8).-j:��ȡָ��section��ƫ�ƶ����Ǿ��Ե�ַ��
(9).-p:ʹ��ӡ�������Ի�:ÿ����ַ(location)����Ϣ����ӡ��һ���ϡ�
(10).-r:���û���õݹ������ơ�
(11).�Chelp:��ӡ������Ϣ��
(12).�Cversion:��ӡ�汾�š�
����:������,�ʺϸ���
ʹ������:arm-seev100-linux-gnueabihf-objdump -d oops.ko > test.s
Ȼ��ֱ����ߣ���,��PC���Կ���������0xc����ʱr3=0,r2=1��Str����r2�����ݸ���r3ָ����ڴ漴0����0����ڴ��ַ�������ǷǷ���