Prometheus���Linux����
Prometheus node-exporter ���Linux������
node-export ��Ҫ������Linux���������,����������Ľ������������˶��� CPU���ڴ�,���̿ռ�,iops,tcp����������Դ��
Node Exporter �����ڱ�¶ *NIX ����ָ��� Exporter,����ɼ� CPU���ڴ桢���̵���Ϣ������ Go ��д,�������κε���������,����ֻ��Ҫ���ؽ�ѹ�������С�
Exporter��Prometheus��һ�����ݲɼ�������ܳơ��������Ŀ�괦�Ѽ�����,������ת��ΪPrometheus֧�ֵĸ�ʽ���봫ͳ�����ݲɼ������ͬ����,�������������������������,���ǵȴ��������������ǰ��ץȡ��
node-exporter���ڲɼ����������������ָ��,����������loadavg��filesystem��meminfo�Ȼ������,�����ڴ�ͳ�������ά�ȵ�zabbix-agent
node_exporter:���ڼ��Linuxϵͳ��ָ��ɼ�����
����ָ��:
?CPU
? �ڴ�
? Ӳ��
? ��������
? �ļ�������
? ϵͳ����
? ϵͳ����
���ݽӿ�:http://IP:9100/metrics
ʹ���ĵ�:https://prometheus.io/docs/guides/node-exporter/
GitHub:GitHub - prometheus/node_exporter: Exporter for machine metrics
һ��node-exporter ʹ��
?
1.1 ���� node-exporter
node-exporter ���ص�ַ:https://prometheus.io/download/
node-exporter ����ʹ�������в���Ҳ����ָ��������������
1.2 ����node-exporter
�� metrics �ӿ����ݾ���һ������ Prometheus ���ָ���ʽ,����ֻ��Ҫ���ö˵����õ� Prometheus �м���ץȡ��ָ�����ݡ�Ϊ���˽� node_exporter �����õIJ���,���ǿ���ʹ�� ./node_exporter -h ���鿴������Ϣ:
? ? ./node_exporter -h
--web.listen-address=":9100" # �����Ķ˿�,Ĭ����9100
--web.telemetry-path="/metrics" # metrics��·��,Ĭ��Ϊ/metrics
--web.disable-exporter-metrics # �Ƿ����go��promeĬ�ϵ�metrics
--web.max-requests=40 # �����������,Ĭ��40,����Ϊ0ʱ������
--log.level="info" # ��־�ȼ�: [debug, info, warn, error, fatal]
--log.format=logfmt # ����־��ӡtarget��ʽ: [logfmt, json]
--version # �汾��
--collector.{metric-name} # ����metric��Ӧ�IJ���
��ʹ�� --collectors.enabled����ָ��node_exporter�ռ��Ĺ���ģ��,������--no-collectorָ������Ҫ��ģ��,�����ָ��,��ʹ��Ĭ�����á�
����Ҫ�IJ������� --collector.,ͨ���ò����������������ռ��Ĺ���ģ��,node_exporter ��Ĭ�ϲɼ�һЩģ��,Ҫ������ЩĬ�����õ��ռ�������ͨ�� --no-collector. ��־������,���ֻ����ijЩ�ض����ռ���,������ʹ�� --collector.disable-defaults ��־��������Ĭ�ϵ�,Ȼ����ͨ��ָ��������ռ��� --collector. ���������á���ͼ�г���Ĭ�����õ��ռ���:

?
1.3 ��д�����ű�
����prometheus����û�
sudo groupadd -r prometheus
sudo useradd -r -g prometheus -s /sbin/nologin -M -c "prometheus Daemons" prometheus
vim /usr/lib/systemd/system/node_exporter.service
[Unit]
Description=node_exporter
After=network.target
#���Դ�����Ӧ���û����� ����
User=prometheus
Group=prometheus
[Service]
ExecStart=/usr/local/node_exporter/node_exporter\
--web.listen-address=:9100\
--collector.systemd\
--collector.systemd.unit-whitelist=(sshd|nginx).service\
--collector.processes\
--collector.tcpstat
[Install]
WantedBy=multi-user.target
1.4 ���� node_exporter
systemctl daemon-reload
systemctl start process_exporter
systemctl enable process_exporter
��֤�������
curl http://localhost:9100/metrics
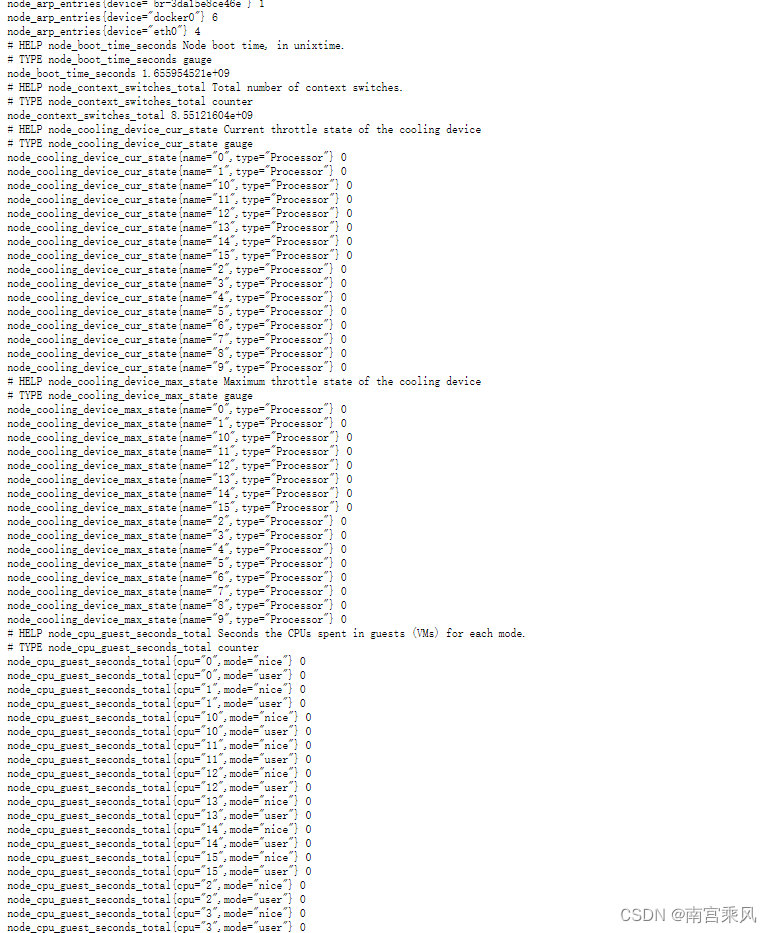
?
����prometheus ����
���ӻ�������
- job_name: 'dev_prometheus'
scrape_interval: 10s
honor_labels: true
metrics_path: '/metrics'
static_configs:
- targets: ['127.0.0.1:9090','127.0.0.1:9100']
labels: {cluster: 'dev',type: 'basic',env: 'dev',job: 'prometheus',export: 'node-exporter'}
- targets: ['127.0.0.1:9256']
labels: {cluster: 'dev',type: 'process',env: 'dev',job: 'prometheus',export: 'process_exporter'}
���� prometheus ����
curl -X POST http://127.0.0.1:9090/-/reload
����grafana ��ͼ
process-exporter ��Ӧ�� dashboard Ϊ:https://grafana.com/grafana/dashboards/16098-1-node-exporter-for-prometheus-dashboard-cn-0417-job/
������
�ġ����ü�ع���
�ο���վ:https://awesome-prometheus-alerts.grep.to/rules
�����վ���кöೣ�������ĸ澯����,������Щ����һ��ʵ��,��Щʹ���������д���,����Ͱ���Щ�����ų���,ֻ������ʹ�õ�
�������:https://www.cnblogs.com/sanduzxcvbnm/p/13589792.html ��ʹ��
groups:
- name: ����״̬-��ظ澯
rules:
- alert: ����״̬
expr: up == 0
for: 1m
labels:
status: �dz�����
annotations:
summary: "{{$labels.instance}}:������崻�"
description: "{{$labels.instance}}:��������ʱ����5����"
- alert: CPUʹ�����
expr: 100-(avg(irate(node_cpu_seconds_total{mode="idle"}[5m])) by(instance)* 100) > 60
for: 1m
labels:
status: һ��澯
annotations:
summary: "{{$labels.mountpoint}} CPUʹ���ʹ���!"
description: "{{$labels.mountpoint }} CPUʹ�ô���60%(Ŀǰʹ��:{{$value}}%)"
- alert: �ڴ�ʹ��
expr: 100 -(node_memory_MemTotal_bytes -node_memory_MemFree_bytes+node_memory_Buffers_bytes+node_memory_Cached_bytes ) / node_memory_MemTotal_bytes * 100> 80
for: 1m
labels:
status: ���ظ澯
annotations:
summary: "{{$labels.mountpoint}} �ڴ�ʹ���ʹ���!"
description: "{{$labels.mountpoint }} �ڴ�ʹ�ô���80%(Ŀǰʹ��:{{$value}}%)"
- alert: IO����
expr: 100-(avg(irate(node_disk_io_time_seconds_total[1m])) by(instance)* 100) < 60
for: 1m
labels:
status: ���ظ澯
annotations:
summary: "{{$labels.mountpoint}} �������IOʹ���ʹ���!"
description: "{{$labels.mountpoint }} �������IO����60%(Ŀǰʹ��:{{$value}})"
- alert: ����
expr: ((sum(rate (node_network_receive_bytes_total{device!~'tap.*|veth.*|br.*|docker.*|virbr*|lo*'}[5m])) by (instance)) / 100) > 102400
for: 1m
labels:
status: ���ظ澯
annotations:
summary: "{{$labels.mountpoint}} ���������������!"
description: "{{$labels.mountpoint }}���������������2���Ӹ���100M. RX����ʹ����{{$value}}"
- alert: ����
expr: ((sum(rate (node_network_transmit_bytes_total{device!~'tap.*|veth.*|br.*|docker.*|virbr*|lo*'}[5m])) by (instance)) / 100) > 102400
for: 1m
labels:
status: ���ظ澯
annotations:
summary: "{{$labels.mountpoint}} ���������������!"
description: "{{$labels.mountpoint }}���������������2���Ӹ���100M. RX����ʹ����{{$value}}"
- alert: TCP�Ự
expr: node_netstat_Tcp_CurrEstab > 1000
for: 1m
labels:
status: ���ظ澯
annotations:
summary: "{{$labels.mountpoint}} TCP_ESTABLISHED����!"
description: "{{$labels.mountpoint }} TCP_ESTABLISHED����1000%(Ŀǰʹ��:{{$value}}%)"
- alert: ��������
expr: 100-(node_filesystem_free_bytes{fstype=~"ext4|xfs"}/node_filesystem_size_bytes {fstype=~"ext4|xfs"}*100) > 80
for: 1m
labels:
status: ���ظ澯
annotations:
summary: "{{$labels.mountpoint}} ���̷���ʹ���ʹ���!"
description: "{{$labels.mountpoint }} ���̷���ʹ�ô���80%(Ŀǰʹ��:{{$value}}%)"
�塢Ansible �������Ӳ���

������� Consul ע�ᷢ�ַ�ʽ,������ݿ��Բ�ѯ����
5.1Consul ע��ű�
#!/bin/bash
service_name=$1
instance_id=$2
ip=$3
port=$4
curl -X PUT -d '{"id": "'"$instance_id"'","name": "'"$service_name"'","address": "'"$ip"'","port": '"$port"',"tags": ["'"$service_name"'"],"checks": [{"http": "http://'"$ip"':'"$port"'","interval": "5s"}]}' http://10.1.8.202:8500/v1/agent/service/register
5.2 Ansible �籾�ű�
[root@openvpn node]# cat playbook.yml
- hosts: Sm
remote_user: root
gather_facts: no
tasks:
- name: ���Ͳɼ�����װ��
unarchive: src=node_exporter-1.2.2.linux-amd64.tar.gz dest=/usr/local/
- name: ������
shell: |
cd /usr/local/
if [ ! -d node_exporter ];then
mv node_exporter-1.2.2.linux-amd64 node_exporter
fi
- name: ��ѯ��������
shell: echo "`hostname`"
register: name_host
- name: ����system�ļ�
copy: src=node_exporter.service dest=/usr/lib/systemd/system
- name: ��������
systemd: name=node_exporter state=started enabled=yes
- name: ����ע��ű�
copy: src=consul-register.sh dest=/usr/local/node_exporter
- name: ע�ᵱǰ�ڵ�
shell: /bin/sh /usr/local/node_exporter/consul-register.sh {{ group_names[0] }} {{ name_host.stdout }} {{ inventory_hostname }} 9100
?
����ָ���Զ�����
6.1 �Զ�����
node_exporter�ĨCcollector.textfile��һ���ռ���,����ռ��������������DZ�¶�Զ���ָ��,����ijЩpushgateway�������Զ����ָ��,�Ϳ���ʹ�èCcollector.textfile������ʵ��,����,node_exporterʵ�������������š���node_expoerter ,ֱ�������ڻ�������textfile collector���ɡ������pushgateway�Ļ�,����ʹ��pushgateway��,Ҳ����ʹ��textfilecollector��
?
node_exporter��collector.textfile �����Զ�����,collector.text�ռ���ͨ��ɨ��ָ��Ŀ¼�е��ļ�,��ȡ���и�ʽΪPrometheusָ����ַ���,Ȼ��¶�����Ա�ץȡ
����:�Ccollector.textfile.directory
6.2 Textfile Collectorʹ��
��Ϊnode_exporter֮ǰ�Ѿ���װ��,���node_exporter����ʱû��ָ���Ccollector.textfile.directory����,��Ҫ�������ļ�����,�����ϲ���,��ȷ���ļ�ָ��Ŀ¼���ڡ�
[root@openvpn disk]# cat node_exporter.service
[Unit]
Description=node_exporter
After=network.target
[Service]
ExecStart=/usr/local/node_exporter/node_exporter\
--web.listen-address=:9100\
--collector.systemd\
--collector.systemd.unit-whitelist=(sshd|nginx).service\
--collector.processes\
--collector.tcpstat\
--collector.supervisord\
--collector.textfile.directory="/usr/local/node_exporter"
#ָ���Եļ��Ŀ¼
[Install]
WantedBy=multi-user.target
6.3 ����
#����
# systemd ��ʽ����
systemctl daemon-reload
systemctl enable node_exporter
systemctl start node_exporter
systemctl status node_exporter
# supervisor��ʽ����
supervisorctl update
supervisorctl status
supervisorctl start node_exporter
supervisorctl restart node_exporter
?
?
#����Ƿ������ɹ�
ss -untlp |grep 9100
ps -ef |grep node_exporter
6.4 д���Զ���ָ��
д���Զ���ָ��,�����Ҫ�Լ������ű�,������д���Ӧ���ļ����ɡ�Ҳ������github(���ҵ��ҡ�)�п�ʵ���ļ�,��Ϥpython����shell������д��
GitHub �����ṩģ���,���� directory-size.sh
# cat directory-size.sh
#!/bin/sh
#
# Expose directory usage metrics, passed as an argument.
#
# Usage: add this to crontab:
#
# */5 * * * * prometheus directory-size.sh /var/lib/prometheus | sponge /var/lib/node_exporter/directory_size.prom
#
# sed pattern taken from https://www.robustperception.io/monitoring-directory-sizes-with-the-textfile-collector/
#
# Author: Antoine Beaupr�� <anarcat@debian.org>
echo "# HELP node_directory_size_bytes Disk space used by some directories"
echo "# TYPE node_directory_size_bytes gauge"
du --block-size=1 --summarize "$@" \
| sed -ne 's/\\/\\\\/;s/"/\\"/g;s/^\([0-9]\+\)\t\(.*\)$/node_directory_size_bytes{directory="\2"} \1/p'
�˴����Ҹ��ļ�shell�ű���ȡ����
[root@openvpn disk]# cat disk_cheak.sh
#!/bin/sh
system=$(lsblk -fs |grep -w / |awk '{print $1}')
disk=$(lsblk -rfs|grep -E 'xfs|f2fs|ntfs'| grep -v $system|awk '{print $5}' |awk -F '%' '{print $1}' |wc -l)
theNum=$( df -h |grep /data/plot |wc -l)
name="check_disk_nums"
pool_nums=$(tail -n 1 /root/hpool/log/miner.log.log | awk '{print $6}'|cut -d '=' -f 2|awk -F '[ "]' '{print $4,$NF}'|awk '{sub(/^[\t ]*/,"");print}')
CPU_sensors=$(sensors | grep "^Package id 0:" | sed 's/Package id 0://' | sed 's/^\s*.+//' | awk '{print $1}' | sed 's/��C//')
echo "check_cpu_sensors $CPU_sensors" > /usr/local/node_exporter/check_cpu_sensors.prom
echo "check_pool_nums $pool_nums" > /usr/local/node_exporter/check_pool_nums.prom
if [ $disk != $theNum ]; then
echo "$name 0" > /usr/local/node_exporter/check_disk_nums.prom
else
echo "$name $disk" > /usr/local/node_exporter/check_disk_nums.prom
fi
6.5 ���ö�ʱ��������
chmod a+x disk_cheak.sh
crontab -l
#Ansible: check_disk
*/5 * * * * /bin/bash /usr/local/node_exporter/disk_cheak.sh

6.6 ansible��������ִ��

[root@openvpn disk]# cat playbook.yml
- hosts: all
remote_user: root
gather_facts: no
tasks:
- name: ����system�ļ�
copy: src=node_exporter.service dest=/usr/lib/systemd/system
- name: ������������
systemd: name=node_exporter state=restarted enabled=yes
- name: ���ʹ��̽ű�
copy: src=disk_cheak.sh dest=/usr/local/node_exporter mode=u+x
- name: ���ö�ʱ����
cron: name="check_disk" minute="*/5" job="/bin/bash /usr/local/node_exporter/disk_cheak.sh" state="present"
- name: ִ�нű�
shell: /bin/bash /usr/local/node_exporter/disk_cheak.sh
ִ������
ansible-playbook playbook.yml -i ./hosts1 -f 10
6.7 ��֤����

?