����Ŀ¼
���ڶ�Linux����ϵͳ����Ȥ,�Լ��Եײ�֪ʶ��ǿ������,�����������ƪ���¡�����Ҳ������Ϊ�������֪ʶ��ָ��,�������º�����һ��ϵͳ�ķ������档���û�����Ƶļ����ϵͳ֪ʶ,����֪ʶ�Ͳ���ϵͳ֪ʶ,�ĵ��еĹ���,�Dz�������ȫ���յ�,�����ϵͳ���ܷ������Ż���һ�����ڵ�ϵ�С�
ǰ��
- ����֪ʶ:�߱�����֪ʶ�Ƿ�����������ʱ��Ҫ�˽�ġ�����Ӳ�� cache;�ٱ������ϵͳ�ںˡ�Ӧ�ó������Ϊϸ�������Ǻ���Щ��������ǣ����,��Щ�ײ�Ķ����������벻���ķ�ʽӰ��Ӧ�ó��������,����ijЩ������������� cache,�Ӷ����������½������粻��Ҫ�ص��ù����ϵͳ����,���Ƶ�����ں� / �û��л��ȡ�
- ���ܷ�������
��������һ��ͼ:
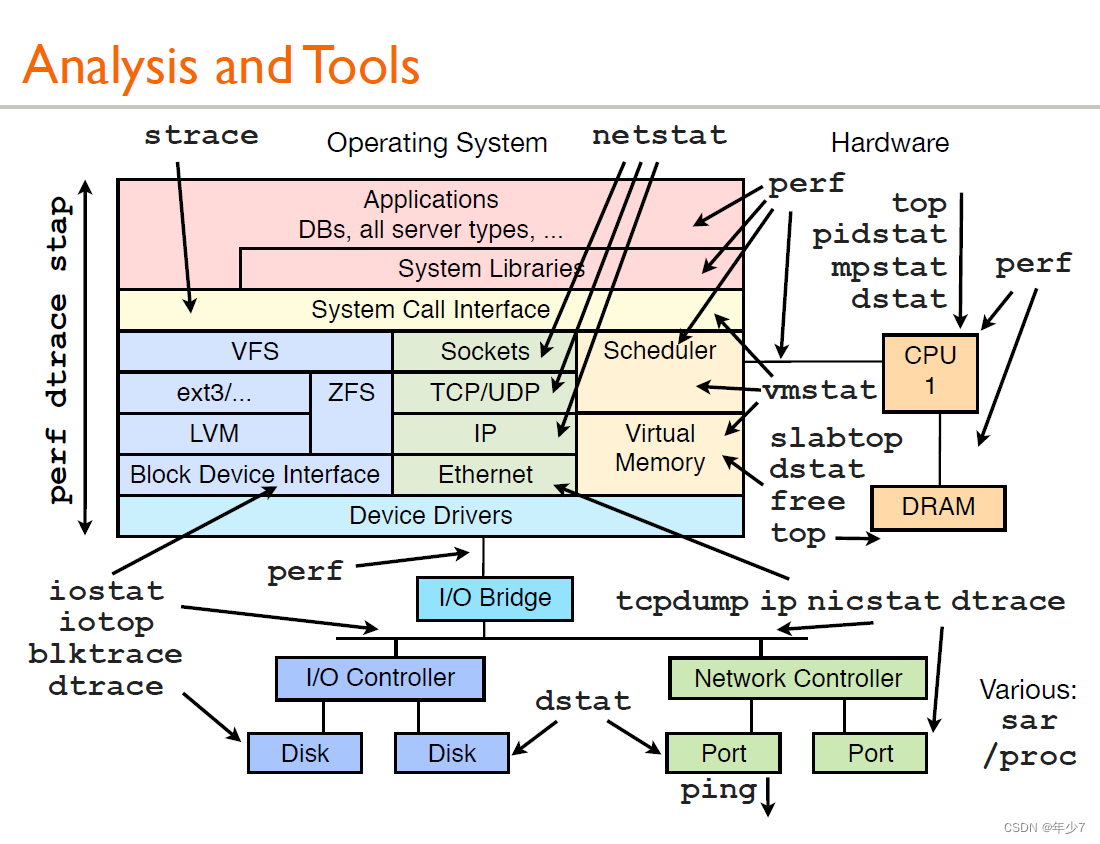
һ vmstat�C�����ڴ�ͳ��
1.1 vmstat�C�����ڴ�ͳ��
- vmstat(
VirtualMeomoryStatistics,�����ڴ�ͳ��):�� Linux �м���ڴ�ij��ù���,�ɶԲ���ϵͳ�������ڴ桢���̡�CPU �ȵ�����������м��ӡ� - vmstat �ij����÷�:
vmstat interval times��ÿ�� interval �����һ��,������ times ��,���ʡ�� times,��һֱ�ɼ�����,ֱ���û��ֶ�ֹͣΪֹ��
�ٸ�����:
[root@matrix01 ~]# vmstat 5
procs -----------memory---------- ---swap-- -----io---- -system-- ------cpu-----
r b swpd free buff cache si so bi bo in cs us sy id wa st
30 0 0 17375844 1820 79094832 0 0 0 54 0 0 15 6 79 0 0
6 0 0 17693352 1820 79095664 0 0 0 2309 90280 109807 13 6 80 0 0
8 0 0 16006636 1820 79099904 0 0 0 2848 82054 105837 15 7 78 0 0
����ʹ�� ctrl+c ֹͣ vmstat �ɼ����ݡ�
- ��һ����ʾ��ϵͳ������������ƽ��ֵ,�ڶ��п�ʼ��ʾ�������ڷ��������,���������л���ʾÿ5����������ʲô,ÿһ�еĺ�����ͷ��,������ʾ:
- �� procs:r ��һ����ʾ�˶��ٽ����ڵȴ�cpu,b����ʾ���ٽ������ڲ����жϵ�����(
�ȴ�IO)�� - �� memory:swapd ����ʾ�˶��ٿ鱻�����˴���(
ҳ�潻��),ʣ�µ�����ʾ�˶��ٿ��ǿ��е�(δ��ʹ��),���ٿ����ڱ�����������,�Լ��������ڱ���������ϵͳ�Ļ��档 - �� swap:��ʾ�����:ÿ���ж��ٿ����ڱ�����(
�Ӵ���)�ͻ���(������)�� - �� io:��ʾ�˶��ٿ�ӿ��豸��ȡ(
bi)��д��(bo),ͨ����ӳ��Ӳ��I/O�� - �� system:��ʾÿ���ж�(in)���������л�(
cs)�������� - �� cpu:��ʾ���е�cpuʱ�仨���ڸ�������İٷֱ�,����ִ���û�����(
���ں�),ִ��ϵͳ����(�ں�),�����Լ��ȴ�IO��
- �� procs:r ��һ����ʾ�˶��ٽ����ڵȴ�cpu,b����ʾ���ٽ������ڲ����жϵ�����(
- �ڴ治��ı���:free memory �������,���� buffer �� cache Ҳ������,����ʹ�ý�������(swpd),ҳ�潻��(swap)Ƶ��,��д��������(io)����,ȱҳ�ж�(in)����,�������л�(cs)��������,�ȴ�IO�Ľ�����(b)����,����CPUʱ�����ڵȴ�IO(wa)
1.2 iostat�C���ڱ������봦����ͳ����Ϣ
iostat ���ڱ������봦����(CPU)ͳ����Ϣ������ϵͳ����������tty �豸�����̺� CD-ROM ������/���ͳ����Ϣ,Ĭ����ʾ����vmstat ��ͬ�� cpu ʹ����Ϣ,ʹ������������ʾ��չ���豸ͳ��:
[root@matrix01 ~]# iostat -dx 5
Linux 3.10.0-957.27.2.el7.x86_64 (matrix01) 2022��12��16�� _x86_64_ (48 CPU)
Device: rrqm/s wrqm/s r/s w/s rkB/s wkB/s avgrq-sz avgqu-sz await r_await w_await svctm %util
sda 0.00 0.00 0.00 0.00 0.00 0.00 8.36 0.00 2.88 2.88 0.00 2.82 0.00
sdc 0.00 0.00 0.00 24.02 0.01 146.72 12.22 0.00 0.10 0.18 0.10 0.06 0.13
sdb 0.00 1.76 0.88 148.78 16.13 2393.49 32.20 0.04 0.28 0.49 0.28 0.05 0.69
dm-0 0.00 0.00 0.00 0.00 0.00 0.00 5.07 0.00 0.53 0.53 0.00 0.53 0.00
dm-1 0.00 0.00 0.00 0.07 0.00 0.30 8.67 0.00 0.35 0.42 0.35 0.34 0.00
dm-2 0.00 0.00 0.00 0.07 0.00 0.30 8.67 0.00 0.35 0.58 0.35 0.35 0.00
dm-4 0.00 0.00 0.00 0.07 0.00 0.30 8.68 0.00 0.37 0.96 0.37 0.35 0.00
dm-5 0.00 0.00 0.00 0.00 0.01 0.00 7.87 0.00 47.96 59.07 20.55 13.98 0.00
dm-6 0.00 0.00 0.00 0.31 0.00 52.67 339.55 0.01 25.02 5.00 25.06 0.32 0.01
dm-7 0.00 0.00 0.00 0.31 0.00 52.67 339.65 0.01 25.03 5.98 25.06 0.32 0.01
dm-9 0.00 0.00 0.00 0.31 0.00 52.65 339.93 0.26 853.85 10.15 854.86 0.40 0.01
- ��һ����ʾ������ϵͳ����������ƽ��ֵ,Ȼ����ʾ������ƽ��ֵ,ÿ���豸һ�С�
���� linux �Ĵ��� IO ָ�����дϰ��:
rq �� request,
r �� read,
w �� write,
qu �� queue,
sz �� size,
a ��verage,
tm �� time,
svc �� service��
- �� rrqm/s �� wrqm/s:ÿ��ϲ��Ķ���д����,���ϲ��ġ���ζ�Ų���ϵͳ�Ӷ������ó����������ϲ�Ϊһ������ʵ�ʴ��̡�
- r/s��w/s:ÿ�뷢�͵��豸�Ķ���д��������
- rsec/s��wsec/s:ÿ�����д����������
- avgrq �Csz:�������������
- avgqu �Csz:���豸�����еȴ�����������
- await:ÿ��IO���ѵ�ʱ�䡣
- svctm:ʵ������(����)ʱ�䡣
- %util:������һ����Ծ������ռʱ��İٷֱȡ�
1.3 dstat�Cϵͳ��ع���
dstat ��ʾ�� cpu ʹ�����,���� io ���,���緢������ͻ�ҳ���,����Dz�ɫ��,�ɶ��Խ�ǿ,����� vmstat
��iostat �����������ϸ�ҽ�Ϊֱ�ۡ���ʹ��ʱ,ֱ�����������,��ȻҲ����ʹ���ض�������
��������(ʾ��):dstat �Ccdlmnpsy
1.4 iotop�CLINUX����ʵʱ��ع���
iotop������ר����ʾӲ��IO������,����������top����,������ʾIO���ؾ��������ĸ����̲����ġ���һ���������Ӵ���I/Oʹ��״����top���,������top���Ƶ�UI,���а���PID���û���I/O�����̵������Ϣ��
�����Էǽ����ķ�ʽʹ��
iotop �Cbod interval
�鿴ÿ�����̵� I/O,����ʹ��
pidstat,pidstat �Cd instat
1.5 pidstat�C���ϵͳ��Դ���
pidstat :��Ҫ���ڼ��ȫ����ָ������ռ��ϵͳ��Դ�����,�� CPU,�ڴ桢�豸 IO�������л����߳��ȡ�
- ʹ�÷���:
pidstat �Cd interval
- pidstat ����������ͳ��CPUʹ����Ϣ:
pidstat �Cu interval
- ͳ���ڴ���Ϣ
pidstat �Cr interval
�� top
2.1 top
top����Ļ���������ʾ����������ϵͳ������Ϣ:
- �� ����:ʱ��,��½�û���,ϵͳƽ������;
- �� ����:����,˯��,ֹͣ,��ʬ;
- �� cpu:�û�̬,����̬,NICE,����,�ȴ�IO,�жϵ�;
- �� �ڴ�:����,����,����(ϵͳ�Ƕ�),����,����;
- �� ��������:����,����,����
- �� ��������Ĭ����ʾ:���� ID,��Ч�û�,�������ȼ�,NICE ֵ,����ʹ�õ������ڴ�,�����ڴ�����ڴ�,����״̬,CPU ռ����,�ڴ�ռ����,�ۼ� CPU ʱ��,������������Ϣ��
2.2 htop
htop �� Linux ϵͳ�е�һ�������Ľ��̲鿴��,һ���ı�ģʽ��Ӧ�ó���(�ڿ���̨����X�ն���),��Ҫ ncurses��
Htop �����û�����ʽ����,֧����ɫ����,�ɺ�������������������б�,��֧����������
2.3 �� top ���,htop �������ŵ�:
- ���Ժ���������������������б�,�Ա㿴�����еĽ��̺������������С�
- ��������,��top���졣
- ɱ����ʱ����Ҫ������̺š�
- htop֧����������
�� mpstat��netstat
3.1 mpstat
mpstat �� Multiprocessor Statistics����д,��ʵʱϵͳ��ع��ߡ��䱨��CPU��һЩͳ����Ϣ,��Щ��Ϣ����� /proc/stat �ļ��С��ڶ� CPUs ϵͳ��,�䲻���ܲ鿴���� CPU ��ƽ��״����Ϣ,�����ܹ��鿴�ض� CPU ����Ϣ��
�����÷�:
mpstat �CP ALL interval times
3.2 netstat
netstat ������ʾ�� IP��TCP��UDP�� ICMP Э����ص�ͳ������,һ�����ڼ��鱾�����˿ڵ��������������
�����÷�:
netstat �Cnpl # ���Բ鿴��Ҫ�Ķ˿��Ƿ��Ѿ���
netstat �Crn # ��ӡ·�ɱ���Ϣ��
netstat �Cin # �ṩϵͳ�ϵĽӿ���Ϣ,��ӡÿ���ӿڵ�MTU,���������,�������,���������,�������,���Լ���ǰ��������еij��ȡ�
�� ps��strace��uptime��lsof��perf
4.1 ps�C��ʾ��ǰ���̵�״̬
ps ����̫��,����ʹ�÷������Բο� man ps
���õķ���:
ps aux #hsserver
ps �Cef |grep #hundsun
- ɱ��ijһ����ķ���:
ps aux | grep mysqld | grep �Cv grep | awk ��{print $2 }�� xargs kill -9
- ɱ����ʬ����:
ps �Ceal | awk ��{if ($2 == ��Z��){print $4}}�� | xargs kill -9
4.2 strace
���ٳ���ִ�й����в�����ϵͳ���ü����յ����ź�,�����������������ִ�����������쳣�����
����: �鿴 mysqld �� linux �ϼ������������ļ�,����ͨ���������������:
strace �Ce stat64 mysqld �Cprint �Cdefaults > /dev/null
4.3 uptime
�ܹ���ӡϵͳ�ܹ������˶ʱ���ϵͳ��ƽ������,uptime �������������������ֵĺ���ֱ��� 1����,5����,15������ϵͳ��ƽ�����ɡ�

4.4 lsof
lsof(list open files)��һ���г���ǰϵͳ���ļ��Ĺ��ߡ�ͨ�� lsof �����ܹ��鿴����б���ϵͳ��⼰�Ŵ���
�������÷�:
| ���� | ���� |
|---|---|
| lsof /boot | �鿴�ļ�ϵͳ���� |
| lsof -i : 3306 | �鿴�˿ںű��ĸ�����ռ�� |
| lsof �Cu username | �鿴�û�����Щ�ļ� |
| lsof �Cp 4838 | �鿴���̴���Щ�ļ� |
| lsof �Ci @192.168.34.128 | �鿴Զ���Ѵ��������� |
4.5 perf
-
perf �� Linux kernel �Դ���ϵͳ�����Ż����ߡ�
����:������ Linux Kernel �Ľ��ܽ��,����������Ӧ�õ����� Kernel ��new feature,���ڲ鿴�ȵ㺯��,�鿴 cashe miss �ı���,�Ӷ��������������Ż��������ܡ� -
���ܵ��Ź����� perf,Oprofile �ȵĻ���ԭ�����ǶԱ���������в���,��������Ǹ��� tick �жϽ��в���,���� tick �ж��ڴ���������,�ڲ��������жϳ���ʱ�������ġ�
-
����һ������ 90% ��ʱ�䶼�����ں��� foo() ��,��ô 90% �IJ����㶼Ӧ�����ں��� foo() ���������С�����������,������ֻҪ����Ƶ���㹻��,����ʱ���㹻��,��ô�������۾ͱȽϿɿ������,ͨ�� tick ��������,���DZ�����˽��������Щ�ط����ʱ��,�Ӷ��ص������
�� ���õ����ܲ��Թ���
��������ͨ�˵ڶ����ֵ����ܷ��������,���뼸�����ܲ��ԵĹ���,����֮ǰ�ȼ��˽⼸�����ܲ��Թ���:
- perf_events:һ���� Linux �ں˴���һͬ������ά����������Ϲ���,���ں�����ά���ͷ�չ��Perf ������������Ӧ�ó��������ͳ�Ʒ���,Ҳ����Ӧ�����ں˴��������ͳ�ƺͷ�����
- eBPF tools:һ��ʹ�� bcc ���е������ٵĹ���,eBPF map����ʹ�ö��Ƶ� eBPF ���㷺Ӧ�����ں˵��ŷ���,Ҳ���Զ�ȡ�û������첽���롣��Ҫ��������ⲿ�����ݿ������û��ռ��������� k-v ��ʽ�� map ��������ͨ�����û��ռ���� bpf ϵͳ���ô��������ӡ�ɾ���Ȳ��������ġ�
- perf-tools:һ����� perf_events (perf) �� ftrace ��Linux���ܷ������Ź�����Perf-Tools ��������,ʹ�ü�֧��Linux 3.2 �������ں˰汾��
- bcc(BPF Compiler Collection)::һ��ʹ�� eBP F�� perf ���ܷ������ߡ�һ�����ڴ�����Ч���ں˸��ٺͲ�������Ĺ��߰�,�����������õĹ��ߺ�ʾ����������չ��BPF(���������ݰ�������),��ʽ��ΪeBPF,һ���µĹ���,���ȱ����ӵ�Linux 3.15������;��ҪLinux 4.1����BCC��
- ktap:һ�����͵�linux�ű���̬���ܸ��ٹ��ߡ������û�����Linux�ں˶�̬��ktap����Ƹ����л�������,�����û����������ļ���,�ų����Ϻ��ӳ��ں˺�Ӧ�ó�����������Linux��Solaris DTrace SystemTap��
- Flame Graphs:��һ��ʹ�� perf,system tap,ktap ���ӻ���ͼ������,������Ƶ���Ĵ���·������ȷ��ʶ��,������ʹ��
github.com/brendangregg/flamegraph�еĿ���Դ����ij������ɡ�
�� Linux observability tools | Linux ���ܹ۲�ߺ�Linux benchmarking tools | Linux ���ܲ�������
6.1 Linux observability tools | Linux ���ܹ۲��
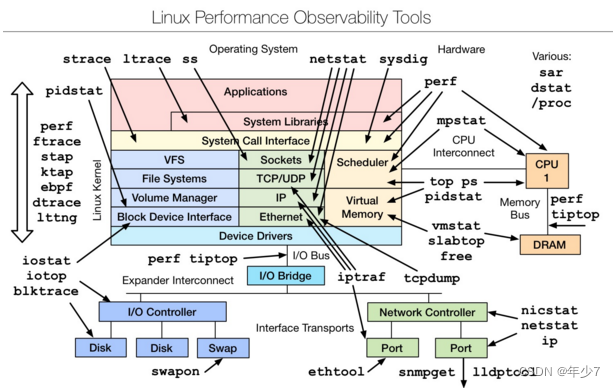
-
����ѧϰ��Basic Tool������:uptime��top(htop)��mpstat��isstat��vmstat��free��ping��nicstat��dstat��
-
������������:sar��netstat��pidstat��strace��tcpdump��blktrace��iotop��slabtop��sysctl��/proc��
6.2 Linux benchmarking tools | Linux ���ܲ�������
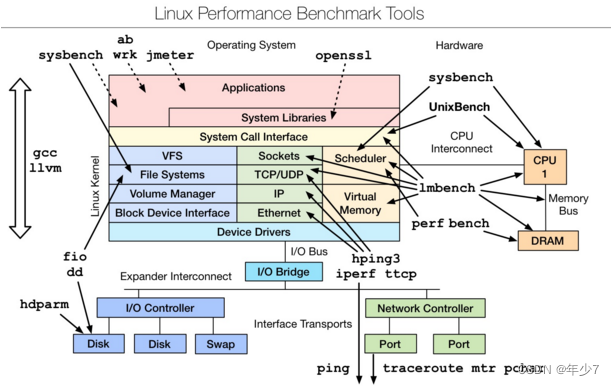
��һ�����ܲ�������,���ڲ�ͬģ������ܲ��Կ���ʹ����Ӧ�Ĺ���,��Ҫ�����˽�,���Բο������ĵĸ����ĵ���
6.3 Linux tuning tools | Linux ���ܵ��Ź���
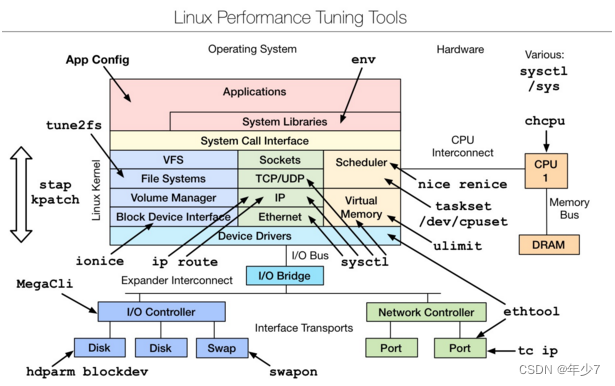
��һ�����ܵ��Ź���,��Ҫ�Ǵ�linux�ں�Դ�����еĵ���,��Ҫ�����˽�,���Բο����ĸ����ĵ���
6.4 Linux observability sar | linux���ܹ۲��
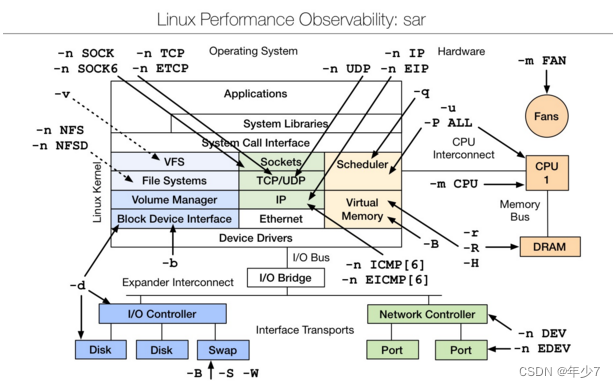
sar(System Activity Reporterϵͳ��������)��ĿǰLINUX����Ϊȫ���ϵͳ���ܷ�������֮һ,���ԴӶ���ϵͳ�Ļ���б���,����:�ļ��Ķ�д�����ϵͳ���õ�ʹ�����������I/O��CPUЧ�ʡ��ڴ�ʹ��״�������̻��IPC �йصĻ�ȷ��档sar �ij���ʹ�÷�ʽ:
sar [options] [-A] [-o file] t [n]
����:t Ϊ�������,n Ϊ��������,Ĭ��ֵ��1;-o file ��ʾ���������Զ����Ƹ�ʽ������ļ���,file ���ļ�����options Ϊ������ѡ��