实验环境与安装文件
| 名称 | 版本 | 说明 |
|---|---|---|
| CentOS | 7 | 操作系统选用了CentOS 7 |
| JDK | Java2SE(build1.8.0_291) | JDK选用了Oracle J2SE 8的最终稳定版 |
| Hadoop | 2.10.1 | Hadoop2的稳定版2.10.1 |
| Hive | 2.3.9 | Hive最新稳定版 |
实验环境准备
- 默认已经安装好Hadoop
- Hive下载
- apache-hive-2.3.9-bin.tar.gz压缩文件
- 推荐用FileZilla将Hive安装文件上传至CentOS 7的/usr目录
- 解压并重命名,同时将hive目录的用户设为hadoop
su
cd /usr
tar xzvf apache-hive-2.3.9-bin.tar.gz
mv apache-hive-2.3.9-bin hive
chown -R hadoop hive
配置Hive环境变量
配置/etc/profile文件,设置目录和PATH
vim /etc/profile
- 添加如下信息
export HIVE_HOME=/usr/hive
export PATH=$PATH:$HIVE_HOME/bin
然后使配置文件生效
source /etc/profile
Hive运行之前的配置
修改core-site.xml
- 需要修改hadoop配置文件夹下面的core-site.xml中的内容,不然最后jdbc:hive2://localhost:10000会拒绝连接
vim $HADOOP_HOME/etc/hadoop/core-site.xml
- 在configuration标签内加入下面的内容:
<property>
<name>hadoop.proxyuser.hadoop.hosts</name>
<value>*</value>
</property>
<property>
<name>hadoop.proxyuser.hadoop.groups</name>
<value>*</value>
</property>
切换到hadoop账户($提示符下)、并启动hadoop等进程
su hadoop
start-all.sh
mr-jobhistory-daemon.sh start historyserver
查看hadoop进程
- 首先运行jps命令,查看正在运行的进程
jps
- 如果Hadoop成功运行,应该显示6个守护进程(不包括Jps)
DataNode
SecondaryNameNode
JobHistoryServer
NameNode
ResourceManager
NodeManager
运行HDFS的命令,创建目录并设置权限
hadoop fs -mkdir /user
hadoop fs -mkdir /user/hive
hadoop fs -mkdir /user/hive/warehouse
hadoop fs -chmod 777 /tmp
hadoop fs -chmod 777 /user/hive/warehouse
运行Hive
hive
Hive成功运行后,会进入到Hive的命令行界面(CLI)

退出Hive
quit;
Running HiveServer2 and Beeline
cd $HIVE_HOME/bin
schematool -dbType derby -initSchema
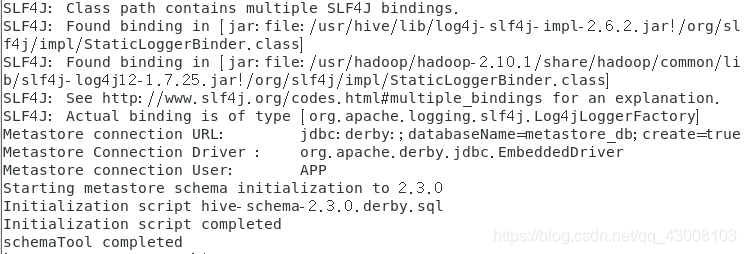
- 验证
schematool -verbose -validate -dbType derby

- Running HiveServer2
hiveserver2
- 这个时候你的页面会一直卡在这里,这是正常的,因为你是启动了一个服务,这时你需要打开一个新的终端
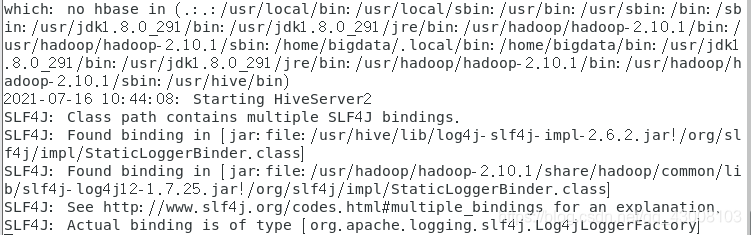
- 打开一个新的终端
su hadoop
/usr/hive/bin/beeline -u jdbc:hive2://localhost:10000

- Hive的使用我们都在Beeline CLI里操作而不是Hive CLI
续
- Hive命令使用:参考《Hive入门操作》或如下网址:
- Hive入门操作
- 以上、参考英文hive文档
- Hive GettingStarted