һ��MySQL���Ӹ���ԭ��
��ʵ�ʵ�������,Ϊ�˽��Mysql�ĵ�������Ѿ����MySQL�������������,һ�㶼����á����Ӹ��ơ���
����:�ڸ��ӵ�ҵ��ϵͳ��,��һ��sqlִ�к�������,��������sql�ĵ�ִ��ʱ���бȽϳ�,��ô��sqlִ�е��ڼ䵼�·�����,�����ͻ�����Ӱ���û�������ȡ�
���Ӹ����з�Ϊ����������(master)���͡��ӷ�����(slave)��,��������������д,���ӷ������������,Mysql�����Ӹ��ƵĹ�����һ�����첽�Ĺ��̡���
������д����Ĺ����ܹ�������ķ����������,��ʹд����ʱ��Ƚϳ�,Ҳ��Ӱ��������Ľ��С�
1��MySQL ֧�ֵĸ�������
�������ĸ���(STATEMENT):������������ִ�е� SQL ���,�ڴӷ�������ִ��ͬ������䡣MySQL Ĭ�ϲ��û������ĸ���,Ч�ʱȽϸߡ�
�����еĸ���(ROW):�Ѹı�����ݸ��ƹ�ȥ,�����ǰ������ڴӷ�������ִ��һ�顣
������͵ĸ���(MIXED):Ĭ�ϲ��û������ĸ���,һ�����ֻ����������ȷ����ʱ,�ͻ���û����еĸ��ơ�
2��MySQL���Ӹ��ƵĹ�������

�ڴӽڵ���ִ��sart slave��������Ӹ��ƿ���,��ʼ�������Ӹ��ơ��ӽڵ��ϵ�I/O �����������ڵ�,�������ָ����־�ļ���ָ��λ��(���ߴ��ʼ����־)֮�����־����;
���ڵ���յ����Դӽڵ��I/O�����,ͨ�������Ƶ�I/O����(log dump �߳�)����������Ϣ��ȡָ����־ָ��λ��֮�����־��Ϣ,���ظ��ӽڵ㡣������Ϣ�г�����־����������Ϣ֮��,���������η��ص���Ϣ��bin-log file ���Լ�bin-log position(bin-log�е���һ��ָ������λ��);
�ӽڵ��I/O���̽��յ����ڵ㷢��������־���ݡ���־�ļ���λ�õ��,�����յ�����־���ݸ��µ�������relay-log(�м���־)���ļ�(Mysql-relay-bin.xxx)����ĩ��,������ȡ����binary log(bin-log)�ļ�����λ�ñ��浽master-info �ļ���,�Ա�����һ�ζ�ȡ��ʱ���ܹ�����ĸ���Master������Ҫ��ij��bin-log ���ĸ�λ�ÿ�ʼ�������־����,�뷢���ҡ�;
Slave �� SQL�̼߳�relay-log �������������ݺ�,�Ὣrelay-log�����ݽ����������ڵ���ʵ��ִ�й�SQL���,Ȼ���ڱ����ݿ��а��ս���������˳��ִ��,����relay-log.info�м�¼��ǰӦ���м���־���ļ�����λ�õ㡣
����MySQL�����
���ݿ�ÿ�춼Ҫ�е�����վ�����ݸ���,���Դ����Ķ�д������һ��������ѹ���dz���ʹ�ö�д���������Ч�Ļ������ݿ�ѹ����
1��MySQL ��д����ԭ��
ֻ������������д,ֻ�ڴӷ������϶���
�����ݿ�������Բ�ѯ,�������ݿ�� select ��ѯ��
���ݿ⸴�Ʊ������������ݿ��������Բ�ѯ���µı��ͬ������Ⱥ�еĴ����ݿ⡣
2����д���뷽��
���ڳ�������ڲ�ʵ�� �ڴ����и���select. insert ����·�ɷ���,�����Ҳ��Ŀǰ��������Ӧ����㷺�ġ��ŵ������ܽϺ�,��Ϊ�ڳ��������ʵ��,����Ҫ���Ӷ�����豸��ΪӲ����֧:ȱ������Ҫ������Ա��ʵ��,��ά��Ա�����֡�
�����м������ʵ��
����һ��λ�ڿͻ��˺ͷ�����֮��,�����������ӵ��ͻ��˵������ͨ���жϺ�ת����������ݿ�,�����������Գ���
(1) MySQL-Proxy��MySQL- -ProxyΪMySQL��Դ��Ŀ,ͨ�����Դ���lua�ű�����SQL�ж�,��Ȼ��MySQL�ٷ���Ʒ,����MySQL�ٷ��������齫MySQL- -Proxy �õ�����������
(2) Amoeba (���γ�)���ɳ�˼�忪��,������ְ�ڰ���Ͱ͡��ó�����Java���Խ��п���,����Ͱͽ���������������������֧������ʹ洢���̡�
���������ıȽ�,ͨ���������ʵ��MySQL��д������Ȼ��һ��������ѡ��, ���Dz��������е�Ӧ�ö��ʺ��ڳ��������ʵ�ֶ�д����,����һЩ�����ӵ�JavaӦ��,����ڳ��������ʵ�ֶ�д����Դ���Ķ��ͽϴ�����,�����ִ����ӵ�Ӧ��һ��ῼ��ʹ�ô�������ʵ�֡�
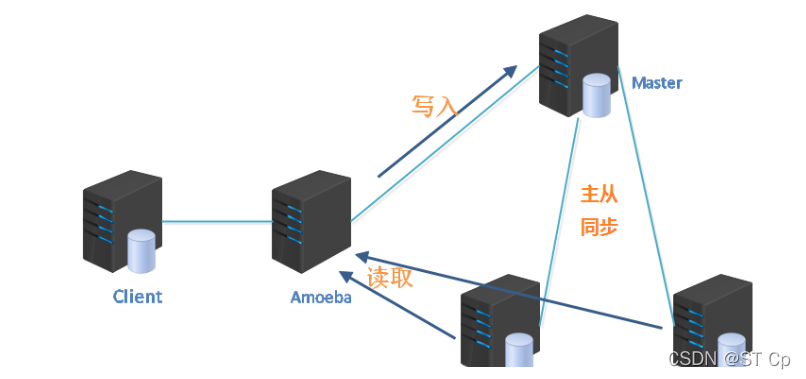
����MySQL���Ӹ��ƺͶ�д����ʵ��ʾ��
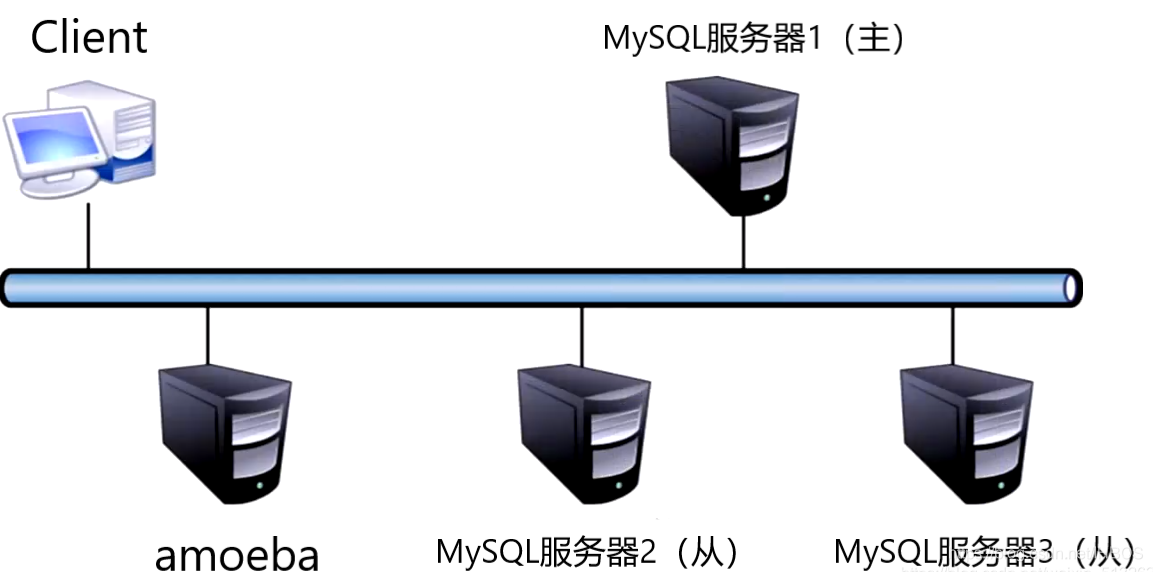
1��ʵ��˼·
1���ͻ��˷��ʴ���������
2������������д�뵽��������
3��������������ɾ��д���Լ���������־
4���ӷ����������������Ķ�������־ͬ�����Լ��м���־
5���ӷ������ط��м���־�����ݿ���
6���ͻ��˶�,�����������ֱ�ӷ��ʴӷ�����
7��������,���ؾ�������
2.� MySQL ���Ӹ���
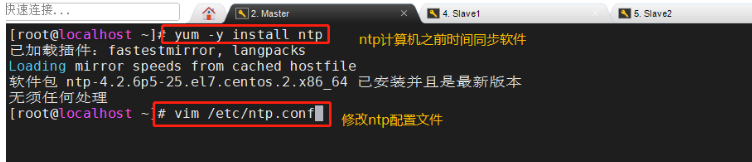
������������(192.168.172.10)
yum -y install ntp
vim /etc/ntp.conf
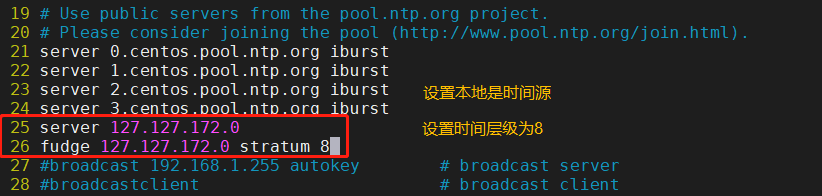
25����������
server 127.127.172.0 #���ñ�����ʱ��Դ,ע��������
fudge 127.127.172.0 stratum 8 #����ʱ��㼶Ϊ8(������15��)
service ntpd start

�ӷ���������(192.168.172.20)��(192.168.172.30)
yum -y install ntp ntpdate
service ntpd start
/usr/sbin/ntpdate 192.168.172.10 #����ʱ��ͬ��,ָ��Master������IP
crontab -e
*/30 * * * * /usr/sbin/ntpdate 192.168.172.10

�������������� ͬ��
2������������mysql����
vim /etc/my.cnf
server-id = 1
log-bin=master-bin #����,��������������������־
log-slave-updates=true #����,�����ӷ��������¶�������־
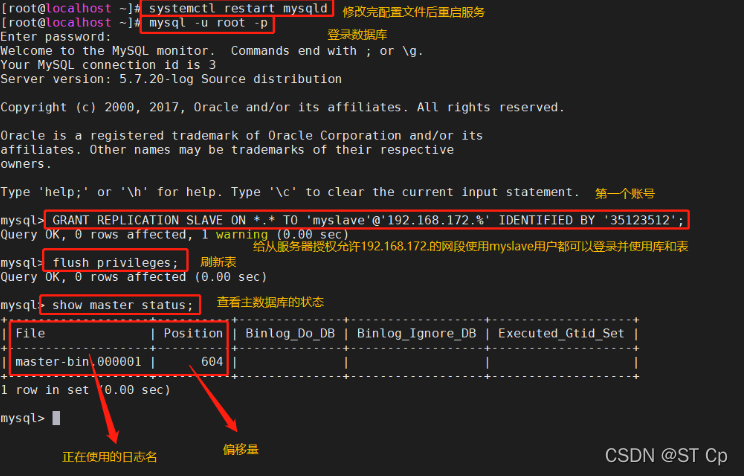
systemctl restart mysqld
mysql -u root -p
GRANT REPLICATION SLAVE ON *.* TO 'myslave'@'192.168.172.%' IDENTIFIED BY '35123512'; #���ӷ�������Ȩ
FLUSH PRIVILEGES;
show master status;
#File ����ʾ��־��,Fosition ����ʾƫ����

3���ӷ�������mysql����
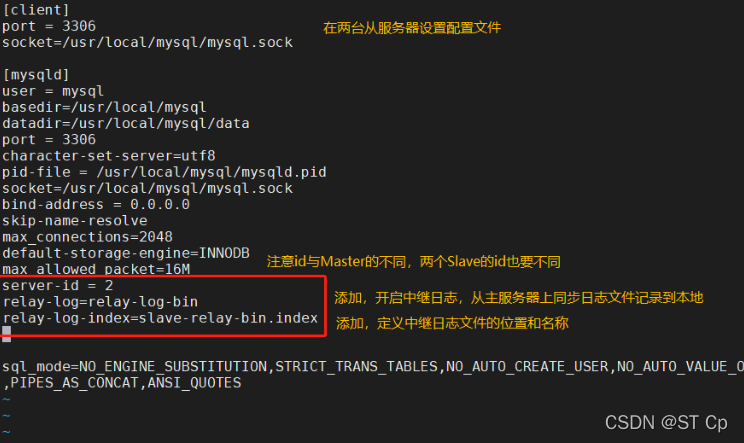
vim /etc/my.cnf
server-id = 2 #��,ע��id��Master�IJ�ͬ,����Slave��idҲҪ��ͬ
relay-log=relay-log-bin #����,�����м���־,������������ͬ����־�ļ���¼������
relay-log-index=slave-relay-bin.index #����,�����м���־�ļ���λ�ú�����
systemctl restart mysqld

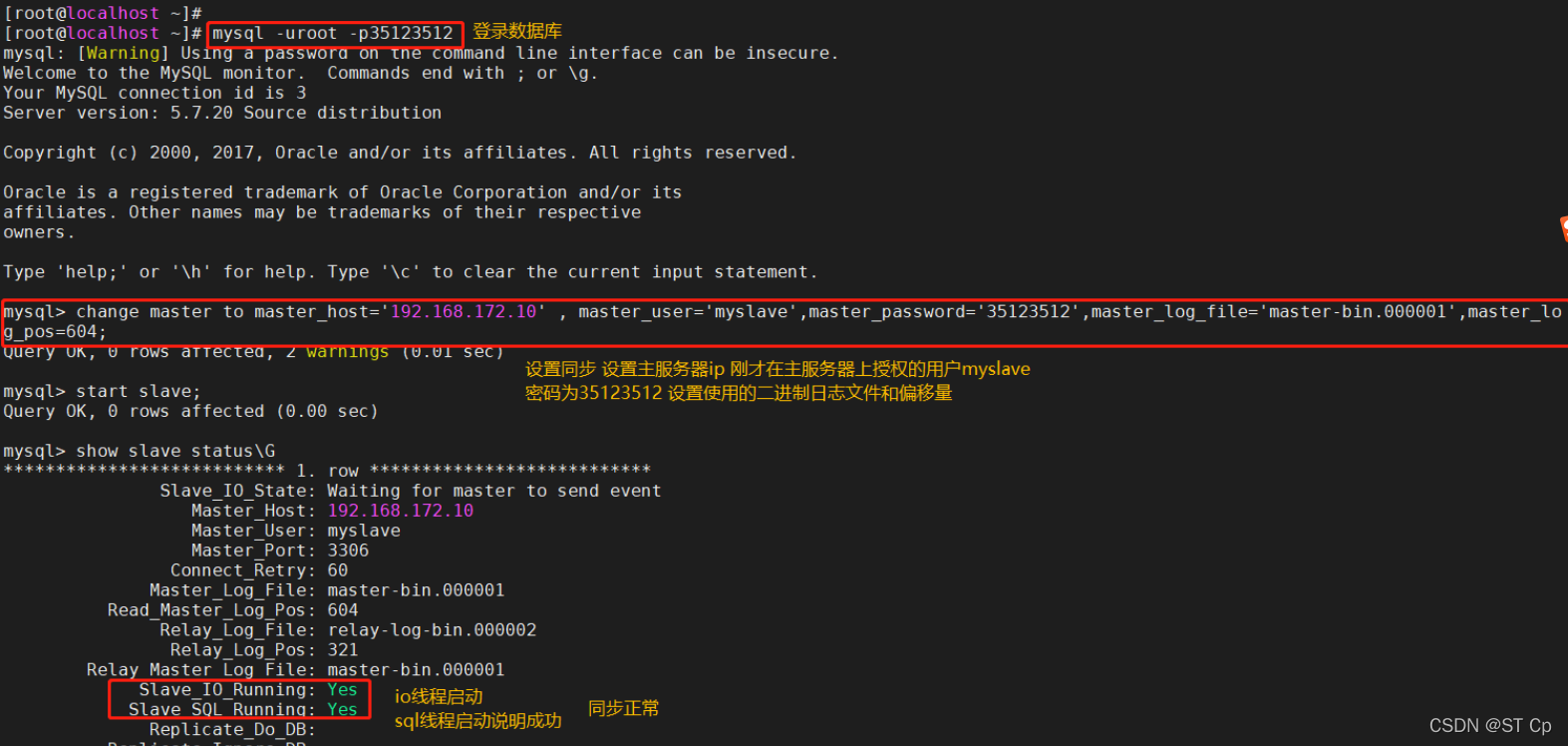
mysql -u root -p
change master to master_host='192.168.172.10' , master_user='myslave',master_password='35123512',master_log_file='master-bin.000001',master_log_pos=604;
#����ͬ��,ע�� master_log_file �� master_log_pos ��ֵҪ��Master��ѯ��һ��,�����������,ÿ���˵Ķ���һ��
start slave; #����ͬ��,���б���ִ�� reset slave;
show slave status\G #�鿴 Slave ״̬
//ȷ�� IO �� SQL �̶߳��� Yes,����ͬ��������
Slave_IO_Running: Yes #������������ioͨ��
Slave_SQL_Running: Yes #�����Լ���slave mysql����
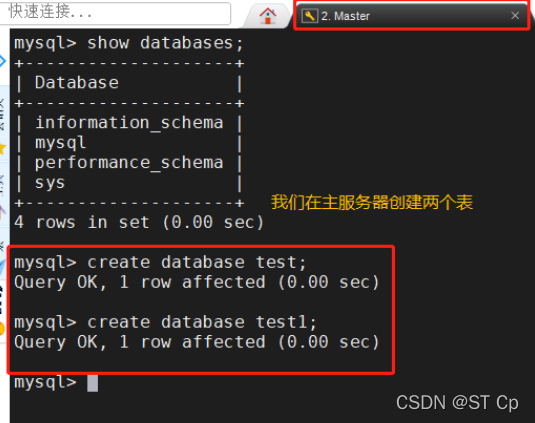
4����֤���Ӹ���Ч��
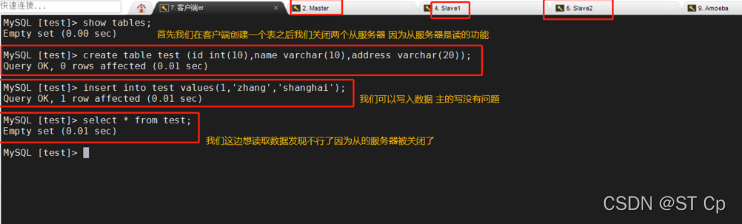
���������Ͻ���ִ�� create database test;


�ġ�� MySQL ��д����
1��Amoeba����������
Amoeba������:192.168.172.40
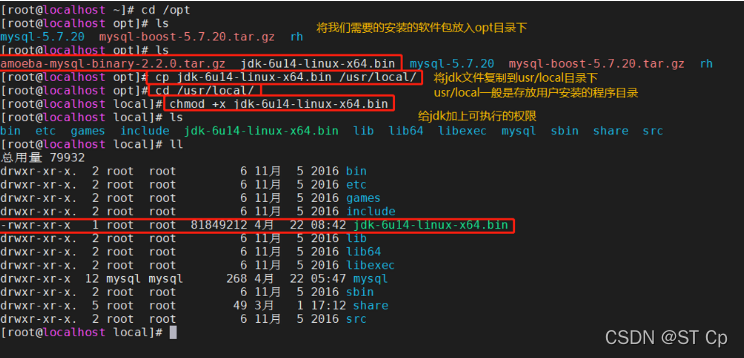
��jdk-6u14-linux-x64.bin �� amoeba-mysql-binary-2.2.0.tar.gz.0 �ϴ���/optĿ¼�¡�
cd /opt/
cp jdk-6u14-linux-x64.bin /usr/local/
cd /usr/local/
chmod +x jdk-6u14-linux-x64.bin
./jdk-6u14-linux-x64.bin
���ո����һ��
��yes,��enter
mv jdk1.6.0_14/ /usr/local/jdk1.6
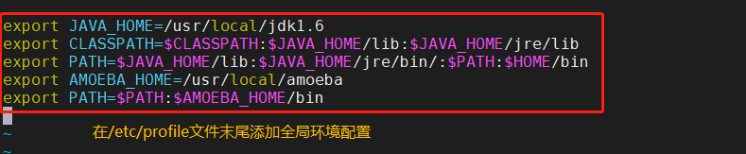
vim /etc/profile
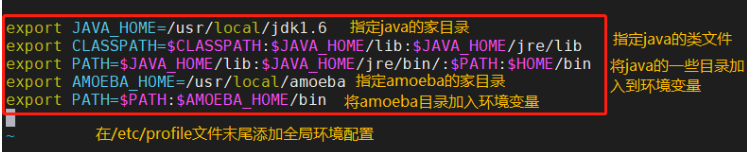
export JAVA_HOME=/usr/local/jdk1.6
export CLASSPATH=$CLASSPATH:$JAVA_HOME/lib:$JAVA_HOME/jre/lib
export PATH=$JAVA_HOME/lib:$JAVA_HOME/jre/bin/:$PATH:$HOME/bin
export AMOEBA_HOME=/usr/local/amoeba
export PATH=$PATH:$AMOEBA_HOME/bin
source /etc/profile
java -version


2����װ Amoeba����
mkdir /usr/local/amoeba
tar zxvf /opt/amoeba-mysql-binary-2.2.0.tar.gz -C /usr/local/amoeba/
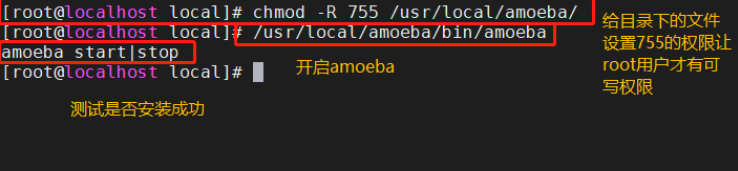
chmod -R 755 /usr/local/amoeba/
/usr/local/amoeba/bin/amoeba
����ʾamoeba start|stop ˵����װ�ɹ�

3�������ӷ�������mysql����Ȩ
����Master��Slave1��Slave2 ��mysql�Ͽ���Ȩ�� Amoeba ����
grant all on *.* to test@'192.168.172.%' identified by '35123512';

һ̨����̨�Ӷ���Ҫ����Ȩ�� Amoeba ��������Ͳ�һһ������
4������ Amoeba��д����,���� Slave �����ؾ���
amoeba����������amoeba����
cd /usr/local/amoeba/conf/
cp amoeba.xml amoeba.xml.bak
vim amoeba.xml #��amoeba�����ļ�
#---------30��------------------------------
<property name="user">amoeba</property>
#---------32��------------------------------
<property name="password">35123512</property>
#---------115��-----------------------------
<property name="defaultPool">master</property>
#---------117ȥ��ע�ͨC------------------------
<property name="writePool">master</property>
<property name="readPool">slaves</property>



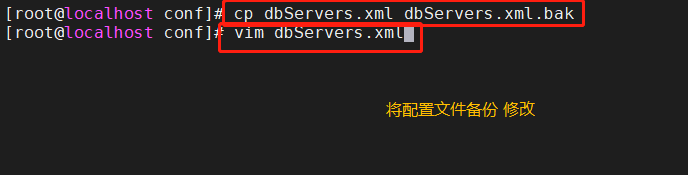
cp dbServers.xml dbServers.xml.bak
vim dbServers.xml
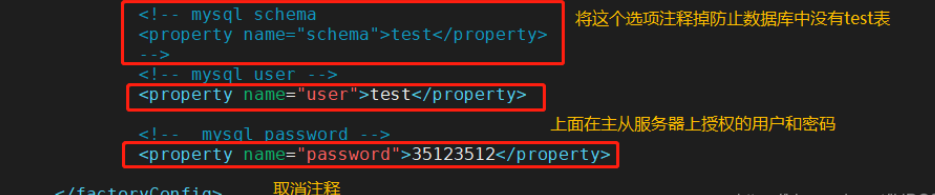
#---------23ע�͵�--------------------------------------
����:Ĭ�Ͻ���test�� �Է�mysql��û��test��ʱ,�ᱨ��
<!-- mysql schema
<property name="schema">test</property>
-->
#---------26��-----------------------------------------
<!-- mysql user -->
<property name="user">test</property>
#---------28-30ȥ��ע��----------------------------------
<property name="password">35123512</property>
#---------45��,����������������Master------------------
<dbServer name="master" parent="abstractServer">
#---------48��,�������������ĵ�ַ----------------------
<property name="ipAddress">192.168.172.10</property>
#---------52��,���ôӷ���������slave1-----------------
<dbServer name="slave1" parent="abstractServer">
#---------55��,���ôӷ�����1�ĵ�ַ---------------------
<property name="ipAddress">192.168.172.20</property>
#---------58��������6��ճ��,���ôӷ�����2����slave2�͵�ַ---
<dbServer name="slave2" parent="abstractServer">
<property name="ipAddress">192.168.172.30</property>
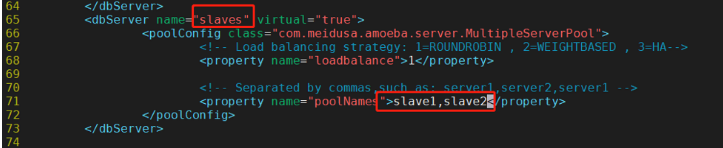
#---------��65��66��-------------------------------------
<dbServer name="slaves" virtual="true">
#---------71��----------------------------------------
<property name="poolNames">slave1,slave2</property>
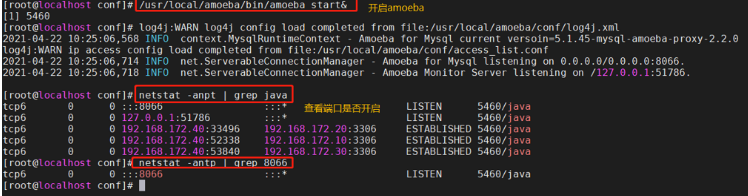
/usr/local/amoeba/bin/amoeba start& #����Amoeba����,��ctrl+c ����
netstat -anpt | grep java #�鿴8066�˿��Ƿ���,Ĭ�϶˿�ΪTCP 8066

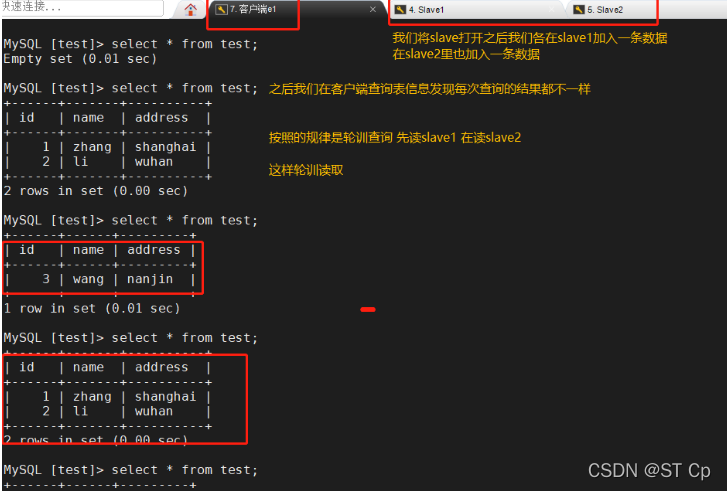
5�����Զ�д����
�ͻ���:192.168.172.50
ʹ��yum���ٰ�װMySQL����ͻ���
yum install -y mysql mysql-server
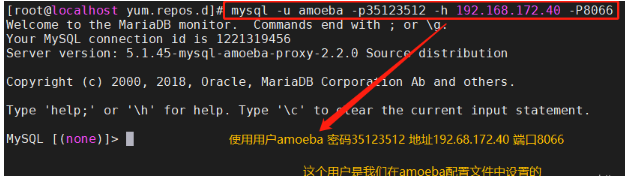
mysql -u amoeba -p35123512 -h 192.168.172.40 -P8066
�ܽ�
mysql���Ӹ���ԭ��
slave�ڵ������ڵ��������,�������ӹ�ϵ,���Ѵ��Ŀ�ʼͬ��,���ĸ���־�ļ���һ�����͵�master
master���ĵ����ݱ��浽binlog��
master����binlog dump�߳�,��binlog��־���͵����ӵ�slave��
slave���ܵ����͵�binlog,slave����IO�߳̽�����д���м���־(relay log)��
slaveͬʱ���Ὺ��һ��SQL�߳�,�Ա��м���־������������,���ҽ���SQL,�ط����ݵ������ݿ���
������:
1.��β鿴����ͬ��״̬�Ƿ�ɹ�
show slave status \G
show master status\G
- ���I/O��sql����yes��,��������Ų��
�ȿ�last errno�м������� ��ʲô����ȵȶ�����Ϣ��ʾ
���粻ͨ
my.cnf����������
���롢file�ļ�����posƫ��������
����ǽû�йر�
3.show slave status \G�ܿ�����Щ��Ϣ(�Ƚ���Ҫ��)
io״̬ �����̵߳�yes
Last_Errno,Last_Error**
slave��SQL�̶߳�ȡ��־�����ĵĴ��������ʹ�����Ϣ����������Ϊ0������ϢΪ���ַ�����ʾû�д���;
���Last_Errorֵ���ǿ�ֵ,��Ҳ���ڴ����������Ĵ�����־����Ϊ��Ϣ��ʾ��
- ���Ӹ�����(�ӳ�)����Щ����
�ӿ�Ӳ���������,���¸����ӳ�
���Ӹ��Ƶ��߳�,�������д����̫��,���������͵��ӿ�,�ͻᵼ���ӳ١����߰汾��mysql
����֧�ֶ��̸߳���
��SQL������
�����ӳ�
master����:�����дѹ����,���¸����ӳ�,�ܹ���ǰ��Ҫ��buffer�������
slave����:һ���������,ʹ�ö�̨slave����̯������,�ٴ���Щslave��ȡһ̨ר�õķ�����,ֻ��Ϊ������,�����������κβ���.
mysql����ͬ����д����������˺�
����ͬ��(���ݿ⻥����Ȩ���˺�)
amoeba(�ͻ��˷���amoeba)
amoeba(amoeba�������ݿ⼯Ⱥ)
û�д���;
���Last_Errorֵ���ǿ�ֵ,��Ҳ���ڴ����������Ĵ�����־����Ϊ��Ϣ��ʾ��

