算法介绍:

上述图片是算法结构图,整体流程和典型的Siamese网络结构相似,但更换了子网络的结构,使用的是VGG-16。
损失函数使用的是两个(比较损失函数和二分类交叉熵损失函数)相加:
L = Lpos + Lneg
Loss = (1 ? y) ? 1 2 (dw )2 + (y) ? 1 2{max (0, m ? dw)} 2
L = ?y log p + (1 ? y)log (1 ? p)
数据集:
开源数据集:
1.?Dr. Joseph Cohen在GitHub上创建的数据集,包括COVID19,呼吸综合征等多个类别的样本,230个患者样本,数据源不断更新。[J. Cohen. COVID-19 image data collection, 2020. https://github.com/ieee8023/ covid-chestxray-dataset]
2. Kaggle上的数据集,有肺炎和健康两种类别,共有5856个样本。[?Chest X-Ray Images (Pneumonia), https://www.kaggle.com/ paultimothymooney/chest-xray-pneumonia]
本文使用的都是CXR images(胸部X光检查图片),从以上两个数据集,分别抽取226个COVID-19[数据集1],健康[数据集2]和肺炎[数据集2],共678个样本用于本次实验。
样本也应用于VGG-16的预训练,数据的划分比例见下表。

D(支持集):包括K类,每类有?N个样本,共有K*N个样本
Q(查询集):来自K个不同类别的多个样本,用于测试模型效果。
训练过程:
预处理:由于数据集中的图像来自不同的地点和不同的临床环境,图像的强度和质量相差很大。然而,我们避免了对数据集中的CXR图像进行大量预处理,从而提高了我们提出的Siamese网络模型的泛化能力。这反过来使我们的模型在从输入图像中提取特征嵌入时,对图像中出现的伪像和噪声更加鲁棒。
1. 将所有图像重新缩放为100 x 100像素的大小,以获得整个数据集的一致图像尺寸。
2. 执行强度归一化,也称为缩放,这是一个重要的预处理任务,以加快模型收敛,消除特征偏差,获得一个均匀的分布的数据集。
3. 利用最小-最大归一化技术将图像像素值[0,255]转换为[0,1],得到一个标准的正态分布。
4. 最后,对所有三个RGB通道的输入图像进行直方图均衡化,以提高图像的对比度。这通常是通过有效地拉伸最常用的强度值来实现的,从而使局部对比度较差的区域获得更好的对比度。
预训练使用Adam优化器,0.0001的初始学习率,后期学习率会使用Keras的ReduceLROnPlateau callback 调整。具体的与训练操作描述在原文中详细写了[5.2. Experimental settings],这里不赘述。
训练过程:
使用tensorflow实现,python3.x

测试过程:
用到的指标:PPV ,TPR,TNR,FPR,F1-score,AUC.
根据算法图中的流程,以及原文中的描述,测试过程“个人理解”为:输入测试样本到一支子网络,得到编码后的特征(记为A),将k类的n个“标准”样本(k-way n-shot)输入一支子网络得到编码特征(记为B),计算A和B的欧式距离,如果距离小于设定的阈值,则测试样本与该标准样本为同一类。
实验设计:
1. 比较不同shot数的结果:设置每类的shot数为7-10.

2. 比较交叉熵损失函数对算法的影响:也设置shot数为7-10,比较不同shot数时交叉熵损失函数的效果。
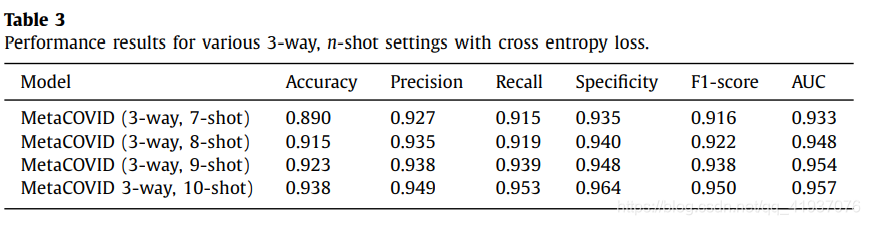
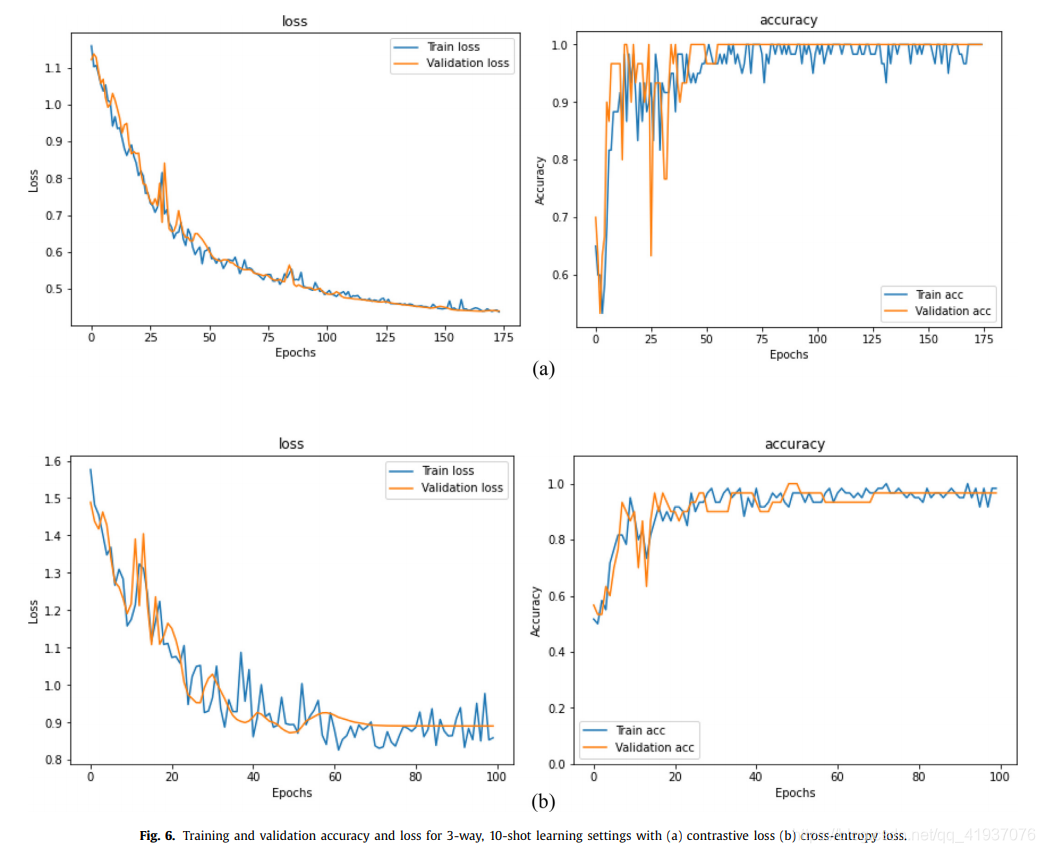
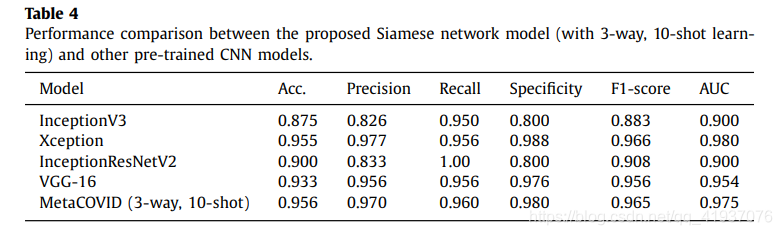
3.比较Siamese网络于其他预训练过的CNN模型
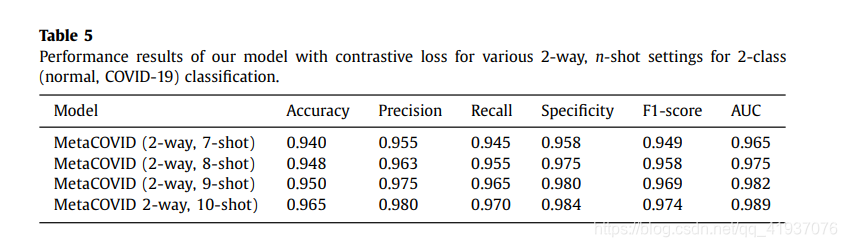
4.将模型应用在二分类上的效果:
总结:
1. 提出的模型具有95.6%的准确性。
2. 提出的模型表现优于那些预训练好的CNN模型。
3.模型缺乏可解释性。