����Ŀ¼
����ѧϰ��Ŀ��
����ѧϰ����
- �ලѧϰ(supervised learning)
- �ලѧϰ(unsupervised learning)
- ǿ��ѧϰ(reinforcement learning)
- ��ලѧϰ(semi-supervised learning)
- ���ѧϰ(deep learning)
python scikit-learn
- һ�����Ч�Ĺ���
- ����python��numpy,scipy��matplotlib��
- ��Դ���ɸ���
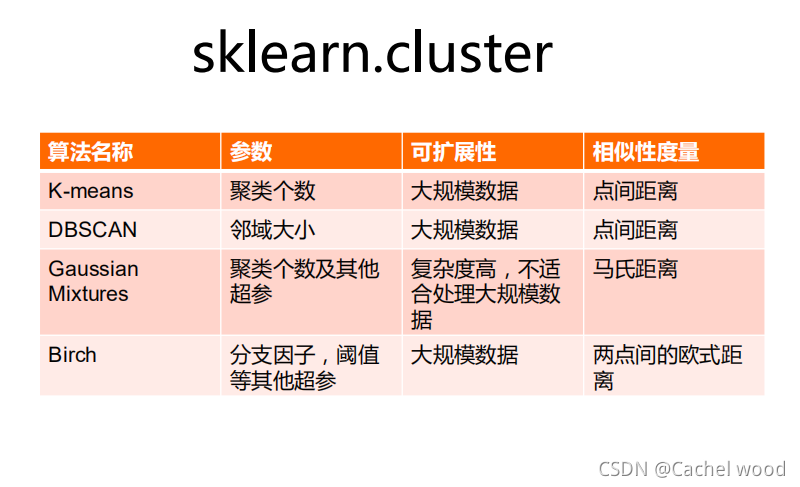
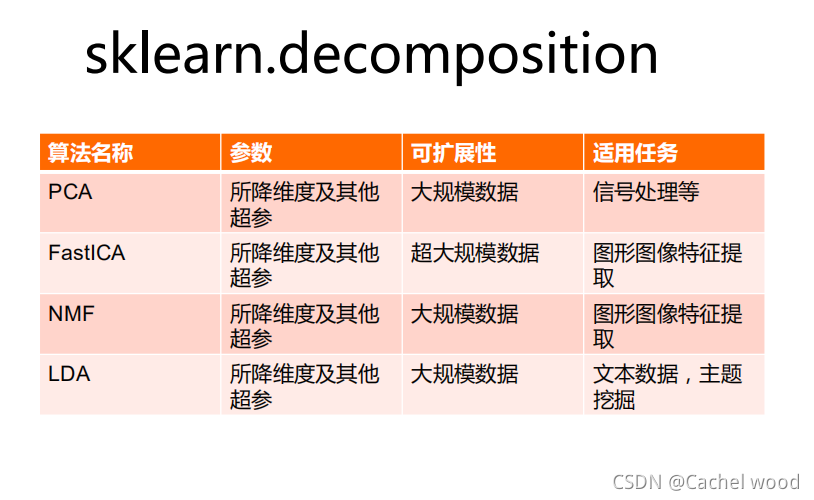
scikit-learn���ú���
| Ӧ�� | �㷨 | |
|---|---|---|
| ����classification | �쳣���,ͼ��ʶ��� | KNN,SVM |
| ����clustering | ͼ��ָ�,Ⱥ�廮�ֵ� | K-means,���� |
| �ع�regression | �۸�Ԥ��,����Ԥ��� | ���Իع�,SVR |
| ��άdimension reduction | ���ӻ� | PCA,NMF |
sklearn��ļ��
�ලѧϰ
�����ޱ�ǩ������ѧϰ���ݵķֲ�������������֮��Ĺ�ϵ�������ලѧϰ��
- �мලѧϰ���ලѧϰ������������������Ƿ��б�ǩ
- �ලѧϰ�Ӧ�õij����Ǿ���clustering�ͽ�άdimension reduction
����clustering
����clustering,���Ǹ������ݵġ������ԡ������ݷ�Ϊ����Ĺ��̡�
����������ͬ����֮��ġ������ԡ�,ͨ��ʹ�õķ������Ǽ�����������֮��ġ����롱��ʹ�ò�ͬ�ķ�������������ľ�����ϵ���������ĺû���
ŷʽ����
d = �� k = 1 n ( x 1 k ? x 2 k ) 2 d = \sqrt{\sum_{k=1}^n (x_{1k}-x_{2k})^2} d=��k=1n?(x1k??x2k?)2?
�����پ���
d = �� k = 1 n �O x 1 k ? x 2 k �O d = \sum_{k=1}^n |x_{1k}-x_{2k}| d=��k=1n?�Ox1k??x2k?�O
���Ͼ���
d ( x i , x j ) = ( x i ? x j ) T s ? 1 ( x i ? x j ) d(x_i,x_j) = \sqrt{(x_i-x_j)^Ts^{-1}(x_i-x_j)} d(xi?,xj?)=(xi??xj?)Ts?1(xi??xj?)?
�����
cos(\theta) = \frac{}{}
��ά
��֤���������еĴ��������Ի��߷ֲ��������,����ά����ת��Ϊ��ά���ݵĹ���:
- ���ݵĿ��ӻ�
- ��������
k-means�����㷨
��kΪ����,��n������ֳ�k����,ʹ���ھ��нϸߵ����ƶ�,���ؼ�����ƶȽϵ͡�
�䴦����������:
- ���ѡ��k������Ϊ��ʼ�ľ�������;
- ����ʣ�µĵ�,��������������ĵľ���,�����������Ĵء�
- ��ÿ����,�������е�ľ�ֵ��Ϊ�µľ�������
- �ظ�2��3ֱ���������IJ��ٷ����ı�
DBSCAN�ܶȾ���
- �����ʱ����ҪԤ��ָ���صĸ���
- ���յĴصĸ�������
DBSCAN�㷨�����ݵ��Ϊ����:
- ���ĵ�:�ڰ뾶eps�ں��г���MinPts��Ŀ�ĵ�
- �߽��:�ڰ뾶eps�ڵ������С��MinPts,�������ں��ĵ��������
- ������:�Ȳ��Ǻ��ĵ�Ҳ���DZ߽��ĵ�
PCA��������Ӧ��
- ���ɷַ���(principal component analysis,PCA)����õ�һ�ֽ�ά����,ͨ�����ڸ�ά���ݼ���̽������ӻ�,��������������ѹ����Ԥ�����ȡ�
- PCA���Ѿ�������Եĸ�ά�����ϳ�Ϊ�����صĵ�ά����,��Ϊ���ɷ֡����ɷ��ܹ������ܱ���ԭʼ���ݵ���Ϣ��
ԭ��:��������ɷ־�����Э��������Ӧ��������,���ն�Ӧ������ֵ��С��������,��������ֵ���ǵ�һ���ɷ�,����ǵڶ����ɷ�,�Դ����ơ�
�Ǹ�����ֽ�(NMF)
Non-negative Matrix Factorization, NMF���ھ���������Ԫ�ؾ�Ϊ�Ǹ���Լ������֮�µľ���ֽⷽ����
����˼��:����һ���Ǹ�����V,NMF�ܹ��ҵ�һ���Ǹ�����W��һ���Ǹ�����H,ʹ�þ���W��H�ij˻����Ƶ��ھ���V�е�ֵ��
V n ? m = W n ? k ? H k ? m V_{n*m} = W_{n*k} * H_{k*m} Vn?m?=Wn?k??Hk?m?
���ھ���ġ�ͼ��ָʵ��
ͼ��ָ�:����ͼ��ĻҶȡ���ɫ����������״������,��ͼ��ֳ����ɸ������ص�������,��ʹ��Щ������ͬһ�����ڳ���������,�ڲ�ͬ������֮��������ԵIJ����ԡ�Ȼ��Ϳ��Խ��ָ��ͼ���о��ж������ʵ�������ȡ�������ڲ�ͬ���о���
ͼ��ָ�÷���:
- ��ֵ�ָ�:��ͼ��Ҷ�ֵ���ж���,���ò�ͬ������ֵ,�ﵽ�ָ��Ŀ�ġ�
- ��Ե�ָ�:��ͼ���Ե���м��,�����ͼ���лҶ�ֵ��������ĵط�,��ΪһƬ����ı�Ե��
- ֱ��ͼ��:��ͼ�����ɫ����ֱ��ͼ,��ֱ��ͼ�IJ��岨���ܹ���ʾһ���������ɫֵ�ķ�Χ,���ﵽ�ָ��Ŀ�ġ�
- �ض�����:���ھ��������С���任���������ͼ��ָ
�ලѧϰ
����һ����б�ǩ������,ѧϰ�����뵽�����ӳ��,Ȼ������ӳ���ϵӦ�õ�λ��������,�ﵽ�����ع��Ŀ�ġ�
����:���������ɢ��,ѧϰ����Ϊ��������
�ع�:�������������,ѧϰ����Ϊ�ع�����
����ѧϰ
����:һ���б�ǩ��ѵ������(Ҳ�ƹ۲������),��ǩ��������Щ����(�۲�)���������
���:����ģ������Щѵ������,ѵ���Լ���ģ�Ͳ���,ѧϰ��һ���ʺ��������ݵķ�����,����������(��ѵ������)��Ҫ��������ж�,�Ϳ��Խ�������������Ϊ������ѧ�õķ����������жϡ�
�ع����
ͳ��ѧ�������ݵķ���,Ŀ�������˽����������������Ƿ���ء��о�����ط�����ǿ��,��������ѧģ���Ա�۲��ض�������Ԥ���о��߸���Ȥ�ı������ع���������������˽����Ա����仯ʱ������ı仯����