����Ŀ¼
1. ����
opencv�м����˻���libsvm1ʵ�ֵ�SVM�ӿ�,����ֱ�ӽ����Ӿ���������
�������ݴ����Ϳ��ӻ�������˵,������python�ӿ�opencv��SVM����ֱ�۷��㡣
ѵ����ģ�ͺ�,��SVMģ�ͱ���Ϊxml,������ʵʱ��Ӧ����ͨ��C++�ӿڵ��ò����ļ�,����ʵʱ�ƶϡ�
�ڷǾ��������ķ���ѵ����,��opencv��SVMĬ�ϵ�train����,�����·�����ƫ������������,��ʱ���Բ���trainAuto��������ƽ�⡣
������SVM��ԭ����һ���˽�,����ֱ����ת��3��4С�ڡ�
2. ����ԭ��
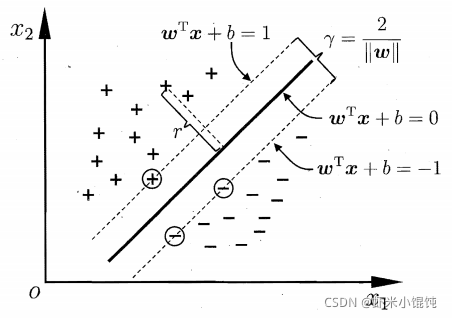
SVMּ���ҵ�һ�����ֳ�ƽ��,ʹ�û��ֺ�ķ���������³����,��δ�������������������2��
�������ռ���,���ֳ�ƽ�������������̽�������: w T x + b = 0 \boldsymbol{w}^T\boldsymbol{x}+b=0 wTx+b=0,���� w = ( w 1 ; w 2 ; . . . ; w d ) \boldsymbol{w}=(w_1;w_2;...;w_d) w=(w1?;w2?;...;wd?)Ϊ������,������ƽ��ķ���,bΪλ����,������ƽ����ԭ��֮��ľ��롣
�������Կɷֵ������ռ�,��Ҫ�ҵ����������(maximum margin)�Ļ��ֳ�ƽ��,���ҵ���ʹ��ʽ��IJ���
w
\boldsymbol{w}
w��b2:
min
?
w
,
b
1
2
�O
�O
w
�O
�O
2
\min_{w,b}{\frac{1}{2}||\boldsymbol{w}||^2}
w,bmin?21?�O�Ow�O�O2s.t.
y
i
(
w
T
x
i
+
b
)
��
1
,
i
=
1
,
2
,
.
.
.
,
m
y_i(\boldsymbol{w}^T\boldsymbol{x_i}+b)��1,i=1,2,...,m
yi?(wTxi?+b)��1,i=1,2,...,m
�������Բ��ɷֵ������ռ�,���Խ�������ԭʼ�ռ�ӳ�䵽��һ����ά�����ռ�,�Ӷ�ʹ��������������ռ������Կɷ֡����������ռ��ά�����ܸܺ�,���Լ���,����ͨ������˺���,���Խ���ά�����ռ��е��ڻ�(dot product)ת��Ϊ��ά�����ռ��е�ͨ���˺�������Ľ����
���ú˺���2:

Ϊ�˼��ٹ����,���������(soft margin)����,����֧����������һЩ�����ϳ���:
y
i
(
w
T
x
i
+
b
)
��
1
y_i(\boldsymbol{w}^T\boldsymbol{x_i}+b)��1
yi?(wTxi?+b)��1
�ò���C��Լ���������������,�ɳڱ��� �� i ��_i ��i?��ʾѵ�����������Ӧ����ȷ���߽߱�ľ���,���ڷ�����ȷ���������뼴Ϊ03��

�Ż��������Ϊ:
m
i
n
w
,
b
0
�O
�O
w
�O
�O
2
+
C
��
i
��
i
min_{\boldsymbol{w},b_0}{||\boldsymbol{w}||^2+C\sum_i{��_i}}
minw,b0??�O�Ow�O�O2+Ci��?��i?
s.t. y i ( w T x i + b 0 ) �� 1 ? �� i , �� �� i �� 0 ? i y_i(\boldsymbol{w}^T\boldsymbol{x_i}+b_0)��1-��_i,�Ҧ�_i��0 ?i yi?(wTxi?+b0?)��1?��i?,����i?��0?i
3. ��������
SVM����opencv�еļ̳й�ϵ��ͼ��ʾ4:

SVM�̳���StatModel��Algorithm�ࡣ
��opencv��ʹ��SVM��һ����������:
����ģ��
C++:
static Ptr<SVM> cv::ml::SVM::create()
Python:
cv.ml.SVM_create() -> retval
����ģ������
C++:
enum Types {
C_SVC =100,//C-֧���������ࡣn������(n�� 2) ����ʹ���쳣ֵ�ijͷ����� C ����ȫ�ط����ࡣ
NU_SVC =101,//��-֧���������ࡣn������,�����в������ķ��롣���������ڴ���C,��������0-1��Χ��,ֵԽ��,���߽߱�Խƽ����
ONE_CLASS =102,//�ֲ�����,���е�ѵ�����ݶ�����ͬһ����,SVM ������һ���߽�,�����������ռ�����ಿ�ַֿ���
EPS_SVR =103,//��-֧�������ع顣����ѵ������������������ϳ�ƽ��֮��ľ������С��p�������쳣ֵ,ʹ�óͷ����� C��
NU_SVR =104 // ��-֧�������ع顣 �����ڴ��� p��
}
virtual void cv::ml::SVM::setType(int val)
Python:
cv.ml_SVM.setType(val) ->None
����C
����"2.����ԭ��"�жԲ���C�Ľ���,����Ӧ��������ò���C?
- �ϴ�� Cֵ����������������ٵ�������С�Ľ�����������ǵ�����������·�����������Ĵ��ۺܸߡ������Ż���Ŀ������С������,����������ֺ��ٵ���������
- ��С��Cֵ�����˾��и�����������������Ľ�������������������,��С�����ῼ����ô����ܺ���,�������������Ѱ�Ҿ��д������ij�ƽ�档
C++:
//����C
virtual void cv::ml::SVM::setC(double val)
python:
cv.ml_SVM.setC(val) -> None
���ú˺���
C++:
enum KernelTypes {
CUSTOM =-1,//��SVM::getKernelType����,Ĭ����RBF
LINEAR =0,//�����ں�,�ٶ����
POLY =1,//����ʽ��
RBF =2,//���������(RBF),�����������Ǹ�������ѡ��
SIGMOID =3,//sigmoid��
CHI2 =4,//Chi2��,������RBF��
INTER =5//ֱ��ͼ�����,�ٶȽϿ�
}
virtual void cv::ml::SVM::setKernel(int kernelType)
python:
cv.ml_SVM.setKernel(kernelType) -> None
���õ����㷨����ֹ��
C++:
virtual void cv::ml::SVM::setTermCriteria(const cv::TermCriteria &val)
// cv::TermCriteria
cv::TermCriteria::TermCriteria (int type,int maxCount,double epsilon)
// Type
enum cv::TermCriteria::Type {
COUNT =1,
MAX_ITER =COUNT,//����������
EPS =2 //�����㷨ֹͣʱ����ľ��Ȼ�����仯
}
python:
cv.ml_SVM.setTermCriteria(val) ->None
ѵ��SVMģ��
trainAuto����ͨ��ѡ����Ѳ��� C��gamma��p��nu��coef0��degree ���Զ�ѵ�� SVM ģ�͡������Լ����Ľ�����֤������Сʱ,��������Ϊ����ѵġ��˺�����ʹ��SVM::getDefaultGrid���в����Ż�,��˽��ṩ�����IJ���ѡ�
trainAuto���������ڷ���(SVM::C_SVC��SVM::NU_SVC)�Լ��ع�(SVM::EPS_SVR��SVM::NU_SVR)�������SVM::ONE_CLASS,�����Ż�,��ִ�д��� params ��ָ�������ij��� SVM��
C++:
//������TrainData::create��TrainData::loadFromCSV�����ѵ������
virtual bool cv::ml::SVM::trainAuto(const Ptr<TrainData> & data,
int kFold = 10,
ParamGrid Cgrid = getDefaultGrid(C),
ParamGrid gammaGrid = getDefaultGrid(GAMMA),
ParamGrid pGrid = getDefaultGrid(P),
ParamGrid nuGrid = getDefaultGrid(NU),
ParamGrid coeffGrid = getDefaultGrid(COEF),
ParamGrid degreeGrid = getDefaultGrid(DEGREE),
bool balanced = false
)
//����ѵ������
bool cv::ml::SVM::trainAuto(InputArray samples,
int layout,
InputArray responses,
int kFold = 10,
Ptr< ParamGrid > Cgrid = SVM::getDefaultGridPtr(SVM::C),
Ptr< ParamGrid > gammaGrid = SVM::getDefaultGridPtr(SVM::GAMMA),
Ptr< ParamGrid > pGrid = SVM::getDefaultGridPtr(SVM::P),
Ptr< ParamGrid > nuGrid = SVM::getDefaultGridPtr(SVM::NU),
Ptr< ParamGrid > coeffGrid = SVM::getDefaultGridPtr(SVM::COEF),
Ptr< ParamGrid > degreeGrid = SVM::getDefaultGridPtr(SVM::DEGREE),
bool balanced = false
)
Python:
cv.ml_SVM.trainAuto(samples, layout, responses[, kFold[, Cgrid[, gammaGrid[, pGrid[, nuGrid[, coeffGrid[, degreeGrid[, balanced]]]]]]]]) -> retval
����:
- samples:ѵ������
- layout:�ο� ml::SampleTypes,��cv.ml.ROW_SAMPLE��ʾÿ��ѵ��������������,cv.ml.COL_SAMPLE��ʾÿ��ѵ��������������
- responses:��ѵ�������йص���Ӧ����
- kFold:k������֤,ѵ������ֳ�k���Ӽ�,����ѡȡһ����������,ʣ��k-1������ѵ��
- balanced:�����ΪTrue����2-class��������,�������Զ�������ƽ��Ľ�����֤�Ӽ�,���Ӽ��е���֮������ӽ�����ѵ�����ݼ��еı���
Ԥ����
C++:
// Ԥ��������������Ӧ���
virtual float predict(
InputArray samples, // input samples, float matrix
OutputArray results = cv::noArray(), // optional output results matrix
int flags = 0 // (model-dependent)
) const = 0;
python:
cv.ml_StatModel.predict(samples[, results[, flags]]) ->retval, results
������
���ڻع�ģ��,������Ϊ RMS;���ڷ�����,������Ϊ������������İٷֱ� (0%-100%)��
C++:
// ��ѵ��������Լ��ϼ������
virtual float calcError(
const Ptr<TrainData>& data, // training samples
bool test, // true: compute over test set
// false: compute over training set
cv::OutputArray resp // the optional output responses
) const;
python:
cv.ml_StatModel.calcError(data, test[, resp]) ->retval, resp
����SVMģ��
C++:
void cv::Algorithm::save(const String &filename) const
Python:
cv.Algorithm.save(filename) ->None
���ļ��м���SVM
C++:
static Ptr<SVM> cv::ml::SVM::load(const String &filepath)
Python:
cv.ml.SVM_load(filepath) ->retval
4. ʾ������
�ٷ�ʾ��(python)

��������,����ģ��ѵ�����е��������:
from __future__ import print_function
import cv2 as cv
import numpy as np
import random as rng
import time
from matplotlib import pyplot as plt
NTRAINING_SAMPLES = 100 # ÿ������ѵ��������
FRAC_LINEAR_SEP = 0.9 # ���Կɷֵ���������
# ���������ݿ��ӻ�
WIDTH = 512
HEIGHT = 512
I = np.zeros((HEIGHT, WIDTH, 3), dtype=np.uint8)
# ����ѵ������
trainData = np.empty((2*NTRAINING_SAMPLES, 2), dtype=np.float32)
labels = np.empty((2*NTRAINING_SAMPLES, 1), dtype=np.int32)
rng.seed(100) # Random value generation class
# ���Կɷֵ�ѵ����������
nLinearSamples = int(FRAC_LINEAR_SEP * NTRAINING_SAMPLES)
## [setup1]
# ����class 1�������,������x������[0, 0.4),y������ [0, 1)
trainClass = trainData[0:nLinearSamples,:]
# The x coordinate of the points is in [0, 0.4)
c = trainClass[:,0:1]
c[:] = np.random.uniform(0.0, 0.4 * WIDTH, c.shape)
# The y coordinate of the points is in [0, 1)
c = trainClass[:,1:2]
c[:] = np.random.uniform(0.0, HEIGHT, c.shape)
# ����class 2�������,������x������[0.6, 1],y������ [0, 1)
trainClass = trainData[2*NTRAINING_SAMPLES-nLinearSamples:2*NTRAINING_SAMPLES,:]
# The x coordinate of the points is in [0.6, 1]
c = trainClass[:,0:1]
c[:] = np.random.uniform(0.6*WIDTH, WIDTH, c.shape)
# The y coordinate of the points is in [0, 1)
c = trainClass[:,1:2]
c[:] = np.random.uniform(0.0, HEIGHT, c.shape)
# �������Բ��ɷֵ�ѵ������
# Generate random points for the classes 1 and 2
trainClass = trainData[nLinearSamples:2*NTRAINING_SAMPLES-nLinearSamples,:]
# x������ [0.4, 0.6),y������[0, 1)
c = trainClass[:,0:1]
c[:] = np.random.uniform(0.4*WIDTH, 0.6*WIDTH, c.shape)
c = trainClass[:,1:2]
c[:] = np.random.uniform(0.0, HEIGHT, c.shape)
# ������������label
labels[0:NTRAINING_SAMPLES,:] = 1 # Class 1
labels[NTRAINING_SAMPLES:2*NTRAINING_SAMPLES,:] = 2 # Class 2
����SVM����,��ʼ��ģ��:
print('Starting training process')
svm = cv.ml.SVM_create()
svm.setType(cv.ml.SVM_C_SVC)
svm.setC(0.1)
svm.setKernel(cv.ml.SVM_LINEAR)
svm.setTermCriteria((cv.TERM_CRITERIA_MAX_ITER, int(1e7), 1e-6))
ѵ��SVM:
## ѵ��
svm.train(trainData, cv.ml.ROW_SAMPLE, labels)
print('Finished training process')
## ��ʾ��������
green = (0,100,0)
blue = (100,0,0)
for i in range(I.shape[0]):
for j in range(I.shape[1]):
sampleMat = np.matrix([[j,i]], dtype=np.float32)
response = svm.predict(sampleMat)[1]
if response == 1:
I[i,j] = green
elif response == 2:
I[i,j] = blue
��ѵ���������������������п��ӻ�:
## ��������ɫԲȦ��ʾclass 1��class 2��ѵ������
thick = -1
# Class 1
for i in range(NTRAINING_SAMPLES):
px = trainData[i,0]
py = trainData[i,1]
cv.circle(I, (px, py), 3, (0, 255, 0), thick)
# Class 2
for i in range(NTRAINING_SAMPLES, 2*NTRAINING_SAMPLES):
px = trainData[i,0]
py = trainData[i,1]
cv.circle(I, (px, py), 3, (255, 0, 0), thick)
# ��ʾ֧������(
## [show_vectors]
thick = 2
sv = svm.getUncompressedSupportVectors()
for i in range(sv.shape[0]):
cv.circle(I, (sv[i,0], sv[i,1]), 6, (128, 128, 128), thick)
## [show_vectors]
#cv.imwrite('result.png', I) # save the Image
#cv.imshow('SVM for Non-Linear Training Data', I) # show it to the user
plt.imshow(I)
������(C++�汾)
void test_svm(std::string videopath, std::string svm_file = "svm.mat")
{
/// ����svmģ�Ͳ���
cv::Ptr<cv::ml::SVM> svm = cv::ml::SVM::load(svm_file);
/// ��ʼ��������ȡ��
// �˴�ʡ�ԡ���
cv::VideoCapture cap(videopath);
if (cap.isOpened())
{
cv::Mat src;//img
int sleep_interval = 1;//ÿ������msȡ֡
int frameIdx = 0;
while (true)
{
if (!cap.read(src))
{
break;
}
frameIdx++;
double start = static_cast<double>(cv::getTickCount());
cv::Mat flowFeat;
//��ȡ�˶�����
m_featureExtactor.ProcessFlow(src, flowFeat);
flowFeat.convertTo(flowFeat, CV_32FC1);
//��ȡ������
int response = (int)svm->predict(flowFeat);
cv::putText(src, cv::String(std::to_string(response)), cv::Point(20,20), cv::FONT_HERSHEY_PLAIN, 1, cv::Scalar(0, 255, 0));
//�����ʱ
float times = ((float)cv::getTickCount() - start) / cv::getTickFrequency();
std::cout << "time cost: " << times << " s." << std::endl;
cv::imshow("img", src);
if (cv::waitKey(1) == 27) {
break;
}
}
}
}
5. ��
����������Opencv��SVM֧����������ԭ���������ʹ���ʾ����
��������а����Ļ�,��ӭһ������֧���²���~