������Դ��ML-Agents�ٷ���ʾ��,Github��ַ:https://github.com/Unity-Technologies/ml-agents,��������ϸ�������⡣
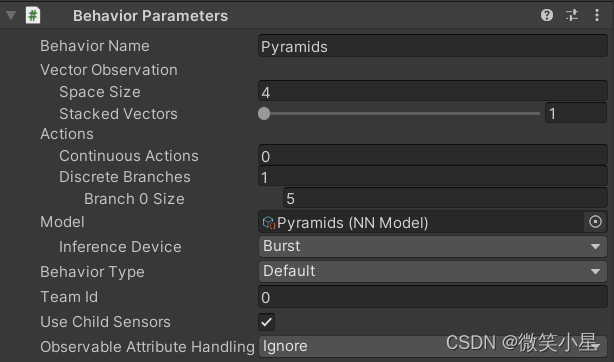
���Ļ�����ǰ�淢����ƪ����,��Ҫ��ML-Agents��һ�����˽�,�������:Unityǿ��ѧϰ֮ML-Agents��ʹ����ML-Agents������ô�ȫ��
��ǰ������������:
Unity�˹�����֮�������ҽ���������������

����˵��
�������Ļ���Ҫ���������˺ܶ,������Ҫ������൱��Ļ�����ȥѰ��һ����ɫ�ķ���,������λ��һ���������Ķ���,��Ҫ��������������Ҫ�Ƶ�������,���������ͷ��鲻��һ��ʼ���е�,����Ҫ������ť�Ż����������ص�,��ť��ˢ���������λ�á������������Ҫ�������,����Ҫ����Ѱ�Ұ�ť�C>������ť�C>Ѱ�ҽ������C>�Ƶ��������C>������ɫ����,�⼸������,����ĸ��Ӻͻ������Ӵ��ѵ����һ���൱�����ս��
���ڽ���̫��ϡ��,��ε��������ʹ��������Ѱ�������Ǽ��������ܵõ�һ���õĽ����,�������������ҪӦ�õ�һ�������Ļ���,(Curiosity),ʹ����������̽��δ֪�����еõ�����,������Ч�ƶ�ѵ���Ľ�չ��
״̬����:
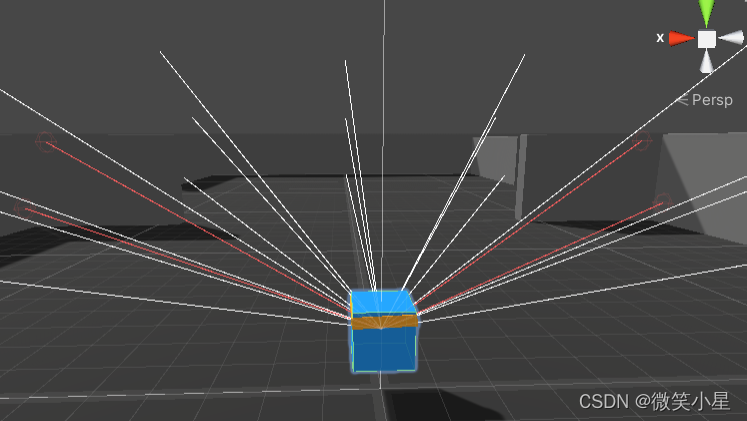
���Կ���,��������������ߴ�����Ray Perception Sensor 3D,����ʹ��������,�Ի�������µ������ӽ�,�����������ÿһ�㶼����������,�ܹ���21������,ÿһ�������ı�ǩ��ǽ�ڡ�Ŀ���������ʯͷ����ͨ��������ʯͷ��Ŀ�귽�顢�պϵĿ��ء��Ͽ��Ŀ��ء���������ͼ�����ڸô���������ϸ˵����ML-Agents����֮��������Ϸ�������������ڲ�����ֻ��ϸ���
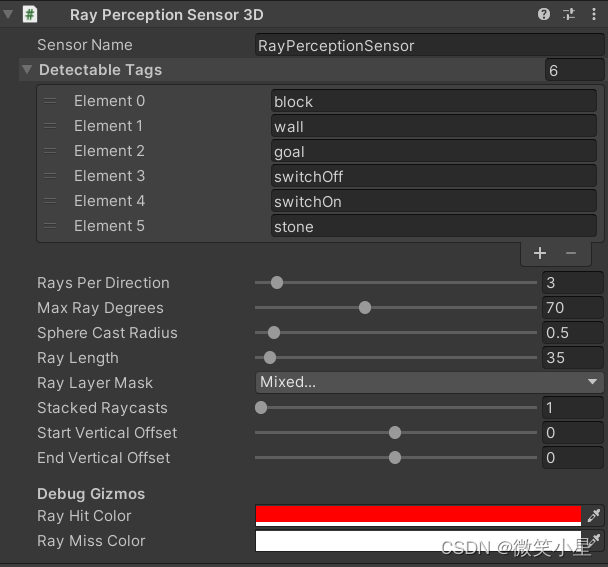


�������ߴ�����������֮��,�����к����ĸ�����ά��,�ֱ�����������ٶ�(��ά,Local Space),�����Ƿ�պϡ�
�������:
���ֻ��һ����ɢ�Ķ���,�������ֵ,�ֱ���ʲô������,��ǰ��,�����,��ת,��ת�����ٵ�������������縴�Ӷ�,����ѵ��ʱ�䡣ȱ����ͬһʱ��ֻ��ִ��һ������,����������������,���粻��ͬʱǰ������ת��
���뽲��
���������PyramidAgent.cs:
��ʼ������Initialize():
public override void Initialize()
{
// ��ȡ����
m_AgentRb = GetComponent<Rigidbody>();
// ��ȡ�������������Ľű�
m_MyArea = area.GetComponent<PyramidArea>();
// ��ȡ���صĽű�
m_SwitchLogic = areaSwitch.GetComponent<PyramidSwitch>();
}
״̬���뷽��CollectObservations:
public override void CollectObservations(VectorSensor sensor)
{
if (useVectorObs)
{
// ���뿪�ص�״̬
sensor.AddObservation(m_SwitchLogic.GetState());
// ������������ٶ�����
sensor.AddObservation(transform.InverseTransformDirection(m_AgentRb.velocity));
}
}
�����������OnActionReceived:
public override void OnActionReceived(ActionBuffers actionBuffers)
{
// ����ʱ��ͷ�,�������ٽ�����Ϸ
AddReward(-1f / MaxStep);
MoveAgent(actionBuffers.DiscreteActions);
}
public void MoveAgent(ActionSegment<int> act)
{
var dirToGo = Vector3.zero;
var rotateDir = Vector3.zero;
// ��������������
var action = act[0];
// �������
switch (action)
{
case 1:
dirToGo = transform.forward * 1f;
break;
case 2:
dirToGo = transform.forward * -1f;
break;
case 3:
rotateDir = transform.up * 1f;
break;
case 4:
rotateDir = transform.up * -1f;
break;
}
// ִ�����
transform.Rotate(rotateDir, Time.deltaTime * 200f);
m_AgentRb.AddForce(dirToGo * 2f, ForceMode.VelocityChange);
}
��һ��episode��ʼʱִ�з���OnEpisodeBegin():
// �����ǰ��Ҫ�������
using System.Linq;
public override void OnEpisodeBegin()
{
// ȡ0-9������˳��
var enumerable = Enumerable.Range(0, 9).OrderBy(x => Guid.NewGuid()).Take(9);
var items = enumerable.ToArray();
// ��������,���ٳ��������н�����(������*������)
m_MyArea.CleanPyramidArea();
// �������ٶȹ���
m_AgentRb.velocity = Vector3.zero;
// ���Լ���λ�÷ŵ�items[0]������
m_MyArea.PlaceObject(gameObject, items[0]);
// ����Լ�����תrotation
transform.rotation = Quaternion.Euler(new Vector3(0f, Random.Range(0, 360)));
// ���ð�ť(�ص�δ����״̬,λ�����)
m_SwitchLogic.ResetSwitch(items[1], items[2]);
// ��������ʯͷ������
m_MyArea.CreateStonePyramid(1, items[3]);
m_MyArea.CreateStonePyramid(1, items[4]);
m_MyArea.CreateStonePyramid(1, items[5]);
m_MyArea.CreateStonePyramid(1, items[6]);
m_MyArea.CreateStonePyramid(1, items[7]);
m_MyArea.CreateStonePyramid(1, items[8]);
}
��ײ���OnCollisionEnter����:
void OnCollisionEnter(Collision collision)
{
// �������Ŀ�귽��,��ô��Ϸ����,��2��
if (collision.gameObject.CompareTag("goal"))
{
SetReward(2f);
EndEpisode();
}
}
���ڿ����µĽű�PyramidSwitch.cs:
// ��ʼ��,��ȡ�������еĽű�
void Start()
{
m_Area = gameObject.transform.parent.gameObject;
m_AreaComponent = m_Area.GetComponent<PyramidArea>();
}
���ÿ��ط���:
public void ResetSwitch(int spawnAreaIndex, int pyramidSpawnIndex)
{
// �ѿ��ط��õ�ָ��λ��
m_AreaComponent.PlaceObject(gameObject, spawnAreaIndex);
// �趨����״̬Ϊ�Ͽ�
m_State = false;
m_PyramidIndex = pyramidSpawnIndex;
tag = "switchOff";
// ��ת����
transform.rotation = Quaternion.Euler(0f, 0f, 0f);
// ���ʱ��δ������״̬
myButton.GetComponent<Renderer>().material = offMaterial;
}
��ײ���:
void OnCollisionEnter(Collision other)
{
// ������δ�Ŀ���,���ر�Ϊ��״̬,������һ��������
if (other.gameObject.CompareTag("agent") && m_State == false)
{
myButton.GetComponent<Renderer>().material = onMaterial;
m_State = true;
// ������*������
m_AreaComponent.CreatePyramid(1, m_PyramidIndex);
tag = "switchOn";
}
}
���������Ŀ��ƽű�PyramidArea.cs:
��������(������Unity�༭�������ɸ���):
public GameObject pyramid;
public GameObject stonePyramid;
// ������������
public GameObject[] spawnAreas;
public int numPyra;
public float range;
�������ֽ������ķ���:
public void CreatePyramid(int numObjects, int spawnAreaIndex)
{
CreateObject(numObjects, pyramid, spawnAreaIndex);
}
public void CreateStonePyramid(int numObjects, int spawnAreaIndex)
{
CreateObject(numObjects, stonePyramid, spawnAreaIndex);
}
void CreateObject(int numObjects, GameObject desiredObject, int spawnAreaIndex)
{
for (var i = 0; i < numObjects; i++)
{
// ���ɽ�����,������Ϊ�������������
var newObject = Instantiate(desiredObject, Vector3.zero,
Quaternion.Euler(0f, 0f, 0f), transform);
// �ƶ���������ָ��λ��
PlaceObject(newObject, spawnAreaIndex);
}
}
�ƶ�������:
public void PlaceObject(GameObject objectToPlace, int spawnAreaIndex)
{
// ����������
var spawnTransform = spawnAreas[spawnAreaIndex].transform;
var xRange = spawnTransform.localScale.x / 2.1f;
var zRange = spawnTransform.localScale.z / 2.1f;
// λ���ڷ�Χ����һ�������
objectToPlace.transform.position = new Vector3(Random.Range(-xRange, xRange), 2f, Random.Range(-zRange, zRange))
+ spawnTransform.position;
}
�������еĽ�����:
public void CleanPyramidArea()
{
foreach (Transform child in transform)
if (child.CompareTag("pyramid"))
{
Destroy(child.gameObject);
}
}
�����ļ�
����1:
behaviors:
Pyramids:
trainer_type: ppo
hyperparameters:
batch_size: 128
buffer_size: 2048
learning_rate: 0.0003
beta: 0.01
epsilon: 0.2
lambd: 0.95
num_epoch: 3
learning_rate_schedule: linear
network_settings:
normalize: false
hidden_units: 512
num_layers: 2
vis_encode_type: simple
reward_signals:
extrinsic:
gamma: 0.99
strength: 1.0
curiosity:
gamma: 0.99
strength: 0.02
network_settings:
hidden_units: 256
learning_rate: 0.0003
keep_checkpoints: 5
max_steps: 10000000
time_horizon: 128
summary_freq: 30000
���������������,��ͬ�ĵط����ڽ����źŵ����ö���һ��Curiosity,Ҳ���Ǻ����Ľ����ź�,��������ź��ڱ���Ŀ���DZ����,ͨ�����轱�������������ڻ�����̽��������,��������ʹ��������ϡ�轱���Ļ�����˳��ѵ��,���������:
curiosity:
gamma: 0.99
strength: 0.02
network_settings:
hidden_units: 256
learning_rate: 0.0003
gamma:�ۿ�����,������δ�������������ڵ�״̬��������ֵ��Ӱ��̶ȡ��Ƽ�:0.8-0.995��
strength:������ģ������Ľ�����С,Ӧ������㹻��ʹ�䲻�������Ľ�����û,��Ҳ������ù�������û�����Ľ������Ƽ�:0.001-0.1��Ĭ��Ϊ1��
hidden_units:��������������ز�ڵ������
learning_rate:ѧϰ��,���ڸ��º�����ģ��,���ѵ�����ȶ�,Ӧ����С���Ƽ�:1e-5 - 1e-3��

����Curiosity�ľ��彲����鿴:
ǿ��ѧϰ����Intrinsic Curiosity Module
����2:
behaviors:
Pyramids:
trainer_type: ppo
hyperparameters:
batch_size: 128
buffer_size: 2048
learning_rate: 0.0003
beta: 0.01
epsilon: 0.2
lambd: 0.95
num_epoch: 3
learning_rate_schedule: linear
network_settings:
normalize: false
hidden_units: 512
num_layers: 2
vis_encode_type: simple
reward_signals:
extrinsic:
gamma: 0.99
strength: 1.0
rnd:
gamma: 0.99
strength: 0.01
network_settings:
hidden_units: 64
num_layers: 3
learning_rate: 0.0001
keep_checkpoints: 5
max_steps: 3000000
time_horizon: 128
summary_freq: 30000
���Կ���,�ڶ������ò�ͬ�ĵط�����û��ʹ��Curiosity��������,ʹ��������һ�ֽ�������,������Random Network Distillation,����Ϊ�����������,���RND��
rnd:
gamma: 0.99
strength: 0.01
network_settings:
hidden_units: 64
num_layers: 3
learning_rate: 0.0001
���в��������ú�Curiosityһ��,���һ�����Ե��ڵ��������num_layers��
����Curiosityһ��,�����������������ڲ�����,�������������̽����
����Ч��:��100���step�����������ܹ��ﵽƽ��1.5���ϵĽ�������Curiosity��ѵ���ٶ�Ҫ��ܶࡣ
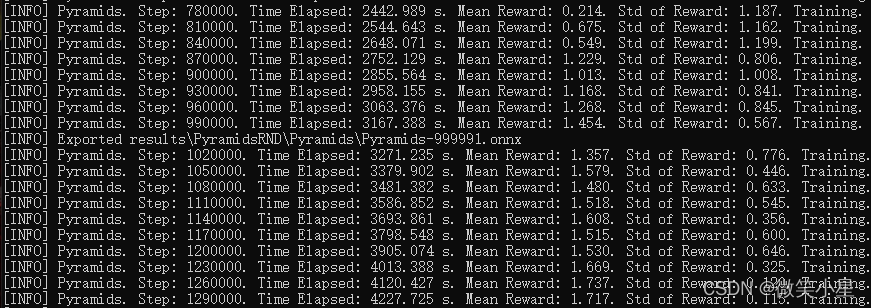
��ϸ��Ϣ��鿴:
ǿ��ѧϰ�еĺ���������ѧϰ�㷨:������羫��̽������
exploration by random network distillation
Ч����ʾ

���
����̽������ϡ�轱���Ļ�����,������ô�������������Ч��ѧϰ����,�������Dz����˹���̽���ķ���,��Ҫ�����˻��ں�����(Curiosity)�Ľ�������,�Լ����������������(Random Network Distillation)�Ľ������ơ�ML-Agents�ṩ�˱����IJ�������,ʹ�����Dz���ȥʵ����Щ���ӵ�����ṹ,�������������þ�������ʹ��������ܡ�����Ϊ���ֺ����Ľ������Ƶķ�չ����δ��ͨ���˹�����ʵ�ֵ���Ҫһ����