在写完ELMO之后呢,就是我们的主角――Bert。Bert(Bidirectional Encoder Representation from Transformers)架构呢实际上是transformer中的encoder,同样里面有很多Self-Attention和residual connection,还有normalization等等。Bert的基本模型结构由多层transformer构成,包含2个预训练任务:掩码语言模型(Mask Language Model,MLM)和?下一个句子预测(Next Sentence Prediction,NSP)

二、Bert
那Bert在做一件怎样的事情呢?Bert做的事情就是:丢一个word sequence给Bert,然后每一个word都会吐一个embedding出来给你就结束了。那至于Bert里面的架构长什么样子呢,我们在上面也提到说Bert的架构跟transformer encoder架构是一样的。那transformer encoder里面有什么东西呢?当然是self-attention layer。那self-attention layer在干什么事情呢?就是input a sequence,然后output a sequence。那现在整个Bert架构就是input word sequence,然后它output对应word的embedding。
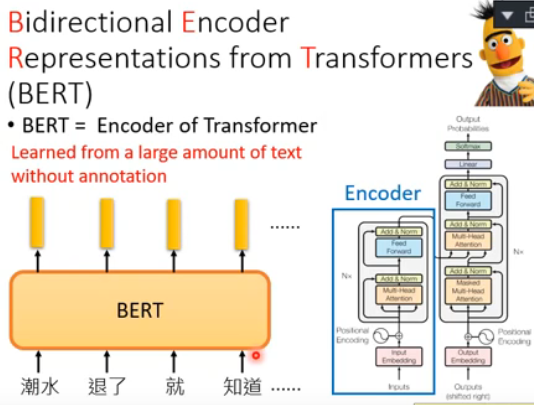
那这边呢需要声明的一个地方是:虽然上图是用词(word)来当作单位,实际上假如你要处理的是中文,也许在训练Bert的时候用字(vocabulary)来当作单位是更为恰当的。举例来说,上图中“潮水”就是中文里的一个词(?word),而“潮”跟“水”分别是中文的字(vocabulary)。如果使用中文的词(word)来当作单位的话,那我们现在input给Bert的这些token,你也要把它表示成one-hot embedding才能输给Bert这个nerve,但是词(word)是很多的,是没办法穷举的,那你input的那个词的one-hot的vector就会太长;如果使用中文的字(vocabulary)来当作单位的话,那我们知道常用的字(vocabulary)的数目是有限的,大约也就是四千多个,是能够穷举的,那你input的那个字的one-hot的vector就不会太长,这样在实操上会方便许多。
那接下来要解决的事情就是,怎么训练这个Bert呢?假设我们没有label data,只有一大堆收集的句子,那Bert这个nerve是怎么被训练出来的呢?第一个训练的方法是掩码语言模型(Mask Language Model,MLM)。Masked LM的意思是说:我们把输入Bert的句子随机有15%的词汇会被置换成一个特殊的token,这个token叫做Mask,也就是说Masked LM会随机Mask15%的词汇,那Bert要做的事情就是去猜测有盖住的地方到底是哪一个词汇,去把盖住的词汇填回来。那Bert是怎么把盖住的词汇填回来的呢?方法是:如下图,假设我们输入的句子里面呢第二个词汇是masked,把word sequence通过Bert,每一个word都会得到一个embedding。把masked这个embedding丢到一个Linear Multi-class Classifier里面,要求这个Classifier预测说现在被masked的这个词汇是哪一个词汇。因为这个Classifier是一个linear classifier所以它的能力非常非常的弱,所以今天要成功预测被masked的词汇是哪一个,那Bert这个model就要很深,比如说24层,48层等,目的是为了被masked的词汇要抽出非常好的representation。那你可以想见抽出来的representation会是怎样的representation呢?其实如果两个词汇填在同一个地方没有违和感的话,那它们就会有类似的embedding。举例来说,下图中:潮水退了就知道谁没穿裤子&潮水落了就知道谁没穿裤子,那“退了”跟“落了”填在mask处都没有违和感的话,那它们就会有比较类似的embedding
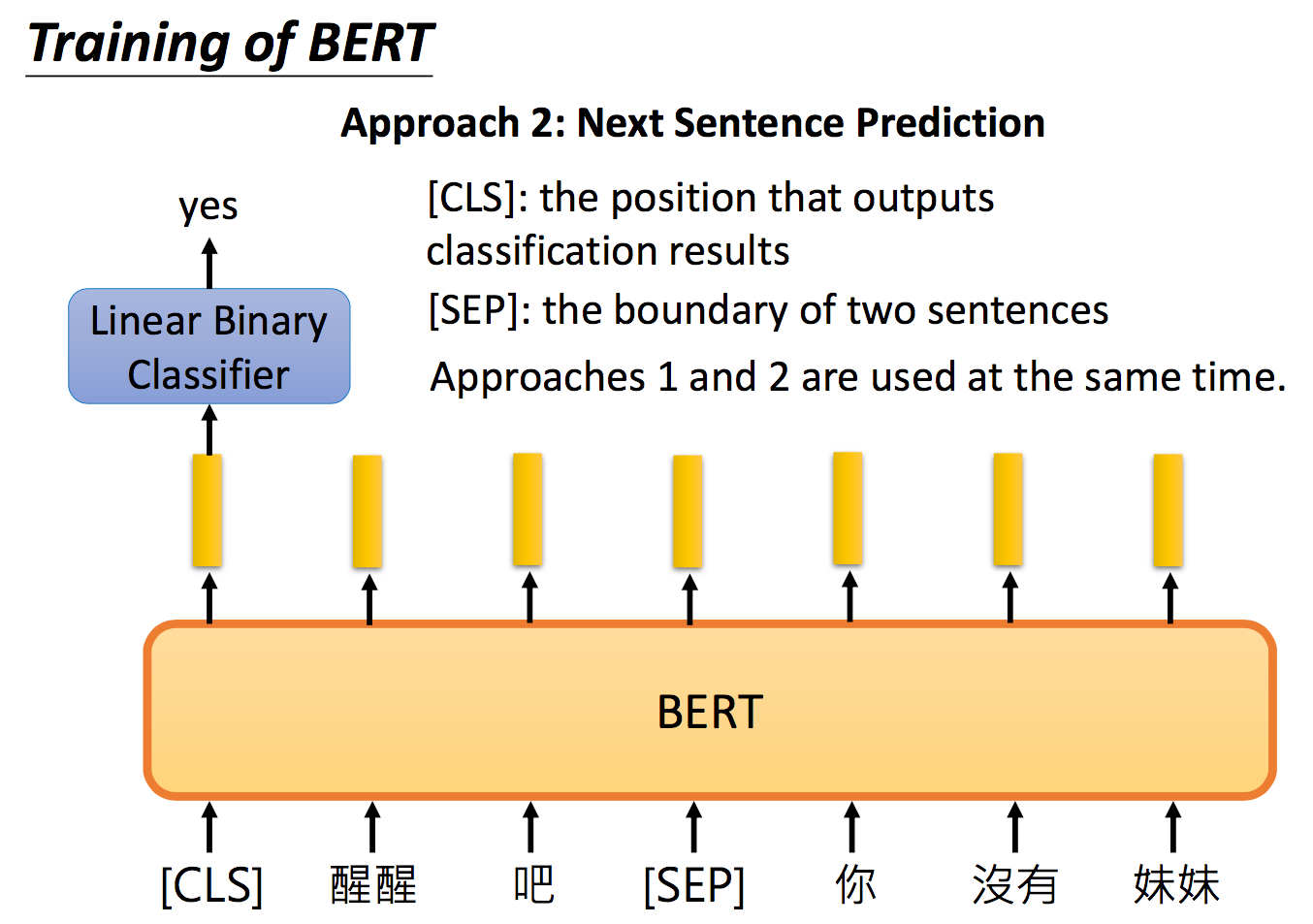
第二个训练的方法是下一个句子预测(Next Sentence Prediction,NSP)。意思是丢给Bert两个句子,Bert预测说这两个句子是接在一起的,还是断开的。举例来说,给Bert两个句子:一个是“醒醒吧”,另一个是“你没有妹妹”,你希望Bert能够准确的说这两个句子应该要被接在一起。那这边要引入一个特别的token――SEP,这个token代表两个句子间的boundary,告诉Bert说两个句子之间的交界在哪里。但是Bert怎么判断这两个句子应不应该相接的呢?那你还要给它输入一个特殊的token――CLS,这个特殊的token一般被放置在句子的开头,这个特殊的token代表说在这个位置我们要做classification分类这件事。将这个特殊的token――CLS输出的embedding,丢到Linear Binary Classifier里面,去output说输入的这两个句子是应该被接在一起还是应该分割开的。
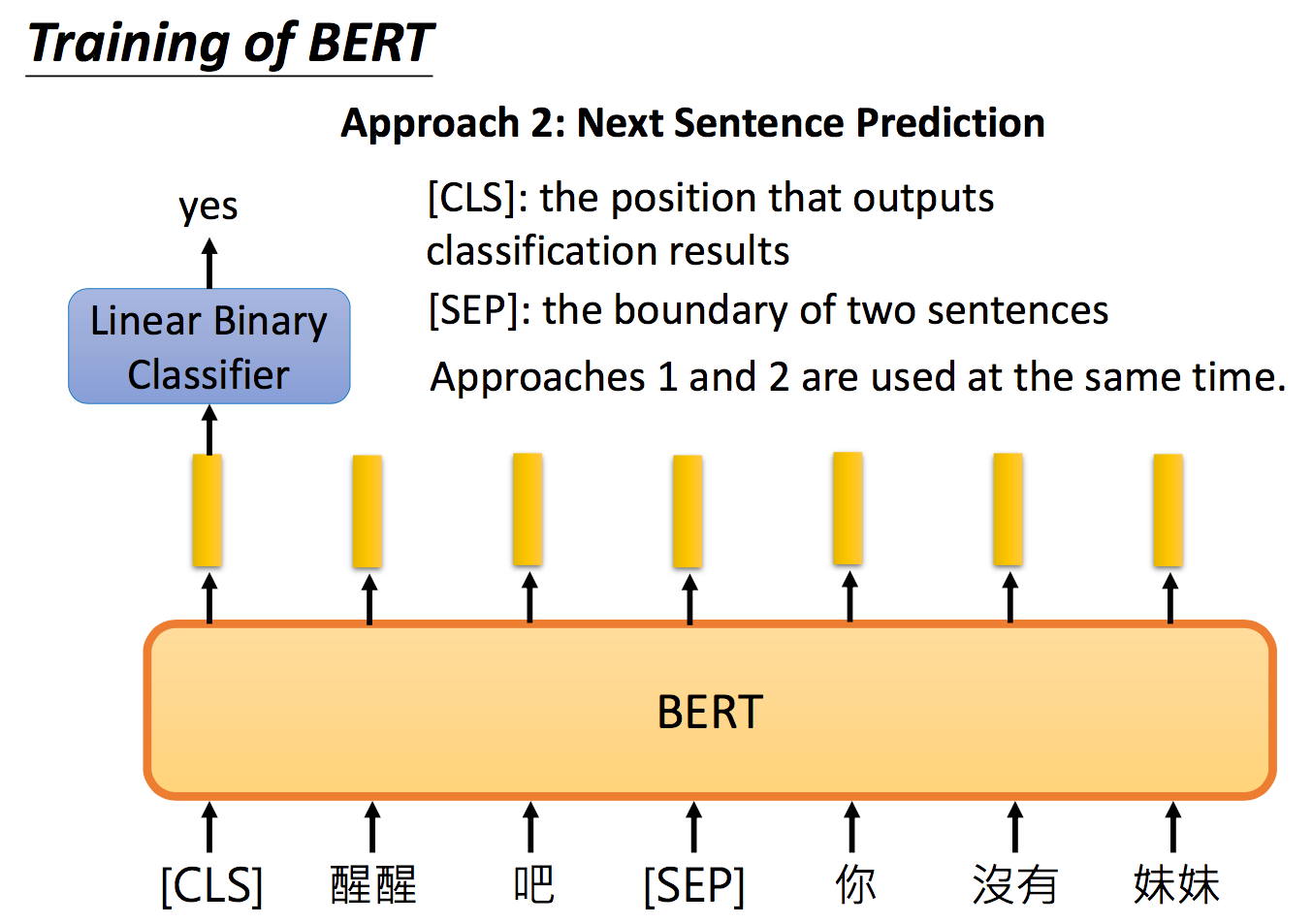
那你可能会疑惑说,为什么CLS的token一定放在句子的开头,为什么不放在句子的结尾呢?直觉上好像是先让Bert读完整个句子,才能决定这两个句子应不应该被接在一起。这不是比较合理的吗?但是你仔细想想Bert架构,如果Bert里面放的是RNN,那CLS这个token确实放在句子尾端比较合理,但是不要忘了,Bert里面放的是transformer的encoder,也就是self-attention,不是RNN!那我们有写过说self-attention有什么特色?self-attention的特色就是“天涯若比邻”――两个距离很远的word对它来说是一样的。(还记得我们有说因为这个性质要添加position embedding吗?)值得一提的是,Linear Binary Classifier和Bert是一起训练的,并且method 1和method 2一起使用效果是最好的。
那怎么使用Bert呢?一个直观的想法是把Bert的model跟你接下来要做的任务一起做训练。那这里有四种不同的例子,怎么把Bert跟接下来的downstream的任务结合在一起。第一个例子是,假设你现在要做的任务是input? a sentence,需要output一个class(分类),那要怎么做?最直接的例子就是情感分析Sentiment analysis,那什么是sentiment analysis呢?就是给机器一个句子,让它判断这个句子是正面的还是负面的。或者是文档分类Document classification,把文章分成这是体育新闻,这是娱乐新闻,这是财经新闻等等。那input? a sentence,output一个class的任务怎么使用Bert呢?你就把你现在要做分类的这个句子丢给Bert,开头的地方再加一个代表分类的token――CLS,接下来你把代表分类的符号的这个位置所output的embedding,丢给一个linear classifier,这个liner classifier去预测说input的这个sentence它的class是什么。那今天在train的时候linear classifier的参数是随机初始化的,是from scratch的;而Bert的部分是fine-tune的也就是说,Bert的参数和linear classifier的参数是一起学的,在每次class时,linear classifier的参数从头学,Bert的参数只需要微调就好了。

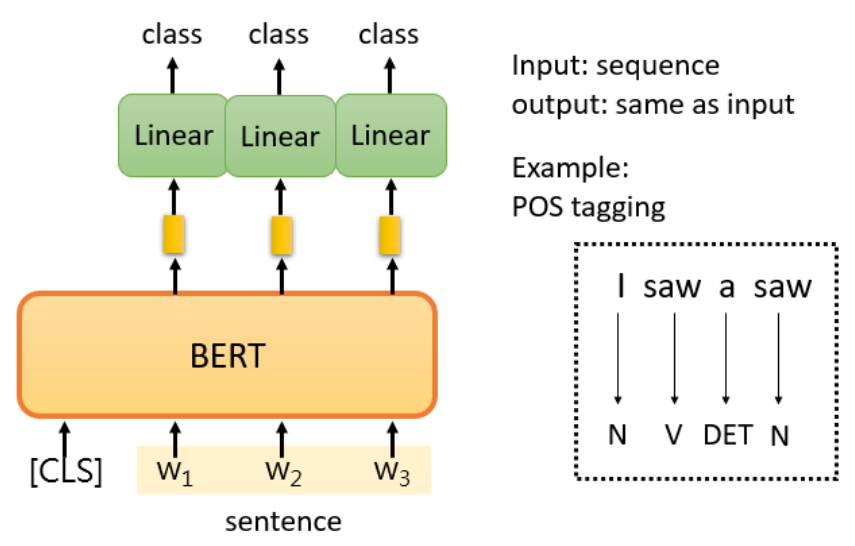
第二个例子是词性标记POS tagging。就是说你给机器一个句子,它必须告诉你这个句子中每个词的词性,即使这个词是相同的,也可能有不同的词性。那用Bert要怎么解呢?现在你input一个word sequence,那现在每个word都会output一个embedding出来,把每个embedding都丢到linear classifier里面,让这个classifier决定说这个embedding应该属于哪一种词性(实际上你可以把词性当做一个class),然后就结束了。
第三个例子是假设我们的任务是input两个句子output是一个class,那什么时候我们要input两个句子output是一个class呢?比如说有一种任务叫做Natural Language Inference。那什么是Natural Language Inference呢?就是给机器一个“前提premise”再给它一个“假设hypothesis",然后问机器说根据这个前提,这个假设到底是对还是错还是不知道。那怎么用Bert解这种Natural Language Inference的问题呢?你就把第一个句子丢给Bert,再给它一个句子间的分割的符号SEP,再把第二个句子也丢给Bert,然后在句子开头的地方呢也放一个代表句子分类的符号CLS,把CLS的embedding丢到Linear Classifier里面,然后让它决定说是True or False or don't know

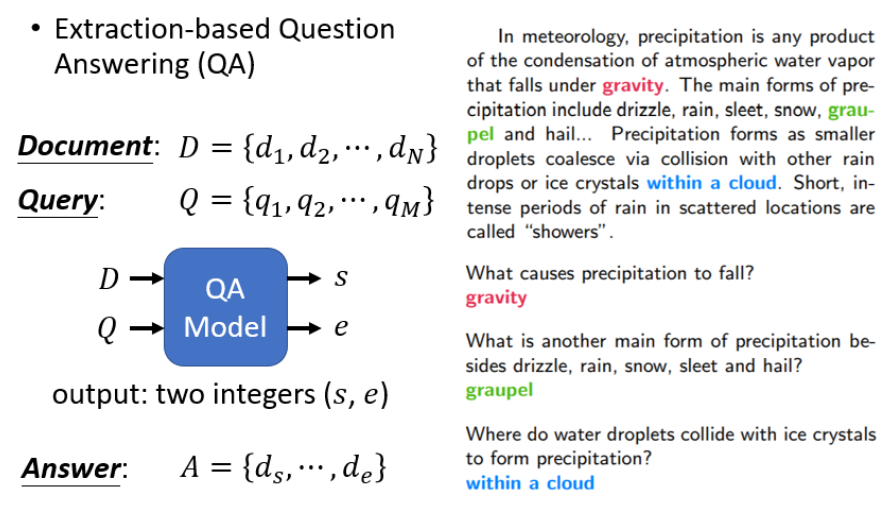
第四个例子是让Bert解Extraction-based?Question Answer的问题?。什么是Extraction-based?Question Answer的问题呢?就是说给你的model读一篇文章,然后问它一个问题,希望它可以正确的得到答案。怎么解这种Extraction-based?Question Answer的问题呢?你给Bert文章&问题,文章和问题呢都是用一个token的sequence来表示,假设现在这篇文章的D有N个token,即,文章的Query即Q呢有M个token,即
,你有一个QA的model,这个QA的model就是吃一篇文章和吃一个问题,接下来它output两个整数s和e。这两个整数是什么意思呢?意思是说现在你的答案落在第s个token到第e个token之间,也就是说你的答案是文章里面的
到
这一串token。我们以下图右边的document为例,“gravity”这个词汇在这里面是第十七个word,所以假设你问机器一个问题它要怎么输出“gravity”这个答案呢?如果它输出
,那它输出的答案就是gravity;或者说“within a cloud”在文章中是第77到第79个词汇,那你问机器一个问题如果它输出
,那它输出的答案就是within a cloud
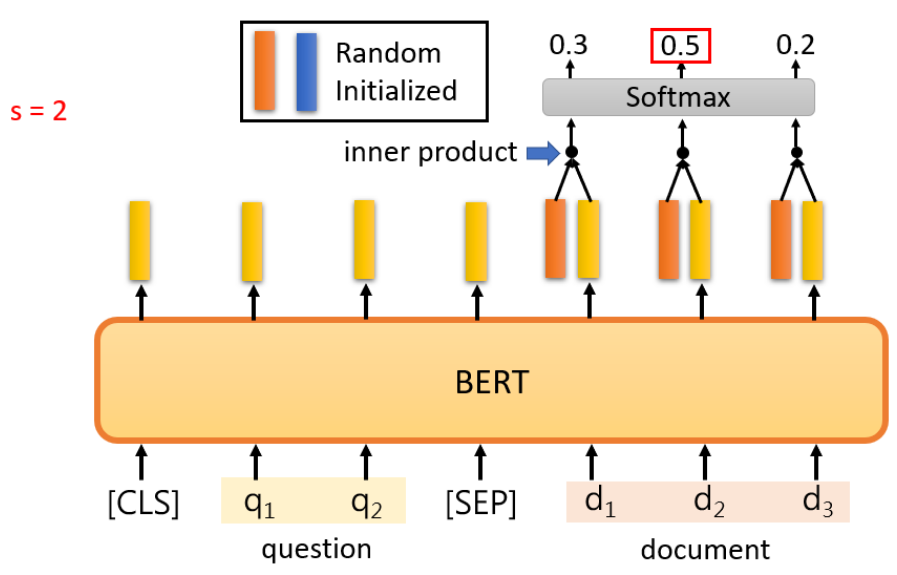
那怎么用Bert来解上面的问题呢?你就把问题输进去,然后给Bert一个分割符号SEP,再把文章输进去,那现在文章里面的词汇都会有一个embedding。接下来你让Bert去learn两外两个vector,如下图示,一个深橙色的vector一个蓝色的vector,这两个vector的dimension跟这一排浅橙色vector的dimension是一样的。那这边拿这个深橙色的vector去跟document里面每一个浅橙色的vector做dot-product以后,都会算出一个scale,把每个scale通过softmax,现在文档里面的每一个词汇都会得到一个分数,接下来看哪一个词汇得到的分数最高,比如在下图是document第二个词汇分数最高,那我们就说,所以这个深橙色的vector决定了s等于多少;那不用我说你也知道,蓝色的vector就决定的e等于多少:蓝色的vector跟document里面的每一个浅橙色的vector做dot-product以后,算出scale,把每个scale通过softmax,得到每个分数,看哪一个分数最高,比如说在下图是document第三个词汇分数最高,那
,那问题的答案就是文章中的

那这自然而然会有一个问题:如果说怎么办?是不是代表说此题无解?没有错,这就是说此题无解。还有一个方面,我们上面深橙色的vector和蓝色的vector是怎么来的?当然是学出来的。也就是说在训练的时候你要给机器很多的训练资料,给机器去学,然后希望机器看到新的文章新的问题的时候,就能告诉你说答案落在文章的哪里。实际上训练的时候Bert只需要fine-tune就好,而深橙色的vector和蓝色的vector是from scratch的