- 计算图中的矩阵
- Tensorflow的嵌入Layer
- Tensorflow的多层Layer
- Tensorflow实现损失函数
- Tensorflow实现反向传播
- Tensoflow实现随机训练和批量训练
- Tensoflow实现创建分类器
- Tensorflow实现模型评估
2.1 计算图中的矩阵
我们已经学习了Tensorflow如何创建张量,使用变量和占位符;如何将这些组件组成一个计算图呢?
- 声明一个矩阵
- 声明一个占位符
- 声明一个张量
- 将上面的张量和占位符进行运算,生成一个新的张量
- 将这个张量传入计算图,并喂数据到其中
输出
x_vals = np.array([1., 3., 5., 7., 9.])
x_data = tf.placeholder(tf.float32)
m_constant = tf.constant([3.])
my_product = tf.multiply(x_data, m_constant)
for x_val in x_vals:
print(sess.run(my_product, feed_dict={x_data: x_val}))

2.2Tensorflow中的嵌入Layer
实现一个占位符进行多层操作
- 创建一个(3,5)矩阵
- 创建一个(2, 3, 5)的矩阵
- 创建(3,5)的占位符
- 占位符和(5,1)的张量进行乘积,结果为(3,1)的张量
- 结果和(1,1)的张量进行乘积,结果为(3,1)的张量
- 结果和(1,1)的张量进行相加,结果为(3,1)的张量
- 将结果加入到计算图中并喂数据到占位符中
my_array = np.array([[1.,3.,5.,7.,9.],[2.,3.,4.,5.,6.],[1.,2.,3.,4.,5.]])
x_vals = np.array([my_array, my_array+1])
x_data = tf.placeholder(tf.float32, shape=(3,5))
m1 = tf.constant([[1.],[2.], [3.], [4.], [5.]])
m2 = tf.constant([[2.]])
a1 = tf.constant([[3.]])
prod1 = tf.matmul(x_data, m1)
prod2 = tf.matmul(prod1, m2)
prod3 = tf.add(prod2, a1)
for x_val in x_vals:
print(sess.run(prod3, feed_dict={x_data: x_val}))
2.3Tensorflow中的多层Layer
- 指定输入的数据的尺寸
- 创建均匀分布的矩阵
- 创建占位符
- 指定conv2d滑动窗口大小
- 指定滑动步长
- 创建conv2d的Layer层
- 定义运算函数
- 创建一个单独的scope_name用于分类每个单独层中的layer
- 将数据输入计算图
x_shape = [1, 4, 4, 1]
x_val = np.random.uniform(size=x_shape)
x_data = tf.placeholder(tf.float32, shape=x_shape)
my_filter = tf.constant(0.25, shape=[2,2,1,1])
my_strides = [1, 2, 2, 1]
mov_avg_layer = tf.nn.conv2d(x_data, filter=my_filter, strides=my_strides, padding='SAME', name='Moving_Avg_Layer')# shape(1,2,2,1)
def custom_layer(input_matrix):
input_matrix_squeezed = tf.squeeze(input_matrix)
A = tf.constant([[1., 2.],[-1.,3.]])
B = tf.constant(1., shape=[2, 2])
temp1 = tf.matmul(A, input_matrix_squeezed)
temp2 = tf.add(temp1, B)
return tf.sigmoid(temp2)
with tf.name_scope("Custom_Layer") as scope:
customerLayer1 = custom_layer(mov_avg_layer)
print(sess.run(customerLayer1, feed_dict={x_data:x_val}))
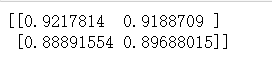
2.4Tensorflow实现损失函数
为了优化机器学习算法,我们需要评估机器学习得到的结果。在Tensorflow中评估结果依靠损失函数。
先声明预测值和目标值
x_val = tf.linspace(-1.,1.,500)# -1到1之间的500个元素等差数列
target = tf.constant(0.)# 目标值就是0
-
回归模型
-
L2正则损失函数(欧拉损失函数)。L2正则损失函数是预测值和目标值差值的平方和。他在目标值附近有更好的曲度,里目标越近收敛越慢,在tensorflow中的nn模块中内置了l2_loss函数,但是其是真这个的l2的一般,即为l2-y_vals的1/2
l2_y_vals = tf.square(target - x_vals) l2_y_out = sess.run(l2_y_vals) -
L1正则损失函数(绝对值损失函数)。不同于L2的是,L1是预测值和目标值差值的绝对值。他的优点是,在预测值和目标值相差较大时不会导致图像变得很陡峭,但是在目标值附近不平滑,使得算法不能很好地收敛
l2_y_vals = tf.square(target - x_val) l2_y_out = sess.run(l2_y_vals)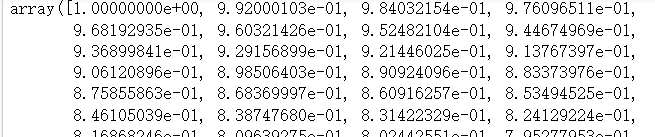
-
Pseudo-Huber损失函数时Huber损失函数的连续,平滑估计,试图利用L1和L2正则来消减极值处的陡峭,使得目标值附近连续。他的表达式依赖Δ。
针对不同的Δ会有不同的结果delta1 = tf.constant(0.25) phuber1_y_vals = tf.multiply(tf.square(delta1), tf.sqrt(1. + tf.square((target - x_vals) /delta1)) - 1.) phuber1_y_out = sess.run(phuber1_y_vals)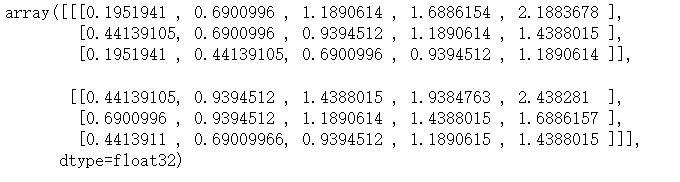
delta2 = tf.constant(5.) phuber2_y_vals = tf.multiply(tf.square(delta2), tf.sqrt(1. + tf.square((target - x_vals) /delta2)) - 1.) phuber2_y_out = sess.run(phuber2_y_vals)
-
-
分类问题的损失函数
重新给x_vals和target赋值x_val = tf.linspace(-3., 5., 500) target = tf.constant(1.) tragets = tf.fill([500,], 1)-
Hinge损失函数主要用来评估支持向量机算法,但有时也用来评估神经网络算法。
hing_y_val = tf.maximum(0., 1. - tf.multiply(target, x_val)) sess.run(hing_y_val)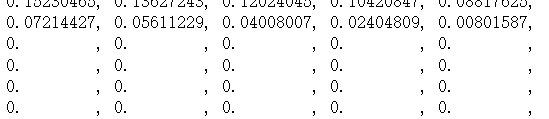
-
Cross-entropy loss 两类交叉熵损失函数,也叫逻辑损失函数。当预测两类目标0或者1时,希望度量预测值到真实分类值(0、1)的距离,这个距离经常时0到1之间的实数。
xentrop_y_vals = - tf.multiply(target, tf.log(x_val)) - tf.multiply((1. - target), tf.log(1. - x_val)) sess.run(xentrop_y_vals)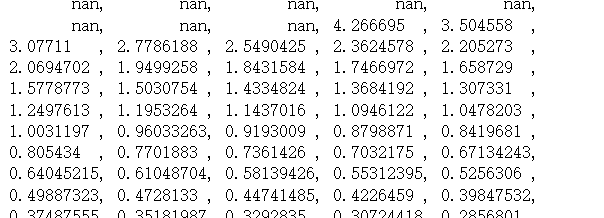
-
Sigmoid交叉熵顺势函数与上一个损失函数十分相识,有一点不同的是,他先将x_val值通过sigmoid函数转换,然后再计算交叉熵损失
xentropy_sigmoid_y_vals = tf.nn.sigmoid_cross_entropy_with_logits(logits=x_val, labels=targets) sess.run(xentropy_sigmoid_y_vals)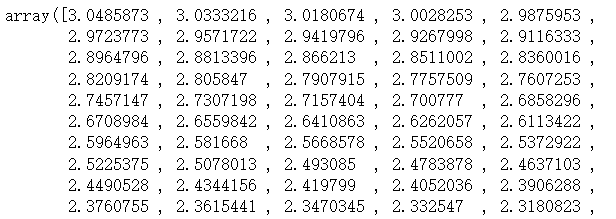
- 加权交叉熵损失函数是Sigmoid损失函数的加权,对正目标加权。
weight = tf.constant(0.5) xentropy_weight_y_vals = tf.nn.weighted_cross_entropy_with_logits(logits=x_val, targets=targets, pos_weight=weight) sess.run(xentropy_weight_y_vals)
- Softmax损失函数,作用于非归一化的输出结果,只对单个目标分类进行预测,输出值为可能的概率
例如判断一张图片是🐱或者不是
unscaled_logits = tf.constant([[1., -3., 10.]]) target_dist = tf.constant([[0.1, 0.02, 0.88]]) softmax_xentropy = tf.nn.softmax_cross_entropy_with_logits_v2(logits=unscaled_logits, labels=target_dist) sess.run(softmax_xentropy)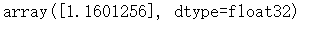
-
稀疏Softmax交叉熵损失函数,和上面一个损失函数类似,它是将目标分类为true的转化成index,而softmax交叉熵损失函数将目标转换成概率分布
unscaled_logits = tf.constant([[1., -3., 10.]]) sparse_target_dist = tf.constant([2]) sparse_xentropy = tf.nn.sparse_softmax_cross_entropy_with_logits(logits=unscaled_logits, labels=sparse_target_dist) sess.run(sparse_xentropy)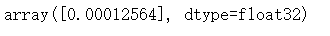
-
2.5Tensorflow实现反向传播
反向传播可以自动更新模型变量,这一步是通过声明优化函数来实现的,一旦声明好了优化函数,tensorflow将通过它解决计算图中的所有反向传播的项。当我们传入数据时,最小化损失函数,Tensorflow会根据计算图中的状态来调节变量。
举个例子:从均值为1,标准差为0.1的正态分布中抽样随机数,然后乘以变量A,目标值为10,损失函数为L2正则损失函数。理论上,A的最优解为10,因为生成的样例数据均值是1。
例子二:从正态分布N(-1,1)和N(3,1)生成100个数。所有从N(-1,1)生成的数标记为目标类0;从N(3,1)生成的数标记为目标类1;模型算法通过sigmoid函数将这些生成的数据转换成目标类数据。换句话讲就是,sigmoid(x+A),其中A是要你和的变量,理论上A=-1。假设两个正态分布的均值分别是m1和m2,则达到A的取值时,它通过-(m1+m2)/2转换到0等距的值。
-
导入numpy和tensroflow
import numpy as np import tensorflow as tf -
创建计算图会话
sess = tf.Session() -
生成数据,创建占位符和变量
x_vals = np.random.normal(1, 0.1, 100) y_vals = np.repeat(10., 100) x_data = tf.placeholder(shape=[1], dtype=tf.float32) y_target = tf.placeholder(shape=[1], dtype=tf.float32) A = tf.Variable(tf.random_normal(shape=[1])) -
增加乘法操作
my_output = tf.multriply(x_data, A) -
增加L2正则损失函数
loss = tf.square(my_output - y_target) -
声明优化器
my_optimizer = tf.train.GradientDescentOptimizer(learning_rate=0.02) train_step = my_optimizer.minimize(loss) -
初始化变量
init = tf.global_variable_initializer() sess.run(init) -
训练算法
for i in range(100): rand_index = np.random.choice(100) rand_x = [x_vals[rand_index]] rand_y = [y_vals[rand_index]] sess.run(train_step, feed_dict={x_data:rand_x, y_target:rand_y}) if (i+1) %25 ==0: print("step # " + str(i + 1) + " A = " + str(sess.run(A)) print("Loss = " + str(sess.run(loss, feed_dict={x_data: rand_x, y_target:rand_y})))输出结果

-
重置计算图,并且重新初始化变量
from tensorflow.python.framework import ops ops.reset_default_graph() sess = tf.Session() -
从正态分布(N(-1,1)和N(3,1))生成数据。同时也生成目标标签,占位符和偏差变量A
x_vals = np.concatenate((np.random.normal(-1,1,50), np.random.normal(3,1,50)) y_vals = np.concatenate((np.repeat(0.,50),np.repeat(1., 50))) x_data = tf.placeholder(shape=[1], dtype=tf.float32) y_target = tf.placeholder(shape=[1], dtype=tf.float32) A = tf.Variable(tr.random.normal(mean=10, shape[1])) -
增加转换操作
my_output = tf.add(x_data, A) -
由于指定的损失函数期望批量数据增加一个批量数的维度
my_output_expanded = tf.expand_dims(my_output, 0) y_target_expanded = tf.expand_dims(y_target, 0) -
初始化变量A
init = tf.global_variable_initializer() sess.run(init) -
声明损失函数
xentropy = tf.tarin.sigmoid_cross_entropy_with_logits(labels=y_target_expanded, logits=my_output_expanded) -
增加优化器
my_optimizer = tf.train.GrandientDescentOptimizer(0.05) train_step = my_optimizer.minimize(xentropy) -
训练算法
for i in range(1400): rand_index = np.random.choice(100) rand_x = [x_vals[rand_index]] rand_y = [y_vals[rand_index]] sess.run(train_step, feed_dict={x_data:rand_x,y_target:rand_y}) if(i+1)%200 == 0: print("Step #" + str(i+1) + " A = "+ str(sess.run(A))) print("Loss =" + str(sess.run(xentropy, feed_dict={x_data:rand_x, y_target:rand_y})))输出结果
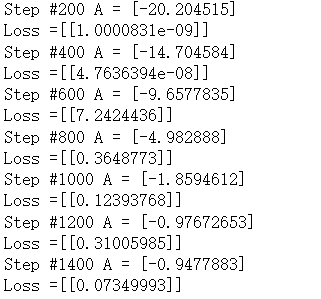
2.6Tensorflow实现批量训练和随机训练
为了Tensorflow计算变量梯度来让反向传播工作,必须度量一个或多个样本损失。与前一节所做的相似,随机训练会一次随机抽样训练数据和目标数据对完成训练。另外一个可选项是,一次大批量训练取平均损失来进行梯度计算,批量训练大小可以一次扩到整个数据集。
-
导入模块,创建会话
import numpy as np import tensorflow as tf sess = tf.Session() -
声明批量大小
batch_size = 20 -
声明数据,占位符和变量
使用None来指定占位符的尺寸为了加载到计算图中批处理数据时适应对应的批大小x_vals = np.random.normal(1, 0.1, 100) y_vals = np.repeat(10., 100) x_data = tf.placeholder(shape=[None,1], dtype=tf.float32) y_target = tf.placeholder(shape=[None, 1], dtype=tf.float32) A = tf.Variable(tf.random_normal(shape=[1,1])) -
增加矩阵操作
my_output = tf.matmul(x_data, A) -
增加损失函数
loss = tf.reduce_mean(tf.square(my_output - y_target)) -
增加优化器,初始化变量
my_optimizer = tf.train.GradientDescentOptimizer(0.02) train_step = my_optimizer.minimize(loss) init = tf.global_variables_initializer() sess.run(init) -
训练算法
loss_bacth = [] for i in range(100): rand_index = np.random.choice(100, size=batch_size) rand_x = np.transpose([x_vals[rand_index]]) rand_y = np.transpose([y_vals[rand_index]]) sess.run(train_step, feed_dict={x_data:rand_x,y_target:rand_y}) if(i+1) % 5 == 0: print("Step #" + str(i+1) + " A = "+ str(sess.run(A))) temp_loss = sess.run(loss, feed_dict={x_data:rand_x, y_target:rand_y}) print("Loss =" + str(temp_loss)) loss_bacth.append(temp_loss)
2.7Tensorflow实现创建分类器
创建一个鸢尾花数据集的分类器,实现一个简单的二值分类器来预测一朵花是否是山鸢尾。iris数据集中总共有3中鸢尾花,这里仅仅是预测是否是其中的一种
-
初始化计算图
sess = tf.Session() -
导入数据,处理数据
from sklearn import datasets iris = datasets.load_iris() binary_target = np.array([1 if x==0 else 0 for x in iris.target]) iris_2d = np.array([[x[2], x[3]] for x in iris.data]) -
声明批量训练大小,数据占位符和变量
batch_size = 20 x1_data = tf.placeholder(shape=[None, 1], dtype=tf.float32) x2_data = tf.placeholder(shape=[None, 1], dtype=tf.float32) y_target = tf.placeholder(shape=[None, 1], dtype=tf.float32) A = tf.Variable(tf.random_normal(shape=[1, 1])) B = tf.Variable(tf.random_normal(shape=[1, 1])) -
定义线性模型
my_mult = tf.multiply(x1_data, A) my_add = tf.add(my_mult, B) my_output = tf.subtract(x1_data, my_add) -
定义损失函数
xentopy = tf.nn.sigmoid_cross_entropy_with_logits(logits=my_output, labels=y_target) -
定义优化器
my_optimizer = tf.train.GradientDescentOptimizer(0.02) train_step = my_optimizer.minimize(xentopy) -
初始化变量
init = tf.global_variables_initializer() sess.run(init) -
训练算法
for i in range(1000): rand_index = np.random.choice(len(iris_2d), size=batch_size) rand_x = iris_2d[rand_index] rand_x1 = np.array([[x[0]] for x in rand_x]) rand_x2 = np.array([[x[1]] for x in rand_x]) rand_y = np.array([[y] for y in binary_target[rand_index]]) sess.run(train_step, feed_dict={x1_data: rand_x1, x2_data:rand_x2, y_target:rand_y}) if(i+1)%200==0: print("Step #" + str(i+1) + " A = " + str(sess.run(A)) + ", B = "+ str(sess.run(B)))输出结果

-
抽取模型变量并绘图
import matplotlib.pyplot as plt [slope]] = sess.run(A) [[intercept]] = sess.run(B) x = np.linspace(0, 3, num = 50) ablineValues = [] for i in x: ablineValues.append(slope*i + intercept) setosa_x = [a[1] for i,a in enumerate(iris_2d) if binary_target[i] == 1] setosa_y = [a[0] for i,a in enumerate(iris_2d) if binary_target[i] == 1] non_setosa_x = [a[1] for i,a in enumerate(iris_2d) if binary_target[i] == 0] non_setosa_y = [a[0] for i,a in enumerate(iris_2d) if binary_target[i] == 0] plt.plot(setosa_x, setosa_y, 'rx', ms=10, mew=2, label='setosa') plt.plot(non_setosa_x, non_setosa_y, 'ro', label='non-setosa') plt.xlim([0.0, 2.7]) plt.ylim([0.0, 7.1]) plt.suptitle("linear Separator For I.setosa", fontsize=20) plt.xlabel('Petal Length') plt.ylabel('Petal Width') plt.legend(loc='lower right') plt.show()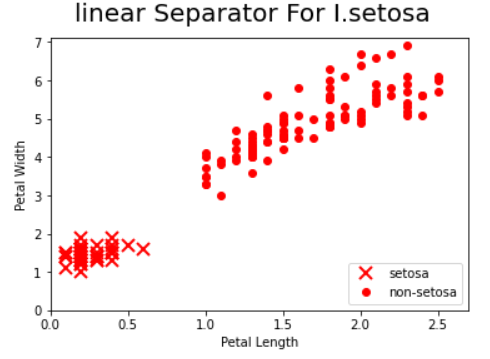
2.8 Tensorflow实现模型预估
需要预估模型的预测值来评估训练的好坏。
再Tensorflow中,需要讲过模型预估加入到计算图中,然后再模型徐连完后调用模型评估。再模型训练过程中,模型评估能洞察模型算法,给出提示信息来调试,提高或则改变整个模型。
理想条件下评估模型需要一个训练数据集和测试数据集,有时需要一个验证数据集。
- 回归算法模型是用来预测连续的数值型,其目标不是分类值,而是数字。为了评估其预测值是否与实际目标相符,需要度量两者之间的距离。
- 分类算法模型是基于数值型输入预测分类值,实际目标是1和0的序列。需要度量预测值和真实值之间的距离。
分类算法模型的损失函数一般不容易解释模型好坏,所以通常情况是看下准确预测分类的结果的百分比。
例如:将展示如何评估简单的回归算法模型,其拟合常数乘法,目标值为10.
-
加载外部库,创建计算图,数据集,变量,和占位符
import tensorflow as tf import matplotlib.pyplot as plt import numpy as np sess = tf.Session() x_vals = np.random.normal(1, 0.1,100) y_vals = np.repeat(10., 100) x_data = tf.placeholder(shape=[None, 1], dtype=tf.float32) y_target = tf.placeholder(shape=[None, 1], dtype=tf.float32) batch_size = 25 A = tf.Variable(tf.random_normal(shape=[1, 1])) -
分割数据集为训练数据集和测试数据集
train_indices = np.random.choice(len(x_vals), round(len(x_vals)*0.8), replace=False) test_indices = np.random.choice(list(set(range(len(x_vals)))-set(train_indices))) x_vals_train = x_vals[train_indices] y_vals_train = y_vals[train_indices] x_vals_test = x_vals[test_indices] y_vals_test = y_vals[test_indices] -
声明算法模型,损失函数和优化器算法
my_output = tf.matmul(x_data, A) loss = tf.reduce_mean(tf.square(my_output - y_target)) my_optimizer = tf.train.GradientDescentOptimizer(0.02) train_step = my_optimizer.minimize(loss) -
初始化变量,迭代训练模型
init = tf.global_variables_initializer() sess.run(init) for i in range(100): rand_index = np.random.choice(len(x_vals_train), size=batch_size) rand_x = np.transpose([x_vals_train[rand_index]]) rand_y = np.transpose([y_vals_train[rand_index]]) sess.run(train_step, feed_dict={x_data:rand_x, y_target:rand_y}) if (i+1) %25 ==0: print("Step #" + str(i+1) + " A = " + str(sess.run(A))) print("Loss = " + str(sess.run(loss, feed_dict={x_data:rand_x, y_target:rand_y})))输出结果:

-
评估模型(打印数据集和测试集的MSE损失函数的值)
mse_test = sess.run(loss, feed_dict={x_data: np.expand_dims([x_vals_test], axis=0), y_target: np.expand_dims([y_vals_test], axis=0)}) mse_train = sess.run(loss, feed_dict={x_data:np.transpose([x_vals_train]), y_target:np.transpose([y_vals_train])}) print("MSE on test" + str(np.round(mse_test, 2))) print("MSE on train" + str(np.round(mse_train, 2)))输出结果

-
重新加载计算图,创建数据集,变量,和占位符,分割数据集
from tensorflow.python.framework import ops ops.reset_default_graph() sess = tf.Session() batch_size = 25 v_vals = np.concatenate((np.random.normal(-1, 1, 50), np.random.normal(2, 1, 50))) y_vals = np.concatenate((np.repeat(0., 50), np.repeat(1., 50))) x_data = tf.placeholder(shape=[1, None], dtype=tf.float32) y_target = tf.placeholder(shape=[1, None], dtype=tf.float32) train_indices = np.random.choice(len(x_vals), round(len(x_vals)*0.8), replace=False) test_indices = np.array(list(set(range(len(x_vals))) - set(train_indices))) x_vals_test = x_vals[test_indices] x_vals_train = x_vals[train_indices] y_vals_test = y_vals[test_indices] y_vals_train = y_vals[train_indices] -
在新的计算图中增加模型,损失函数优化器
A = tf.Variable(tf.random_normal(mean=10, shape=[1])) my_output = tf.add(x_data, A) xentorpy = tf.reduce_mean(tf.nn.sigmoid_cross_entropy_with_logits(logits=my_output, labels=y_target)) my_optimizer =tf.train.GradientDescentOptimizer(0.02) train_step = my_optimizer.minimize(xentorpy) -
初始化变量,迭代训练模型
init = tf.global_variables_initializer() sess.run(init) for i in range(1800): rand_index = np.random.choice(len(x_vals_train), size=batch_size) rand_x = [x_vals_train[rand_index]] rand_y = [y_vals_train[rand_index]] sess.run(train_step, feed_dict={x_data:rand_x, y_target:rand_y}) if (i+1) %200 ==0: print("Step #" + str(i+1) + " A = " + str(sess.run(A))) print("Loss = " + str(sess.run(xentorpy, feed_dict={x_data:rand_x, y_target:rand_y}))) -
创建预操作
为了评估训练模型,创建预测操作,使用squeeze()函数封装预测操作,使得预测值和目标值有相同的维度。然后使用equal()函数检测是否相等。把得到的true或false的bool转换成float32类型,在取其平均值,得到一个准确值。y_prediction = tf.squeeze(tf.round(tf.nn.sigmoid(tf.add(x_data, A)))) correct_prediction = tf.equal(y_prediction, y_target) accuracy = tf.reduce_mean(tf.cast(correct_prediction, dtype=tf.float32)) acc_value_test = sess.run(accuracy, feed_dict={x_data:[x_vals_test], y_target:[y_vals_test]}) acc_value_train = sess.run(accuracy, feed_dict={x_data:[x_vals_train], y_target:[y_vals_train]}) print("Accuracy on test " + str(acc_value_test)) print("Accuracy on train "+ str(acc_value_train))
-
评估训练模型,使用matplotlib绘制出对应的图像
A_result = sess.run(A) bins = np.linspace(-5, 5, 50) plt.hist(x_vals[0:50], bins, alpha=0.5, label='N(-1, 1)', color='blue') plt.hist(x_vals[50:100], bins[0:50], alpha=0.5, label='N(2, 1)', color='red') plt.plot((A_result, A_result), (0, 8), 'k--', linewidth=3, label="A = " + str(np.round(A_result, 2))) plt.legend(loc="upper right") plt.title("Binary Classifier, Accuracy="+ str(np.round(acc_value_test, 2))) plt.show()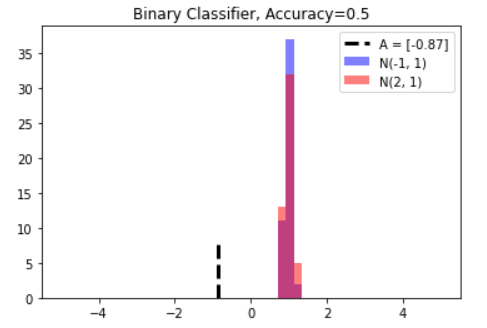
模型的结果是-0.87,理论值是0.5

