һ������
Kai Zhang��Kun Zhang��Mengdi Zhang��Hongke Zhao��Qi Liu��Wei Wu��Enhong Chen
School of Data Science, University of Science and Technology of China
School of Computer Science and Information Engineering, Hefei University of Technology
Meituan
College of Management and Economics, Tianjin University
��������
BERT�ij������������Ƕ���ǿ�����ʾ�Ĺ�ע,һЩ����BERT��ע���������Լ��䷨֪ʶ���о�Ҳȡ����һ���ijɹ�,�����ڷ�����з�����ֱ��Ӧ��ע������������Ԥѵ����BERTʱ��Ȼ����һЩ���⡣
����,��������з�����һ���ԴӾ�����ѡ�����б���Ϊ��Ҫ�ĵ��ʡ�Ȼ��,������ѧ�о�,���������еĹؼ��������������Ķ����̶���̬�仯,���Ӧ���������ǡ�
���,��ABSA�����м�ʹ��BERT���б���Ч��������������,��Ϊ�ḻ����Դʹ��BERT�������ڹ�ע�������ӵ�����,��������з�������������,ģ����Ҫ���ھֲ�������������ͬ�ķ��档
�������µ�
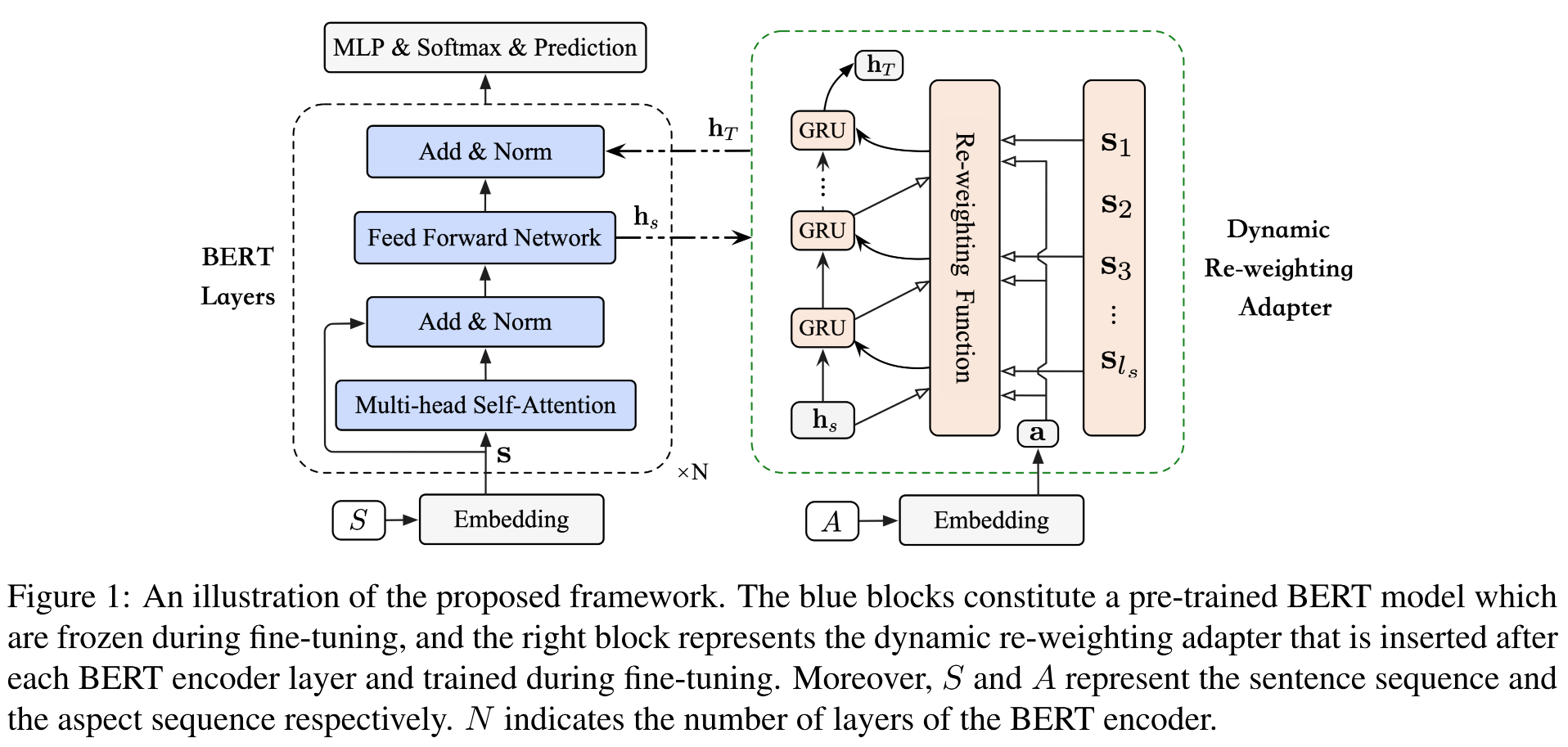
����Ϊ����ģ���ܹ����õ����ⷽ���֪��̬����(aspect-aware dynamic semantics),�����Dynamic Re-weighting BERT(DR-BERT)ģ�͡�
��ģ����������BERT��ѧϰ�������ӵ���������,Ȼ��ͨ��������������̬�ؼ�Ȩ������(DRA)���ϵ�ÿ��BERT�������㲢�������������ӦABSA����,���ж�̬�ؼ�Ȩ�������ܹ��������ע����������һ����С������,����ÿһ����̬ѡ���Ĺؼ��ʵ�Ȩ�ء�
�ġ�����ʵ��
1.Ƕ��ģ��
Ϊ�˸��õر�ʾ����ʺ������Ĵ�(context word)��������Ϣ,��������Ƕ��ģ�齫ÿ�����ʶ�ӳ��Ϊ��ά������
��������ľ������� S S S,������BERTǶ����Խ� S S Sת��Ϊ����״̬ s = { s i �O i = 1 , 2 , �� , l s } \mathbf{s} = \{\mathbf{s}_i|i = 1, 2, \dots, l_s\} s={si?�Oi=1,2,��,ls?},����Ҳ���Խ�����״̬ s \mathbf{s} s��ij�̶ֳ��Ͻ���Ϊ��ǰ���ʵ������ı�ʾ��
��������ķ������� A A A,������Ƕ��ģ����Խ� A A Aӳ��Ϊ����Ƕ�� a s = { a j �O j = 1 , 2 , �� , l a } \mathbf{a}^s = \{\mathbf{a}_j|j = 1, 2, \dots, l_a\} as={aj?�Oj=1,2,��,la?},����ijЩ����(�硰ϵͳ�洢��)�����ɶ���������,��˻�Ҫ������ a = { a 1 , l a = 1 ( �� j = 1 l a ) / l a , l a > 1 \mathbf{a} = \begin{cases} \mathbf{a}_1, l_a = 1 \\ (\sum_{j=1}^{l_a})/l_a, l_a > 1 \end{cases} a={a1?,la?=1(��j=1la??)/la?,la?>1?������Ƕ��ת��Ϊ����Ƕ�� a \mathbf{a} a��
2.BERT������
a.��ͷ��ע��������
���߲��þ���h��ͷ��MultiHead����ȡ�������ӵ���������,������� m \mathbf{m} m�ļ������Ϊ: m = { m i �O i = 1 , 2 , �� , l s } = M u l t i H e a d ( s W h Q , s W h K , s W h V ) \mathbf{m} = \{\mathbf{m}_i|i = 1, 2, \dots, l_s\} = \mathbf{MultiHead}(\mathbf{sW}_h^Q, \mathbf{sW}_h^K, \mathbf{sW}_h^V) m={mi?�Oi=1,2,��,ls?}=MultiHead(sWhQ?,sWhK?,sWhV?)��
b.λ��ǰ������
���ݾ���Self-Attention������ύ��ǰ��������,���߲��õ�FFN���������Ա任�Լ�����֮���ReLU�������,�������̿��Ա�ʾΪ: f = { f i �O i = 1 , 2 , �� , l s } = m a x ( 0 , m W 1 + b 1 ) W 2 + b 2 \mathbf{f} = \{\mathbf{f}_i|i = 1, 2, \dots, l_s\} = \mathbf{max}(0, \mathbf{mW}_1 + \mathbf{b}_1)\mathbf{W}_2 + \mathbf{b}_2 f={fi?�Oi=1,2,��,ls?}=max(0,mW1?+b1?)W2?+b2?��
�����������ز�������ƽ��ѡ������еĹؼ�����,�Ա���ÿ���ؼ�Ȩ���迪ʼʱ���ԭʼ���ӱ�ʾ h s \mathbf{h}_s hs?: h s = M a x _ P o o l i n g ( f i �O i = 1 , 2 , �� , l s ) \mathbf{h}_s = \mathrm{Max\_Pooling}(\mathbf{f}_i|i = 1, 2, \dots, l_s) hs?=Max_Pooling(fi?�Oi=1,2,��,ls?)��
3.��̬�ؼ�Ȩ������
DRA���������BERT����������� h s \mathbf{h}_s hs?����ʼ�ķ���Ƕ�� a \mathbf{a} a��
��DRA�������̵�ÿһ����,���������ؼ�Ȩע�������������� s \mathbf{s} s��Ϊ��ǰ����ѡ�ʡ�Ȼ�������ſ�ѭ����Ԫ(GRU)����ѡ�ʽ��б��벢���������ʾ��
DRA��ÿһ���Ĵ������̿��Ա�ʾΪ: a t = F ( s , h t ? 1 , a ) \mathbf{a}_t = F(\mathbf{s}, \mathbf{h}_{t-1}, \mathbf{a}) at?=F(s,ht?1?,a), h t = G R U ( a t , h t ? 1 ) \mathbf{h}_t = GRU(\mathbf{a}_t, \mathbf{h}_{t-1}) ht?=GRU(at?,ht?1?),���� F F FΪ�ؼ�Ȩ����,DRA�ij�ʼ״̬Ϊ h 0 = h s \mathbf{h}_0 = \mathbf{h}_s h0?=hs?,���� T T T�δ������õ������յ���� h T \mathbf{h}_T hT?��
����,�ؼ�Ȩ���� F F F������ע��������ʵ��,����Ŀ������ÿһ��ѡ������Ҫ�ķ�����ش�(aspect-related word)���ؼ�Ȩ���̿��Ա�ʾΪ: M = W s s + ( W d h t ? 1 + W a a ) ? w \mathbf{M} = \mathbf{W}_s\mathbf{s} + (\mathbf{W}_d\mathbf{h}_{t-1} + \mathbf{W}_a\mathbf{a}) \otimes \mathbf{w} M=Ws?s+(Wd?ht?1?+Wa?a)?w, m = �� T t a n h ( M ) \mathbf{m} = \omega^T\mathrm{tanh}(\mathbf{M}) m=��Ttanh(M), a t = �� i = 1 l s exp ? ( �� m i ) �� k = 1 l s exp ? ( �� m k ) s i \mathbf{a}_t = \displaystyle\sum_{i=1}^{l_s} \frac{\exp(\lambda m_i)}{\sum_{k=1}^{l_s}\exp(\lambda m_k)}\mathbf{s}_i at?=i=1��ls??��k=1ls??exp(��mk?)exp(��mi?)?si?,���� s \mathbf{s} s��ʾ��ʼ�ľ���Ƕ��, W s \mathbf{W}_s Ws?�� W d \mathbf{W}_d Wd?�� W a \mathbf{W}_a Wa?�� �� \omega ����Ϊ��ѵ���IJ���, m i m_i mi?Ϊ��i�����ʵ�����״̬���������� �� \lambda ��Ϊ�����ֵʱ,��ѡ�ʵ�ע�����÷����ӽ�1,�����ʵ�ע�����÷����ӽ�0,����ÿһ���ؼ�Ȩ���趼�������������ȡ��һ�����ض���������صĴ� a t \mathbf{a}_t at?��
4.����
����N���BERT��DRA�Ĵ���,���ӵij�ʼ��ʾ s \mathbf{s} s��ת��Ϊ������ʾ e N \mathbf{e}_N eN?,Ȼ�����ǽ�����������֪��(MLP)��������softmax�㽫��ӳ�䵽��ͬ��м��Եĸ��ʷֲ���,��: R l = R e l u ( W l R l ? 1 + b l ) \mathbf{R}_l = \mathrm{Relu}(\mathbf{W}_l\mathbf{R}_{l-1} + \mathbf{b}_l) Rl?=Relu(Wl?Rl?1?+bl?), y ^ = s o f t m a x ( W o R h + b o ) \hat{\mathbf{y}} = \mathrm{softmax}(\mathbf{W}_o\mathbf{R}_h + \mathbf{b}_o) y^?=softmax(Wo?Rh?+bo?),���� R l \mathbf{R}_l Rl?ΪMLPÿһ�����������״̬, R h \mathbf{R}_h Rh?��ΪMLP���ղ�����, y ^ \hat{\mathbf{y}} y^?ΪԤ�����м��Էֲ���
�塢ʵ��
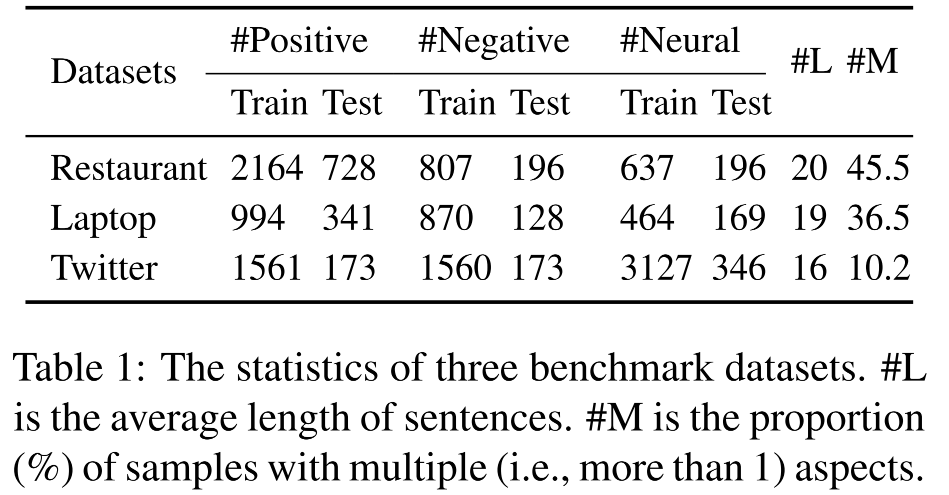
���߲�����Laptop(Pontiki et al., 2014)��Restaurant(Pontiki et al., 2014)��Twitter(Dong et al., 2014)�������ݼ���Ϊʵ�����ݼ������ݼ������������:
���߲��õĻ�ģ����Ҫ��Ϊ����ע����������ģ�ͺ�����Ԥѵ����ģ��������,��Щ���߷���ȫ�渲������������SOTAģ�͡����ߵ�ʵ����������ʾ:
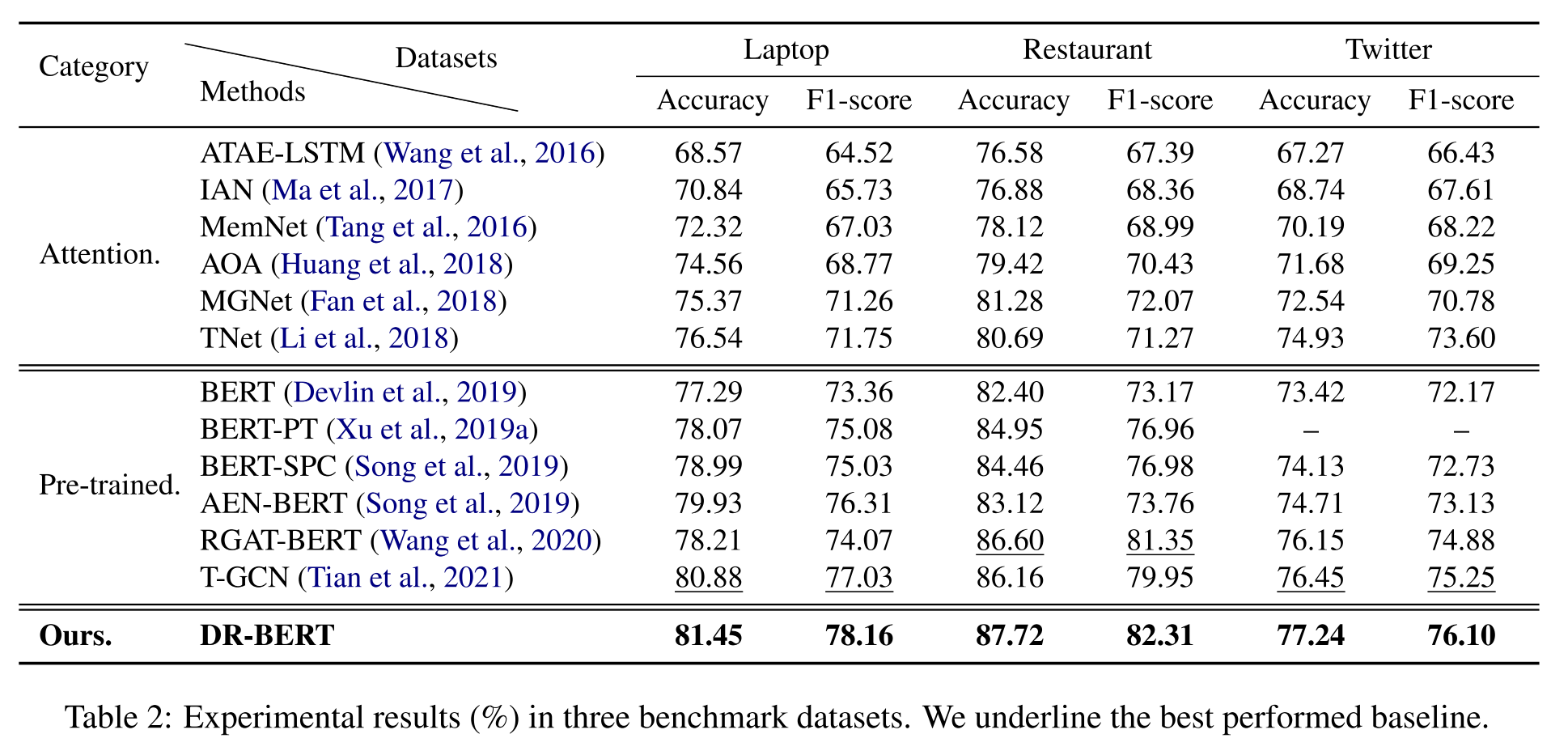
ͨ��ʵ�������Է���,����BERT�ķ�������˾�������Ļ���ע�����ķ���,�������Ҳ������Ԥѵ������ģ�͵�ǿ������������,�����ض���BERTģ�ͱ��ֵ�Ҳ�ȷ��ض���ģ����,��˵�����������Ϣ��ABSAģ�����ܵĹؼ�Ӱ�����ء���Ȼ,���ߵ�ģ��Ҳȡ������õ�Ч����
���ߵ�����ʵ������ͼ��ʾ,ͨ��������Կ���,DRA�����յ�����Ԥ���б�MLP���Ÿ���Ҫ�����á�ͬʱ,�ؼ�Ȩ������7����ʱ��ȡ����õ�Ч��,����������������伯���ڽ��߸����ʵ�����ѧ������һ�µġ�