
Ц§іЦПтБҝ»ъ
SVMКЗТ»ЦЦ¶ю·ЦАаДЈРНЎЈЛьөД»щұҫДЈРНКЗ¶ЁТеФЪМШХчҝХјдЙПөДјдёфЧоҙуөДПЯРФ·ЦАаЖч,јдёфЧоҙуК№ЛьУРұрУЪёРЦӘ»ъ;әЛјјЗЙК№ЛыіЙОӘКөЦКЙПөД·ЗПЯРФ·ЦАаЖчЎЈSVMКЗЗуҪвН№¶юҙО№ж»®өДОКМвЧоУЕ»ҜОКМвЎЈ
SVMҝЙ·ЦОӘ:
- ПЯРФҝЙ·ЦЦ§іЦПтБҝ»ъ:КэҫЭПЯРФҝЙ·Ц,НЁ№эУІјдёфЧоҙу»Ҝ,С§П°Т»ёцПЯРФ·ЦАаЖчЎЈ
- ПЯРФЦ§іЦПтБҝ»ъ:КэҫЭҪьЛЖПЯРФҝЙ·Ц,НЁ№эИнјдёфЧоҙу»Ҝ,С§П°Т»ёц·ЦАаЖчЎЈ
- ·ЗПЯРФЦ§іЦПтБҝ»ъ:КэҫЭПЯРФІ»ҝЙ·Ц,НЁ№эК№УГәЛјјЗЙј°ИнјдёфЧоҙу»ҜЎЈ
јјКх:
- SMO
- әЛәҜКэ
- РтБРЧоРЎЧоУЕ»Ҝ
КдИлҝХјдОӘЕ·КПҝХјд»тХвКЗАлЙўјҜәПЎўМШХчҝХјдКЗПЈ¶ыІ®МШҝХјд(ФЪТ»ёцКөПтБҝҝХјд»тёҙПтБҝҝХјдHЙПөДёш¶ЁөДДЪ»э < x , y > < x,y > <x,y>ҝЙТФ°ҙХХИзПВөД·ҪКҪөјіцТ»ёц·¶Кэ(norm): ЁO x ЁO = < x , y > |x|=\sqrt{<x,y>} ЁOxЁO=<x,y>?ЎЈИз№ыЖд¶ФУЪХвёц·¶КэАҙЛөКЗНкұёөД,ҙЛҝХјдіЖОӘКЗТ»ёцПЈ¶ыІ®МШҝХјд),әЛәҜКэұнКҫҪ«КдИлҙУКдіцҝХјдУіЙдөҪМШХчҝХјдөГөҪөДМШХчПтБҝЦ®јдөДДЪ»э,НЁ№эЎЈК№УГәЛәҜКэҝЙТФС§П°·ЗПЯРФЦ§іЦПтБҝ»ъ,өИјЫУЪТюКҪөДФЪёЯО¬өДМШХчҝХјдЦРС§П°ПЯРФЦ§іЦПтБҝ»ъЎЈ
Т»ЎўПЯРФҝЙ·ЦЦ§іЦПтБҝ»ъ

1. әҜКэјдёфәНјёәОјдёф

әҜКэјдёфҝЙТФұнКҫ·ЦАаФӨІвөДХэИ·РФј°И·РЕ¶ИЎЈө«КЗСЎФс·ЦАлі¬ЖҪГжКұ,Ц»УРәҜКэјдёф»№І»№»ЎЈТтОӘәҜКэјдёфёДұдКұ,і¬ЖҪГжУРҝЙДЬГ»УРёДұдЎЈЛщТФОТГЗҝЙТФ¶Ф·ЦАлі¬ЖҪГжөД·ЁПтБҝҰШјУР©ФјКш,Из№ж·¶»Ҝ,
ЁO
ЁO
ҰШ
ЁO
ЁO
=
1
||ҰШ||=1
ЁOЁOҰШЁOЁO=1,К№өГјдёфКЗИ·¶ЁөДЎЈХвКұәҜКэјдёфұдОӘјёәОјдёфЎЈ

ҙУәҜКэјдёфУлјёәОјдёфөД¶ЁТеҝЙЦӘ,әҜКэјдёфәНјёәОјдёфУРПВГжөД№ШПө:
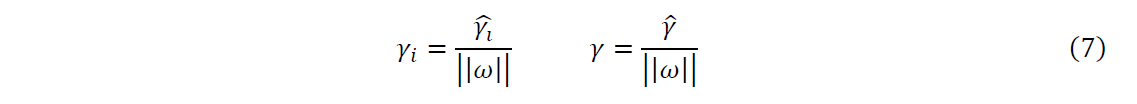
Из№ы
ЁO
ЁO
ҰШ
ЁO
ЁO
=
1
||ҰШ||=1
ЁOЁOҰШЁOЁO=1,ДЗГҙәҜКэјдёфәНјёәОјдёфПаөИЎЈИз№ыі¬ЖҪГжІОКэ
ҰШ
ҰШ
ҰШәН
b
b
bіЙұИАэөДёДұд(і¬ЖҪГжГ»УРёДұд),әҜКэјдёфТІ°ҙҙЛұИАэёДұд,¶шјёәОјдёфІ»ұдЎЈ
2. јдёфЧоҙу»Ҝ
јдёфЧоҙу»ҜөДЦұ№ЫҪвКНКЗ:¶ФСөБ·КэҫЭјҜХТөҪјёәОјдёфЧоҙуөДі¬ЖҪГжТвО¶ЧЕТФід·ЦҙуөДИ·РЕ¶И¶ФСөБ·КэҫЭјҜҪшРР·ЦАаЎЈТІҫНКЗЛө,І»ҪцҪ«ХэёәКөАэөг·ЦҝӘ,¶шЗТ¶ФЧоДС·ЦөДКөАэөг(Алі¬ЖҪГжЧоҪьөДөг)ТІУРЧг№»ҙуөДИ·РЕ¶ИҪ«ЛьГЗ·ЦҝӘЎЈХвСщөДі¬ЖҪГжУҰёГ¶ФО»ЦГөДРВКөАэУРәЬәГөД·ЦАаФӨІвДЬБҰЎЈ





def _f(self, i):
r = self.b
for j in range(self.m):
r += self.alpha[j] * self.Y[j] * self.kernel(self.X[i], self.X[j])
return r
def _KKT(self, i):
y_f = self._f(i) * self.Y[i]
if not (self.alpha[i] >0):
return False
elif not(y_f>=0):
return False
elif not(self.alpha[0]*y_f == 0):
return False
return True
KKTМхјюПкҪвЎҫөг»чјҙҝЙФД¶БЎҝ


¶юЎў ПЯРФЦ§іЦПтБҝ»ъ
ИзәОК№УГSVMҙҰАнПЯРФІ»ҝЙ·ЦОКМвДШ?ХвҫНРиТӘРЮёДУІјдёфЧоҙу»Ҝ,К№ЖдіЙОӘИнјдёфЧоҙу»ҜЎЈ
ИнјдёфөДУЕ»ҜДҝұкҝЙРҙОӘ:










ИэЎў·ЗПЯРФЦ§іЦПтБҝ»ъ
1. әЛјјЗЙ
УГПЯРФ·ЦАа·Ҫ·ЁҪвҫц·ЗПЯРФ·ЦАаОКМв·ЦОӘБҪІҪ:КЧПИКЗУГТ»ёцұд»»Ҫ«ФӯҝХјдөДКэҫЭУіЙдөҪРВҝХјд;И»әуФЪРВҝХјдАыУГПЯРФ·ЦАаС§П°·Ҫ·ЁҙУСөБ·КэҫЭЦРС§П°·ЦАаДЈРНЎЈ



2. Хэ¶ЁәЛ
І»УГ№№ФмУіЙдәҜКэ
?
(
𝑥
)
\phi(𝑥)
?(x)ДЬ·сЦұҪУЕР¶ПТ»ёцёш¶ЁөДәҜКэ
K
(
x
,
z
)
K(x,z)
K(x,z)КЗІ»КЗәЛәҜКэ? НЁіЈЛщЛөөДәЛәҜКэЦёөДКЗХэ¶ЁәЛәҜКэЎЈ

3. іЈУГәЛәҜКэ
МШХчҝХјдөДәГ»ө¶ФЦ§іЦПтБҝ»ъөДРФДЬЦБ№ШЦШТӘЎЈРиТӘЧўТвөДКЗ,ФЪІ»ЦӘөАМШХчУіЙдҝХјдөДРОКҪКұ,ОТГЗІўІ»ЦӘөАКІГҙСщөДәЛәҜКэКЗәПККөД,¶шәЛәҜКэТІҪцКЗТюКҪөД¶ЁТеБЛХвёцМШХчҝХјдЎЈУЪКЗ,Ў°әЛәҜКэСЎФсЎұіЙОӘЦ§іЦПтБҝ»ъөДЧоҙуұдКэЎЈ

def kernel_fuc(x, x2, kernel_Type):
"""
әЛәҜКэ
:param x: Ц§іЦПтБҝөДМШХч
:param x2: ДіТ»АэөДМШХч
:param kernel_Type: әЛәҜКэАаРНәНПаУҰІОКэ
:return:
"""
m, n = x.shape
K = np.mat(np.zeros((m, 1)))
if kernel_Type[0] == "line": # ПЯРФәЛ
K = x * x2.T
elif kernel_Type[0] == "radial": # ёЯЛ№әЛ
for j in range(m):
deltaRow = x[j, :] - x2
# print(deltaRow.T)
try:
K[j] = deltaRow * deltaRow.T
except:
print(deltaRow)
K = np.exp(K / (-2 * kernel_Type[1] ** 2)) # ·ө»ШЙъіЙөДҪб№ы
elif kernel_Type[0] == "Sigmoid": # SigmoidәЛ
K = np.tanh(kernel_Type[1] * x * x2.T + kernel_Type[2])
elif kernel_Type[0] == "Laplace": # АӯЖХАӯЛ№әЛ
for j in range(m):
deltaRow = x[j, :] - x2
K[j] = deltaRow * deltaRow.T
K = np.exp(K / (-1 * kernel_Type[1]))
elif kernel_Type[0] == "poly":
K = x * x2.T
K = K ** kernel_Type[1]
else:
raise NameError('Houston We Have a Problem -- That Kernel is not recognized')
return K
ЧЦ·ыҙ®әЛәҜКэ


4. ·ЗПЯРФЦ§іЦПтБҝ»ъ

ЛДЎў РтБРЧоРЎЧоУЕ»ҜЛг·Ё
өұСөБ·СщұҫИЭБҝәЬҙуКұ,ХвР©Лг·ЁНщНщұдөГ·ЗіЈөНР§,ТФЦВОЮ·ЁК№УГЎЈЛщТФ,ИзәОёЯР§өШКөПЦЦ§іЦПтБҝ»ъС§П°іЙОӘТ»ёцЦШТӘөДОКМвЎЈұҫҪЪҪІКцРтБРЧоРЎУЕ»ҜЛг·Ё(SMO)ЎЈ
SMOЛг·ЁТӘҪвИзПВН№¶юҙО№ж»®өД¶ФЕјОКМв:


1. БҪёцұдБҝ¶юҙО№ж»®өДЗуҪв·Ҫ·Ё


def calcEk(self, i):
# јЖЛгEk(ІОҝјЎ¶НіјЖС§П°·Ҫ·Ё(өЪ¶ю°ж)Ў·p145№«КҪ7.105)
# print(self.alphas)
# print(self.y)
# print(np.shape(self.alphas))
# print(np.shape(self.y))
fXk = float(np.multiply(self.alphas, self.y).T * self.Kernel[:, i] + self.b)
Ek = fXk - float(self.y[i])
return Ek

alpha2_new_unc = self.alpha[i2] + self.Y[i2] * (E1 - E2) / eta
alpha2_new = self._compare(alpha2_new_unc, L, H)
alpha1_new = self.alpha[i1] + self.Y[i1] * self.Y[i2] *(self.alpha[i2] - alpha2_new)
def _compare(self, _alpha, L, H):
if _alpha > H:
return H
elif _alpha < L:
return L
else:
return _alpha
2. ұдБҝөДСЎФс·Ҫ·Ё
SMOЛг·ЁФЪГҝёцЧУОКМвЦРСЎФсБҪёцұдБҝУЕ»Ҝ,ЖдЦРЦБЙЩТ»ёцұдБҝКЗОҘ·ҙKKTМхјюөДЎЈ



def inner(self, i):
"""
КЧПИјмСйaiКЗ·сВъЧгKKTМхјю,Из№ыІ»ВъЧг,Лж»ъСЎФсajҪшРРУЕ»Ҝ,ёьРВai,aj,bЦө
"""
Ei = self.calcEk(i)
if ((self.y[i] * Ei < -self.eps) and (self.alphas[i] < self.C)) or (
(self.y[i] * Ei > self.eps) and (self.alphas[i] > 0)):
# јмСйХвРРКэҫЭКЗ·с·ыәПKKTМхјю ІОҝјЎ¶НіјЖС§П°·Ҫ·Ё(өЪ¶ю°ж)Ў·p145№«КҪ7.111-113
# °ўО№,ХвАп·Ҫ·ЁКЗИЎБЛ·ҙөД,ҫНКЗІ»ВъЧгөД»°,ІЕҪшАҙ
j, Ej = self.selectJ(i, Ei)
alpha1old = self.alphas[i].copy()
alpha2old = self.alphas[j].copy()
# ТФПВІОҝјЎ¶НіјЖС§П°·Ҫ·Ё(өЪ¶ю°ж)Ў·p144№«КҪ
if (self.y[i] != self.y[j]):
L = max(0, self.alphas[j] - self.alphas[i])
H = min(self.C, self.C + self.alphas[j] - self.alphas[i])
else:
L = max(0, self.alphas[j] - self.alphas[j] - self.C)
H = min(self.C, self.alphas[j] + self.alphas[i])
if L == H:
print("L==H")
return 0
# ІОҝјЎ¶НіјЖС§П°·Ҫ·Ё(өЪ¶ю°ж)Ў·p145№«КҪ7.107
eta = 2.0 * self.Kernel[i, j] - self.Kernel[i, i] - self.Kernel[j, j]
if eta >= 0:
print("eta>=0")
return 0
# ІОҝјЎ¶НіјЖС§П°·Ҫ·Ё(өЪ¶ю°ж)Ў·p145№«КҪ7.106
self.alphas[j] -= self.y[j] * (Ei - Ej) / eta
# ІОҝјЎ¶НіјЖС§П°·Ҫ·Ё(өЪ¶ю°ж)Ў·p145№«КҪ7.108
self.alphas[j] = self.clipAlpha(self.alphas[j], H, L)
# ёьРВalphas[j]өД»әҙж
self.updateEk(j)
# alphaұд»ҜҙуРЎ·§Цө(ЧФјәЙи¶Ё)
if (abs(self.alphas[j] - alpha2old) < self.eps):
print("j not moving enough")
return 0
# ІОҝјЎ¶НіјЖС§П°·Ҫ·Ё(өЪ¶ю°ж)Ў·p145№«КҪ7.109
self.alphas[i] += self.y[i] * self.y[j] * (alpha2old - self.alphas[j])
# ёьРВalphas[i]өД»әҙж
self.updateEk(i)
# ЗуҪвb,ІОҝјЎ¶НіјЖС§П°·Ҫ·Ё(өЪ¶ю°ж)Ў·p148№«КҪ7.115
b1 = self.b - Ei - self.y[i] * (self.alphas[i] - alpha1old) * self.Kernel[i, i] - self.y[j] * (
self.alphas[j] - alpha2old) * self.Kernel[i, j]
# ЗуҪвb,ІОҝјЎ¶НіјЖС§П°·Ҫ·Ё(өЪ¶ю°ж)Ў·p148№«КҪ7.116
b2 = self.b - Ej - self.y[i] * (self.alphas[i] - alpha1old) * self.Kernel[i, j] - self.y[j] * (
self.alphas[j] - alpha2old) * self.Kernel[j, j]
if 0 < self.alphas[i] < self.C:
self.b = b1
elif 0 < self.alphas[j] < self.C:
self.b = b2
else:
self.b = (b1 + b2) / 2.0
return 1
else:
return 0

def SMO(self, X, y):
iter = 0 # өьҙъҙОКэ
entireSet = True # ОҙЦӘ
alphaPairsChanged = 0 # alphaөДёДұдБҝ
while (iter < self.max_iter) and ((alphaPairsChanged > 0) or entireSet):
alphaPairsChanged = 0
if entireSet:
for i in range(self.m):
alphaPairsChanged += self.inner(i)
print("ұЯҪз,өьҙъҙОКэ:%d МШХчөЪ%dРРК№өГalphaёДұд,ёДұдБЛ%d" % (iter, i, alphaPairsChanged))
iter += 1
else:
# mat.A Ҫ«ҫШХуЧӘ»»ОӘКэЧйАаРН(numpy өДnarray)
nonBoundIs = np.nonzero((self.alphas.A > 0) * (self.alphas.A < self.C))[0]
for i in nonBoundIs:
# ұйАъ·ЗұЯҪзөДКэЦө
alphaPairsChanged += self.inner(i)
print("·ЗұЯҪз,өьҙъҙОКэ:%d МШХчөЪ%dРРК№өГalphaёДұд,ёДұдБЛ%d" % (iter, i, alphaPairsChanged))
iter += 1
if entireSet:
entireSet = False
elif (alphaPairsChanged == 0):
entireSet = True
print("өұЗ°өьҙъҙОКэ:%i" % iter)
ОеЎў Ц§іЦПтБҝ»Ш№й



БщЎўҙъВл
ҙъВл1
ұҫҙъВлАҙЧФ»ъЖчС§П°іхС§ХЯ(№«ЦЪәЕ)МṩөДҙъВлЎЈ
import numpy as np
import pandas as pd
from sklearn.datasets import load_iris
from sklearn.model_selection import train_test_split
import matplotlib.pyplot as plt
# data
def create_data():
iris = load_iris()
df = pd.DataFrame(iris.data, columns=iris.feature_names)
df['label'] = iris.target
df.columns = [
'sepal length', 'sepal width', 'petal length', 'petal width', 'label'
]
data = np.array(df.iloc[:100, [0, 1, -1]])
for i in range(len(data)):
if data[i, -1] == 0:
data[i, -1] = -1
# print(data)
return data[:, :2], data[:, -1]
class SVM:
def __init__(self, max_iter=100, kernel='linear'):
self.max_iter = max_iter
self._kernel = kernel
def init_args(self, features, labels):
self.m, self.n = features.shape
self.X = features
self.Y = labels
self.b = 0.0
# Ҫ«EiұЈҙжФЪТ»ёцБРұнАп
self.alpha = np.ones(self.m)
self.E = [self._E(i) for i in range(self.m)]
# ЛЙіЪұдБҝ
self.C = 1.0
def _KKT(self, i):
y_g = self._g(i) * self.Y[i]
if self.alpha[i] == 0:
return y_g >= 1
elif 0 < self.alpha[i] < self.C:
return y_g == 1
else:
return y_g <= 1
# g(x)ФӨІвЦө,КдИлxi(X[i])
def _g(self, i):
r = self.b
for j in range(self.m):
r += self.alpha[j] * self.Y[j] * self.kernel(self.X[i], self.X[j])
return r
# әЛәҜКэ
def kernel(self, x1, x2):
if self._kernel == 'linear':
return sum([x1[k] * x2[k] for k in range(self.n)])
elif self._kernel == 'poly':
return (sum([x1[k] * x2[k] for k in range(self.n)]) + 1) ** 2
return 0
# E(x)ОӘg(x)¶ФКдИлxөДФӨІвЦөәНyөДІо
def _E(self, i):
return self._g(i) - self.Y[i]
def _init_alpha(self):
# НвІгСӯ»·КЧПИұйАъЛщУРВъЧг0<a<CөДСщұҫөг,јмСйКЗ·сВъЧгKKT
index_list = [i for i in range(self.m) if 0 < self.alpha[i] < self.C]
# ·сФтұйАъХыёцСөБ·јҜ
non_satisfy_list = [i for i in range(self.m) if i not in index_list]
index_list.extend(non_satisfy_list)
for i in index_list:
if self._KKT(i):
continue
E1 = self.E[i]
# Из№ыE2КЗ+,СЎФсЧоРЎөД;Из№ыE2КЗёәөД,СЎФсЧоҙуөД
if E1 >= 0:
j = min(range(self.m), key=lambda x: self.E[x])
else:
j = max(range(self.m), key=lambda x: self.E[x])
return i, j
def _compare(self, _alpha, L, H):
if _alpha > H:
return H
elif _alpha < L:
return L
else:
return _alpha
def fit(self, features, labels):
self.init_args(features, labels)
for t in range(self.max_iter):
# train
i1, i2 = self._init_alpha()
# ұЯҪз
if self.Y[i1] == self.Y[i2]:
L = max(0, self.alpha[i1] + self.alpha[i2] - self.C)
H = min(self.C, self.alpha[i1] + self.alpha[i2])
else:
L = max(0, self.alpha[i2] - self.alpha[i1])
H = min(self.C, self.C + self.alpha[i2] - self.alpha[i1])
E1 = self.E[i1]
E2 = self.E[i2]
# eta=K11+K22-2K12
eta = self.kernel(self.X[i1], self.X[i1]) + self.kernel(
self.X[i2],
self.X[i2]) - 2 * self.kernel(self.X[i1], self.X[i2])
if eta <= 0:
# print('eta <= 0')
continue
alpha2_new_unc = self.alpha[i2] + self.Y[i2] * (
E1 - E2) / eta # ҙЛҙҰУРРЮёД,ёщҫЭКйЙПУҰёГКЗE1 - E2,КйЙП130-131Ті
alpha2_new = self._compare(alpha2_new_unc, L, H)
alpha1_new = self.alpha[i1] + self.Y[i1] * self.Y[i2] * (
self.alpha[i2] - alpha2_new)
b1_new = -E1 - self.Y[i1] * self.kernel(self.X[i1], self.X[i1]) * (
alpha1_new - self.alpha[i1]) - self.Y[i2] * self.kernel(
self.X[i2],
self.X[i1]) * (alpha2_new - self.alpha[i2]) + self.b
b2_new = -E2 - self.Y[i1] * self.kernel(self.X[i1], self.X[i2]) * (
alpha1_new - self.alpha[i1]) - self.Y[i2] * self.kernel(
self.X[i2],
self.X[i2]) * (alpha2_new - self.alpha[i2]) + self.b
if 0 < alpha1_new < self.C:
b_new = b1_new
elif 0 < alpha2_new < self.C:
b_new = b2_new
else:
# СЎФсЦРөг
b_new = (b1_new + b2_new) / 2
# ёьРВІОКэ
self.alpha[i1] = alpha1_new
self.alpha[i2] = alpha2_new
self.b = b_new
self.E[i1] = self._E(i1)
self.E[i2] = self._E(i2)
return 'train done!'
def predict(self, data):
r = self.b
for i in range(self.m):
r += self.alpha[i] * self.Y[i] * self.kernel(data, self.X[i])
return 1 if r > 0 else -1
def score(self, X_test, y_test):
right_count = 0
for i in range(len(X_test)):
result = self.predict(X_test[i])
if result == y_test[i]:
right_count += 1
return right_count / len(X_test)
def _weight(self):
# linear model
yx = self.Y.reshape(-1, 1) * self.X
self.w = np.dot(yx.T, self.alpha)
return self.w
def PLT(self, X, y):
self.w = self._weight()
plt.scatter(X[:50, 0], X[:50, 1], label="0")
plt.scatter(X[50:, 0], X[50:, 1], label="1")
a = -self.w[0] / self.w[1]
xaxis = np.linspace(4, 8)
y_sep = a * xaxis - (self.b) / self.w[1]
plt.plot(xaxis, y_sep, 'k-')
plt.show()
if __name__ == '__main__':
X, y = create_data()
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.25)
svm = SVM(max_iter=200)
svm.fit(X_train, y_train)
print(svm.score(X_test, y_test))
svm.PLT(X, y)
ФЛРРәу,Ҫб№ыКЗХвСщ:

ХвСщ

ХвСщ

И»әуОТҫНҝӘКјұ©·зҝЮЖь,ХвКЗёцКІГҙИЛјдјІҝа,ОТөДSVMФхГҙІ»КЗSVM,әуАҙ·ўПВКЗСЎөДәЛәҜКэІ»М«әПКК,РЮёДНкәЛәҜКэҫНniceБЛ,ХвАп°іҫНІ»ёгБЛ,БфёшДгГЗИҘёг
ҙъВл2
ұҫҙъВлКЗФЪОТұ©·зҝЮЖьЦ®әу,ГжПтCSDNұаіМәуөГөҪөД,ФӯОДБҙҪУ:https://blog.csdn.net/NichChen/article/details/85329701
УРЧФјәјУөДТ»Р©ЧўКН,ҝЙКУ»ҜУРөгІ»М«»бёг,Из№ыУРҙуАР»бөД»°,ҝЙТФҪМҪМ°і,ОШОШ
import numpy as np
import matplotlib.pyplot as plt
import pandas as pd
from sklearn.datasets import load_iris
from sklearn.model_selection import train_test_split
from sklearn.svm import SVC
def loadDataSet(filename):
"""
УГУЪЧФҪЁКэҫЭјҜ,ЗТұкЗ©ОӘ-1»т1
:param filename:
:return:
"""
dataMat = []
labelMat = []
fr = open(filename)
for line in fr.readlines():
lineArr = line.strip().split()
dataMat.append([float(lineArr[0]), float(lineArr[1])])
labelMat.append(float(lineArr[2]))
return dataMat, labelMat # ·ө»ШКэҫЭМШХчәНКэҫЭАаұр
def create_data():
"""
УГУЪТСУРКэҫЭјҜ,ЗТұкЗ©ОӘ0»т1
"""
iris = load_iris()
df = pd.DataFrame(iris.data, columns=iris.feature_names)
df['label'] = iris.target
df.columns = ['sepal length', 'sepal width', 'petal length', 'petal width', 'label']
# print(df)
# print("----------------------------------------------")
data = np.array(df.iloc[:100, [0, 1, -1]])
# print(data)
# print("----------------------------------------------")
for i in range(len(data)):
if data[i, -1] == 0:
data[i, -1] = -1
# print(data)
return data[:, :2], data[:, -1]
class SVM():
def __init__(self, features, labels, eps=0.1, C=0.1, max_iter=100, kernel=['radial', 1.3]):
"""
ДЈРНІОКэіхКј»Ҝ
:param features: КэҫЭМШХч
:param labels: ұкЗ©
:param eps: НЈЦ№·§Цө
:param C: іН·ЈТтҙЛ,ТІіЖИнјдёфІОКэ
:param max_iter: ЧоҙуөьҙъҙОКэ
:param kernel: әЛәҜКэ
"""
self.X = features
self.y = labels
print(np.shape(self.y))
self.C = C
self.eps = eps
self.m = features.shape[0] # КэҫЭРРКэ
self.alphas = np.mat(np.zeros((self.m, 1)))
self.b = 0
self.eCache = np.mat(np.zeros((self.m, 2)))
self.max_iter = max_iter
self.kernel_Type = kernel
self.Kernel = np.mat(np.zeros((self.m, self.m)))
"""
Из№ыХвАпК№УГ:self.Kernel = np.zeros((self.m, self.m))
Фт»бұЁҙн:
self.Kernel[:, i] = self.kernel_fuc(self.X, self.X[i, :], self.kernel_Type)
ValueError: could not broadcast input array from shape (100,1) into shape (100)
"""
for j in range(self.m):
"""
ТтОӘМШХчXФЪСөБ·№эіМЦРКЗІ»»бұд»ҜөД,№КҝЙТФМбЗ°Лгіц
УЦТтОӘSVMФЪјЖЛгКұ,ГҝҙО¶јКЗ\sum_{i=1}^N K(x_i,x_j) ЛщТФҝЙТФЦұҪУКдИлИ«ІҝөДxУлx_jҪшРРЗуҪв
"""
self.Kernel[:, j] = self.kernel_fuc(self.X, self.X[j, :], self.kernel_Type)
@staticmethod
def kernel_fuc(x, x2, kernel_Type):
"""
әЛәҜКэ
:param x: Ц§іЦПтБҝөДМШХч
:param x2: ДіТ»АэөДМШХч
:param kernel_Type: әЛәҜКэАаРНәНПаУҰІОКэ
:return:
"""
m, n = x.shape
K = np.mat(np.zeros((m, 1)))
if kernel_Type[0] == "line": # ПЯРФәЛ
K = x * x2.T
elif kernel_Type[0] == "radial": # ёЯЛ№әЛ
for j in range(m):
deltaRow = x[j, :] - x2
# print(deltaRow.T)
try:
K[j] = deltaRow * deltaRow.T
except:
print(deltaRow)
K = np.exp(K / (-2 * kernel_Type[1] ** 2)) # ·ө»ШЙъіЙөДҪб№ы
elif kernel_Type[0] == "Sigmoid": # SigmoidәЛ
K = np.tanh(kernel_Type[1] * x * x2.T + kernel_Type[2])
elif kernel_Type[0] == "Laplace": # АӯЖХАӯЛ№әЛ
for j in range(m):
deltaRow = x[j, :] - x2
K[j] = deltaRow * deltaRow.T
K = np.exp(K / (-1 * kernel_Type[1]))
elif kernel_Type[0] == "poly":
K = x * x2.T
K = K ** kernel_Type[1]
else:
raise NameError('Houston We Have a Problem -- That Kernel is not recognized')
return K
def selectJrand(self, i):
j = i
while (j == i):
j = int(np.random.uniform(0, self.m))
return j
def selectJ(self, i, Ei):
# Лж»ъСЎИЎaj,Іў·ө»ШЖдEЦө
maxK = -1
maxDeltaE = 0
Ej = 0
self.eCache[i] = [1, Ei]
validEcacheList = np.nonzero(self.eCache[:, 0].A)[0] # ·ө»ШҫШХуЦРөД·ЗБгО»ЦГөДРРКэ
if (len(validEcacheList)) > 1:
for k in validEcacheList:
if k == i:
continue
Ek = self.calcEk(k)
deltaE = abs(Ei - Ek)
if (deltaE > maxDeltaE):
maxK, maxDeltaE, Ej = k, deltaE, Ek
return maxK, Ej
else:
j = self.selectJrand(i)
Ej = self.calcEk(j)
return j, Ej
def calcEk(self, i):
# јЖЛгEk(ІОҝјЎ¶НіјЖС§П°·Ҫ·Ё(өЪ¶ю°ж)Ў·p145№«КҪ7.105)
# print(self.alphas)
# print(self.y)
# print(np.shape(self.alphas))
# print(np.shape(self.y))
fXk = float(np.multiply(self.alphas, self.y).T * self.Kernel[:, i] + self.b)
Ek = fXk - float(self.y[i])
return Ek
def clipAlpha(self, aj, H, L):
# ІОҝјЎ¶НіјЖС§П°·Ҫ·Ё(өЪ¶ю°ж)Ў·p145№«КҪ7.108
if aj > H:
return H
if L > aj:
return L
return aj
def updateEk(self, k):
Ek = self.calcEk(k)
self.eCache[k] = [1, Ek]
def inner(self, i):
"""
КЧПИјмСйaiКЗ·сВъЧгKKTМхјю,Из№ыІ»ВъЧг,Лж»ъСЎФсajҪшРРУЕ»Ҝ,ёьРВai,aj,bЦө
"""
Ei = self.calcEk(i)
if ((self.y[i] * Ei < -self.eps) and (self.alphas[i] < self.C)) or (
(self.y[i] * Ei > self.eps) and (self.alphas[i] > 0)):
# јмСйХвРРКэҫЭКЗ·с·ыәПKKTМхјю ІОҝјЎ¶НіјЖС§П°·Ҫ·Ё(өЪ¶ю°ж)Ў·p145№«КҪ7.111-113
# °ўО№,ХвАп·Ҫ·ЁКЗИЎБЛ·ҙөД,ҫНКЗІ»ВъЧгөД»°,ІЕҪшАҙ
j, Ej = self.selectJ(i, Ei)
alpha1old = self.alphas[i].copy()
alpha2old = self.alphas[j].copy()
# ТФПВІОҝјЎ¶НіјЖС§П°·Ҫ·Ё(өЪ¶ю°ж)Ў·p144№«КҪ
if (self.y[i] != self.y[j]):
L = max(0, self.alphas[j] - self.alphas[i])
H = min(self.C, self.C + self.alphas[j] - self.alphas[i])
else:
L = max(0, self.alphas[j] - self.alphas[j] - self.C)
H = min(self.C, self.alphas[j] + self.alphas[i])
if L == H:
print("L==H")
return 0
# ІОҝјЎ¶НіјЖС§П°·Ҫ·Ё(өЪ¶ю°ж)Ў·p145№«КҪ7.107
eta = 2.0 * self.Kernel[i, j] - self.Kernel[i, i] - self.Kernel[j, j]
if eta >= 0:
print("eta>=0")
return 0
# ІОҝјЎ¶НіјЖС§П°·Ҫ·Ё(өЪ¶ю°ж)Ў·p145№«КҪ7.106
self.alphas[j] -= self.y[j] * (Ei - Ej) / eta
# ІОҝјЎ¶НіјЖС§П°·Ҫ·Ё(өЪ¶ю°ж)Ў·p145№«КҪ7.108
self.alphas[j] = self.clipAlpha(self.alphas[j], H, L)
# ёьРВalphas[j]өД»әҙж
self.updateEk(j)
# alphaұд»ҜҙуРЎ·§Цө(ЧФјәЙи¶Ё)
if (abs(self.alphas[j] - alpha2old) < self.eps):
print("j not moving enough")
return 0
# ІОҝјЎ¶НіјЖС§П°·Ҫ·Ё(өЪ¶ю°ж)Ў·p145№«КҪ7.109
self.alphas[i] += self.y[i] * self.y[j] * (alpha2old - self.alphas[j])
# ёьРВalphas[i]өД»әҙж
self.updateEk(i)
# ЗуҪвb,ІОҝјЎ¶НіјЖС§П°·Ҫ·Ё(өЪ¶ю°ж)Ў·p148№«КҪ7.115
b1 = self.b - Ei - self.y[i] * (self.alphas[i] - alpha1old) * self.Kernel[i, i] - self.y[j] * (
self.alphas[j] - alpha2old) * self.Kernel[i, j]
# ЗуҪвb,ІОҝјЎ¶НіјЖС§П°·Ҫ·Ё(өЪ¶ю°ж)Ў·p148№«КҪ7.116
b2 = self.b - Ej - self.y[i] * (self.alphas[i] - alpha1old) * self.Kernel[i, j] - self.y[j] * (
self.alphas[j] - alpha2old) * self.Kernel[j, j]
if 0 < self.alphas[i] < self.C:
self.b = b1
elif 0 < self.alphas[j] < self.C:
self.b = b2
else:
self.b = (b1 + b2) / 2.0
return 1
else:
return 0
def SMO(self, X, y):
iter = 0 # өьҙъҙОКэ
entireSet = True # ОҙЦӘ
alphaPairsChanged = 0 # alphaөДёДұдБҝ
while (iter < self.max_iter) and ((alphaPairsChanged > 0) or entireSet):
alphaPairsChanged = 0
if entireSet:
for i in range(self.m):
alphaPairsChanged += self.inner(i)
print("ұЯҪз,өьҙъҙОКэ:%d МШХчөЪ%dРРК№өГalphaёДұд,ёДұдБЛ%d" % (iter, i, alphaPairsChanged))
iter += 1
else:
# mat.A Ҫ«ҫШХуЧӘ»»ОӘКэЧйАаРН(numpy өДnarray)
nonBoundIs = np.nonzero((self.alphas.A > 0) * (self.alphas.A < self.C))[0]
for i in nonBoundIs:
# ұйАъ·ЗұЯҪзөДКэЦө
alphaPairsChanged += self.inner(i)
print("·ЗұЯҪз,өьҙъҙОКэ:%d МШХчөЪ%dРРК№өГalphaёДұд,ёДұдБЛ%d" % (iter, i, alphaPairsChanged))
iter += 1
if entireSet:
entireSet = False
elif (alphaPairsChanged == 0):
entireSet = True
print("өұЗ°өьҙъҙОКэ:%i" % iter)
def fit(self, X, y):
self.SMO(X, y) # НЁ№эSMOЛг·ЁөГөҪbәНalpha
self.svInd = np.nonzero(self.alphas)[0] # СЎИЎІ»ОӘ0КэҫЭөДРРКэ(ТІҫНКЗЦ§іЦПтБҝ)
self.sVs = X[self.svInd] # Ц§іЦПтБҝөДМШХчКэҫЭ
self.ySv = y[self.svInd] # Ц§іЦПтБҝөДАаұр(1»т-1)
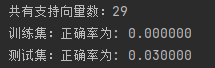
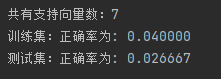
print("№ІУРЦ§іЦПтБҝКэ:%d" % np.shape(self.sVs)[0]) # ҙтУЎіц№ІУР¶аЙЩөДЦ§іЦПтБҝ
print("СөБ·јҜ:", end="")
self.score(X, y)
def score(self, X, y):
errcnt = 0
for i in range(len(X)):
# Ҫ«Ц§іЦПтБҝЧӘ»ҜОӘәЛәҜКэ
try:
kernelEval = self.kernel_fuc(self.sVs, X[i, :], self.kernel_Type)
predict = kernelEval.T * np.multiply(self.ySv, self.alphas[self.svInd]) + self.b
if np.sign(predict) != np.sign(y[i]):
# signәҜКэ -1 if x < 0, 0 if x==0, 1 if x > 0
errcnt += 1
except:
print("self.sVs=", self.sVs)
print("i:=", i)
print("X.shape()=", X.shape)
print("self.kernerl_Type=", self.kernel_Type)
print("ХэИ·ВКОӘ: %f" % (float(errcnt) / self.m)) # ҙтУЎіцҙнОуВК
def _weight(self):
# linear model
print(self.y)
print(X)
yx = self.y.reshape(-1, 1) * self.X
self.w = np.dot(yx.T, self.alphas)
return self.w
def PLT(self, X, y):
self.w = self._weight()
plt.scatter(X[:50, 0], X[:50, 1], label="0")
plt.scatter(X[50:, 0], X[50:, 1], label="1")
a = -self.w[0] / self.w[1]
xaxis = np.linspace(4, 8)
y_sep = a * xaxis - (self.b) / self.w[1]
plt.plot(xaxis, y_sep, 'k-')
plt.show()
if __name__ == '__main__':
filename_traindata = "D:/python/meaching learning/Ц§іЦПтБҝ»ъ/train.txt"
filename_testdata = "D:/python/meaching learning/Ц§іЦПтБҝ»ъ/test.txt"
X_train, y_train = loadDataSet(filename_traindata)
X_test, y_test = loadDataSet(filename_testdata)
# X, y = create_data()
# X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.25)
X_train = np.mat(X_train)
y_train = np.mat(y_train).transpose()
X_test = np.mat(X_test)
y_test = np.mat(y_test).transpose()
print(np.shape(y_train))
svm = SVM(features=X_train, labels=y_train, C=200, eps=0.0001, max_iter=10000, kernel=['radial', 1.3])
print(np.shape(svm.y))
svm.fit(X_train, y_train)
print("ІвКФјҜ:", end="")
svm.score(X_test, y_test)
X = np.array(np.vstack((X_train, X_test)))
y = np.array(np.vstack((y_train, y_test)))
# svm.PLT(X, y)
ЧФҙшКэҫЭјҜ(КэҫЭјҜФЪәуГж):
р°ОІ»ЁКэҫЭјҜ:
КэҫЭјҜ:
train.txt
-0.214824 0.662756 -1.000000
-0.061569 -0.091875 1.000000
0.406933 0.648055 -1.000000
0.223650 0.130142 1.000000
0.231317 0.766906 -1.000000
-0.748800 -0.531637 -1.000000
-0.557789 0.375797 -1.000000
0.207123 -0.019463 1.000000
0.286462 0.719470 -1.000000
0.195300 -0.179039 1.000000
-0.152696 -0.153030 1.000000
0.384471 0.653336 -1.000000
-0.117280 -0.153217 1.000000
-0.238076 0.000583 1.000000
-0.413576 0.145681 1.000000
0.490767 -0.680029 -1.000000
0.199894 -0.199381 1.000000
-0.356048 0.537960 -1.000000
-0.392868 -0.125261 1.000000
0.353588 -0.070617 1.000000
0.020984 0.925720 -1.000000
-0.475167 -0.346247 -1.000000
0.074952 0.042783 1.000000
0.394164 -0.058217 1.000000
0.663418 0.436525 -1.000000
0.402158 0.577744 -1.000000
-0.449349 -0.038074 1.000000
0.619080 -0.088188 -1.000000
0.268066 -0.071621 1.000000
-0.015165 0.359326 1.000000
0.539368 -0.374972 -1.000000
-0.319153 0.629673 -1.000000
0.694424 0.641180 -1.000000
0.079522 0.193198 1.000000
0.253289 -0.285861 1.000000
-0.035558 -0.010086 1.000000
-0.403483 0.474466 -1.000000
-0.034312 0.995685 -1.000000
-0.590657 0.438051 -1.000000
-0.098871 -0.023953 1.000000
-0.250001 0.141621 1.000000
-0.012998 0.525985 -1.000000
0.153738 0.491531 -1.000000
0.388215 -0.656567 -1.000000
0.049008 0.013499 1.000000
0.068286 0.392741 1.000000
0.747800 -0.066630 -1.000000
0.004621 -0.042932 1.000000
-0.701600 0.190983 -1.000000
0.055413 -0.024380 1.000000
0.035398 -0.333682 1.000000
0.211795 0.024689 1.000000
-0.045677 0.172907 1.000000
0.595222 0.209570 -1.000000
0.229465 0.250409 1.000000
-0.089293 0.068198 1.000000
0.384300 -0.176570 1.000000
0.834912 -0.110321 -1.000000
-0.307768 0.503038 -1.000000
-0.777063 -0.348066 -1.000000
0.017390 0.152441 1.000000
-0.293382 -0.139778 1.000000
-0.203272 0.286855 1.000000
0.957812 -0.152444 -1.000000
0.004609 -0.070617 1.000000
-0.755431 0.096711 -1.000000
-0.526487 0.547282 -1.000000
-0.246873 0.833713 -1.000000
0.185639 -0.066162 1.000000
0.851934 0.456603 -1.000000
-0.827912 0.117122 -1.000000
0.233512 -0.106274 1.000000
0.583671 -0.709033 -1.000000
-0.487023 0.625140 -1.000000
-0.448939 0.176725 1.000000
0.155907 -0.166371 1.000000
0.334204 0.381237 -1.000000
0.081536 -0.106212 1.000000
0.227222 0.527437 -1.000000
0.759290 0.330720 -1.000000
0.204177 -0.023516 1.000000
0.577939 0.403784 -1.000000
-0.568534 0.442948 -1.000000
-0.011520 0.021165 1.000000
0.875720 0.422476 -1.000000
0.297885 -0.632874 -1.000000
-0.015821 0.031226 1.000000
0.541359 -0.205969 -1.000000
-0.689946 -0.508674 -1.000000
-0.343049 0.841653 -1.000000
0.523902 -0.436156 -1.000000
0.249281 -0.711840 -1.000000
0.193449 0.574598 -1.000000
-0.257542 -0.753885 -1.000000
-0.021605 0.158080 1.000000
0.601559 -0.727041 -1.000000
-0.791603 0.095651 -1.000000
-0.908298 -0.053376 -1.000000
0.122020 0.850966 -1.000000
-0.725568 -0.292022 -1.000000
test.txt
0.676771 -0.486687 -1.000000
0.008473 0.186070 1.000000
-0.727789 0.594062 -1.000000
0.112367 0.287852 1.000000
0.383633 -0.038068 1.000000
-0.927138 -0.032633 -1.000000
-0.842803 -0.423115 -1.000000
-0.003677 -0.367338 1.000000
0.443211 -0.698469 -1.000000
-0.473835 0.005233 1.000000
0.616741 0.590841 -1.000000
0.557463 -0.373461 -1.000000
-0.498535 -0.223231 -1.000000
-0.246744 0.276413 1.000000
-0.761980 -0.244188 -1.000000
0.641594 -0.479861 -1.000000
-0.659140 0.529830 -1.000000
-0.054873 -0.238900 1.000000
-0.089644 -0.244683 1.000000
-0.431576 -0.481538 -1.000000
-0.099535 0.728679 -1.000000
-0.188428 0.156443 1.000000
0.267051 0.318101 1.000000
0.222114 -0.528887 -1.000000
0.030369 0.113317 1.000000
0.392321 0.026089 1.000000
0.298871 -0.915427 -1.000000
-0.034581 -0.133887 1.000000
0.405956 0.206980 1.000000
0.144902 -0.605762 -1.000000
0.274362 -0.401338 1.000000
0.397998 -0.780144 -1.000000
0.037863 0.155137 1.000000
-0.010363 -0.004170 1.000000
0.506519 0.486619 -1.000000
0.000082 -0.020625 1.000000
0.057761 -0.155140 1.000000
0.027748 -0.553763 -1.000000
-0.413363 -0.746830 -1.000000
0.081500 -0.014264 1.000000
0.047137 -0.491271 1.000000
-0.267459 0.024770 1.000000
-0.148288 -0.532471 -1.000000
-0.225559 -0.201622 1.000000
0.772360 -0.518986 -1.000000
-0.440670 0.688739 -1.000000
0.329064 -0.095349 1.000000
0.970170 -0.010671 -1.000000
-0.689447 -0.318722 -1.000000
-0.465493 -0.227468 -1.000000
-0.049370 0.405711 1.000000
-0.166117 0.274807 1.000000
0.054483 0.012643 1.000000
0.021389 0.076125 1.000000
-0.104404 -0.914042 -1.000000
0.294487 0.440886 -1.000000
0.107915 -0.493703 -1.000000
0.076311 0.438860 1.000000
0.370593 -0.728737 -1.000000
0.409890 0.306851 -1.000000
0.285445 0.474399 -1.000000
-0.870134 -0.161685 -1.000000
-0.654144 -0.675129 -1.000000
0.285278 -0.767310 -1.000000
0.049548 -0.000907 1.000000
0.030014 -0.093265 1.000000
-0.128859 0.278865 1.000000
0.307463 0.085667 1.000000
0.023440 0.298638 1.000000
0.053920 0.235344 1.000000
0.059675 0.533339 -1.000000
0.817125 0.016536 -1.000000
-0.108771 0.477254 1.000000
-0.118106 0.017284 1.000000
0.288339 0.195457 1.000000
0.567309 -0.200203 -1.000000
-0.202446 0.409387 1.000000
-0.330769 -0.240797 1.000000
-0.422377 0.480683 -1.000000
-0.295269 0.326017 1.000000
0.261132 0.046478 1.000000
-0.492244 -0.319998 -1.000000
-0.384419 0.099170 1.000000
0.101882 -0.781145 -1.000000
0.234592 -0.383446 1.000000
-0.020478 -0.901833 -1.000000
0.328449 0.186633 1.000000
-0.150059 -0.409158 1.000000
-0.155876 -0.843413 -1.000000
-0.098134 -0.136786 1.000000
0.110575 -0.197205 1.000000
0.219021 0.054347 1.000000
0.030152 0.251682 1.000000
0.033447 -0.122824 1.000000
-0.686225 -0.020779 -1.000000
-0.911211 -0.262011 -1.000000
0.572557 0.377526 -1.000000
-0.073647 -0.519163 -1.000000
-0.281830 -0.797236 -1.000000
-0.555263 0.126232 -1.000000
Pdf°ж:
БҙҪУ:https://pan.baidu.com/s/1dzNouQBkdRja9rgWWoQV0g
МбИЎВл:RRTX